Konfigurowanie wysokiej dostępności i odzyskiwania po awarii
Główna część konfigurowania odzyskiwania po awarii i rozwiązań o wysokiej dostępności w programie SQL Server pozostaje taka sama w programie SQL Server uruchomionym na maszynie wirtualnej platformy Azure. Rozwiązanie o wysokiej dostępności ma zagwarantować, że żadne zatwierdzone dane nie zostaną utracone z powodu awarii, że obciążenie pozostanie bez wpływu na operacje konserwacji i że baza danych nie stanie się pojedynczym punktem awarii w architekturze oprogramowania.
Większość warstw usług Azure SQL oferuje szereg opcji wysokiej dostępności— od lokalnej nadmiarowości po modele nadmiarowości strefowej.
Następnie zapoznamy się z konkretnymi rozwiązaniami dotyczącymi odzyskiwania po awarii i wysokiej dostępności ofert PaaS platformy Azure.
Ciągła kopia zapasowa
Usługa Azure SQL Database zapewnia regularne i ciągłe kopie zapasowe baz danych, które są następnie replikowane do magazynu geograficznie nadmiarowego dostępnego do odczytu (RA-GRS).
Cotygodniowe pełne kopie zapasowe, różnicowe kopie zapasowe co 12 do 24 godzin, a kopie zapasowe dziennika transakcji co 5 do 10 minut są częścią strategii automatycznej kopii zapasowej. W przypadku rozszerzonej dostępności kopii zapasowych (do 10 lat) można skonfigurować przechowywanie długoterminowe (LTR) zarówno dla pojedynczych baz danych, jak i baz danych w puli.
Przechowywanie długoterminowe (LTR)
Platforma Azure oferuje zasady przechowywania, które można ustawić poza zwykłymi limitami, co jest przydatne w scenariuszach wymagających długoterminowego przechowywania. Można ustawić zasady przechowywania przez maksymalnie 10 lat, a ta opcja jest domyślnie wyłączona.

Na obrazie przedstawiono sposób konfigurowania zasad przechowywania długoterminowego w witrynie Azure Portal. Po wybraniu bazy danych zostanie wyświetlony panel po prawej stronie ekranu, w którym można zmienić ustawienia domyślne.
Aby uzyskać więcej informacji na temat długoterminowego przechowywania, zobacz Długoterminowe przechowywanie — Azure SQL Database i Azure SQL Managed Instance.
Przywracanie geograficzne
Kopie zapasowe dla usług SQL Database i SQL Managed Instance są domyślnie geograficznie nadmiarowe. Dzięki temu można łatwo przywrócić bazy danych do innego regionu geograficznego— funkcję, która jest przydatna w przypadku mniej rygorystycznych scenariuszy odzyskiwania po awarii.
Magazyn kopii zapasowych jest rozliczany poza zwykłym magazynem plików bazy danych. Jednak podczas aprowizacji usługi SQL Database magazyn kopii zapasowych jest tworzony z maksymalnym rozmiarem warstwy danych wybranej dla bazy danych bez dodatkowych kosztów.
Czas trwania operacji przywracania geograficznego może mieć wpływ na kilka podstawowych składników, w tym rozmiar bazy danych, liczbę dzienników transakcji zaangażowanych w operację przywracania oraz liczbę równoczesnych żądań przywracania przetwarzanych w regionie docelowym.
Przywracanie do punktu w czasie (PITR)
Bazy danych można przywrócić do określonego punktu w czasie zgodnie ze zdefiniowanym przechowywaniem, ale usługa PITR jest obsługiwana tylko wtedy, gdy przywracasz bazę danych na tym samym serwerze, z którego pochodzi kopia zapasowa. Aby przywrócić bazę danych SQL Database, możesz użyć witryny Azure Portal, programu Azure PowerShell, interfejsu wiersza polecenia platformy Azure lub interfejsu API REST.
Aktywna replikacja geograficzna
Jedną z metod zwiększania dostępności usługi Azure SQL Database jest użycie aktywnej replikacji geograficznej. Aktywna replikacja geograficzna tworzy pomocniczą replikę bazy danych w innym regionie, który jest asynchronicznie aktualizowany.
Ta replika jest czytelna, podobnie jak w przypadku zawsze włączonej grupy dostępności w programie SQL Server. Pod powierzchnią platforma Azure używa grup dostępności do obsługi tej funkcji, dlatego niektóre terminologie są podobne.
Aktywna replikacja geograficzna zapewnia ciągłość działania, umożliwiając klientom programowe lub ręczne przełączenie podstawowych baz danych w tryb failover do regionów pomocniczych podczas poważnej awarii.
Uwaga
Usługa Azure SQL Managed Instance nie obsługuje aktywnej replikacji geograficznej. Zamiast tego należy użyć grup automatycznego trybu failover— temat, który omówimy w dalszej części tej lekcji.
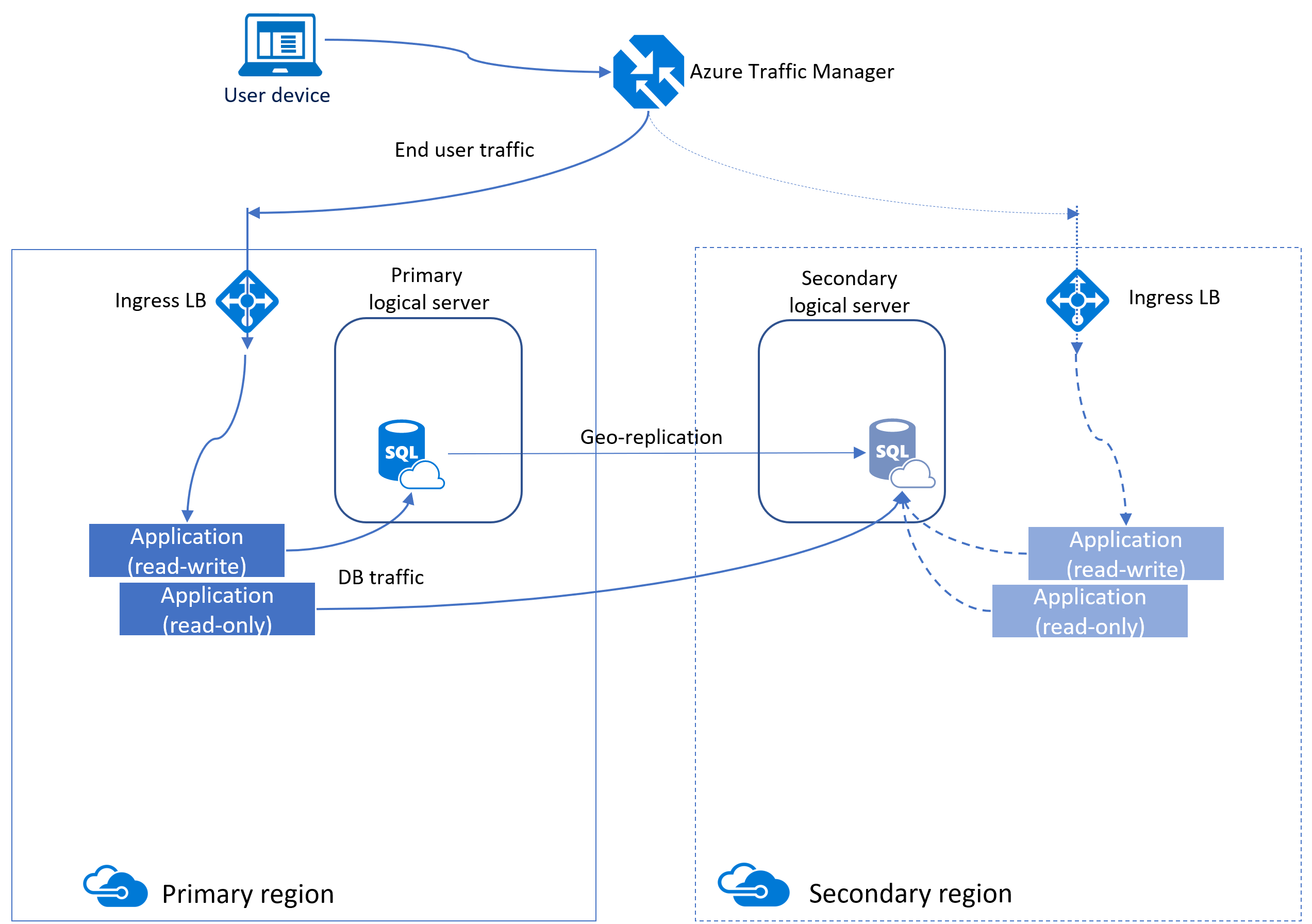
Wszystkie bazy danych biorące udział w relacji replikacji geograficznej muszą mieć tę samą warstwę usługi. Ponadto, aby zapobiec problemom z wydajnością replikacji z powodu dużego obciążenia zapisu, zalecamy skonfigurowanie repliki pomocniczej z tym samym rozmiarem obliczeniowym co podstawowy.

Replikację geograficzną dla usługi Azure SQL Database można skonfigurować ręcznie, korzystając z bloku bazy danych w sekcji Zarządzanie danymi, wybierając pozycję Repliki, a następnie pozycję + Utwórz replikę.

Po ustanowieniu repliki pomocniczej można ręcznie zainicjować tryb failover. W tym procesie role są odwrócone — replika pomocnicza przyjmuje rolę podstawową, a oryginalna podstawowa staje się pomocnicza.
Replikacja geograficzna między subskrypcjami
W niektórych scenariuszach może być konieczne skonfigurowanie repliki pomocniczej w innej subskrypcji niż podstawowa baza danych. W tym miejscu jest dostępna funkcja replikacji geograficznej między subskrypcjami.
Uwaga
Replikacja geograficzna między subskrypcjami jest dostępna tylko programowo.
Aby dowiedzieć się więcej na temat kroków wymaganych do skonfigurowania replikacji geograficznej między subskrypcjami, zobacz Replikacja geograficzna między subskrypcjami.
Grupy automatycznego trybu failover
Grupa automatycznego trybu failover to funkcja wysokiej dostępności obsługiwana zarówno przez usługę Azure SQL Database, jak i usługę Azure SQL Managed Instance. Grupy automatycznego trybu failover umożliwiają zarządzanie replikacją baz danych do innego regionu oraz sposobem przejścia w tryb failover. Nazwa przypisana do grupy automatycznego trybu failover musi być unikatowa w domenie *.database.windows.net .
Grupa automatycznego trybu failover może zawierać wiele baz danych. Zarówno podstawowy, jak i pomocniczy mają ten sam rozmiar bazy danych.
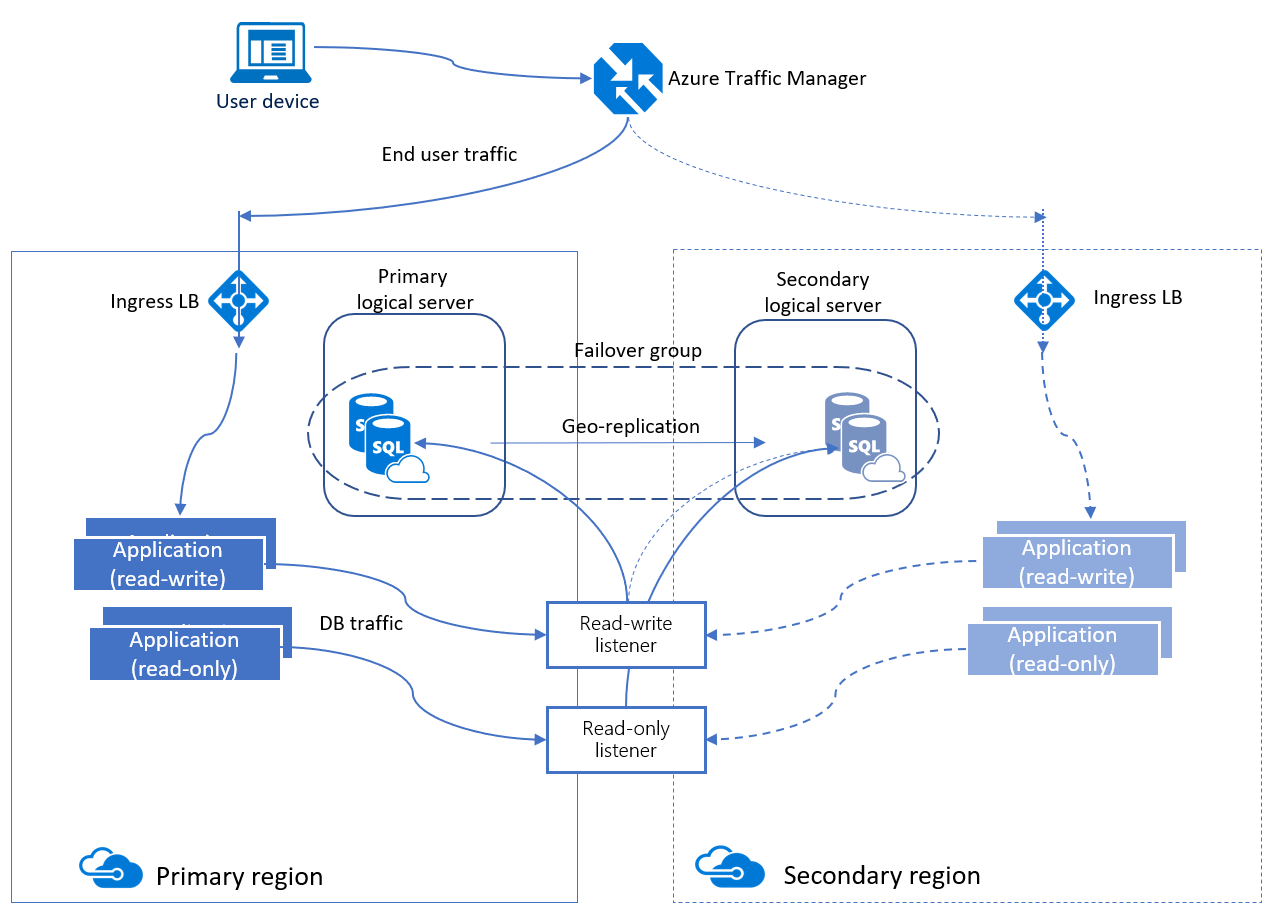
Grupy automatycznego trybu failover zapewniają funkcję podobną do grupy dostępności nazywaną odbiornikiem, która umożliwia działanie zarówno do odczytu i zapisu, jak i tylko do odczytu. Istnieją dwa różne typy odbiorników: jeden dla odczytu i zapisu i jeden dla ruchu tylko do odczytu. W tle w trybie failover system DNS jest aktualizowany, aby klienci mogli wskazać nazwę abstrakcyjnego odbiornika i nie muszą nic innego znać. Serwer bazy danych zawierający kopie odczytu i zapisu jest podstawowym serwerem odbierającym transakcje z serwera podstawowego jest pomocniczy.
Istnieją dwie różne zasady dla grup automatycznego trybu failover.
| Typ zasad | opis |
|---|---|
| Automatyczna | Po wykryciu błędu system domyślnie wyzwala tryb failover. Jednak w razie potrzeby możesz wyłączyć automatyczne przełączanie w tryb failover. |
| Tylko odczyt | Podczas pracy w trybie failover aparat domyślnie wyłącza odbiornik tylko do odczytu, aby zachować wydajność nowego podstawowego elementu podstawowego, gdy pomocnicza nie działa. Można jednak zmienić to zachowanie, aby zezwolić na oba typy ruchu po przejściu w tryb failover. |
Tryb failover to proces, który można zainicjować ręcznie, nawet jeśli jest włączony automatyczny tryb failover. Jednak typ trybu failover może mieć wpływ na to, czy dochodzi do utraty danych. Na przykład nieplanowane przejście w tryb failover może prowadzić do utraty danych, jeśli jest to wymuszone, a pomocnicza baza danych nie została w pełni zsynchronizowana z bazą podstawową.
Określa GracePeriodWithDataLossHours czas oczekiwania platformy Azure przed zainicjowaniem trybu failover z wartością domyślną ustawioną na jedną godzinę. Jeśli cel punktu odzyskiwania (RPO) jest rygorystyczny, a utrata danych nie jest opcją, możesz ustawić tę wartość wyższą. Oznacza to, że platforma Azure czeka dłużej przed zainicjowaniem trybu failover, ale może potencjalnie zmniejszyć utratę danych, ponieważ zapewnia więcej czasu na synchronizację pomocniczej bazy danych z podstawową bazą danych.
Uwaga
Pomocnicza baza danych jest tworzona automatycznie za pomocą procesu nazywanego rozmieszczaniem, co może zająć trochę czasu w zależności od rozmiaru bazy danych. Dlatego ważne jest zaplanowanie z wyprzedzeniem, biorąc pod uwagę czynniki takie jak szybkość sieci.
Aby dowiedzieć się więcej o wysokiej dostępności i odzyskiwaniu po awarii dla usługi Azure SQL Database, zobacz Listę kontrolną wysokiej dostępności i odzyskiwania po awarii usługi Azure SQL Database.