Replikowanie danych do klastra pomocniczego
Platforma Kafka jest często wdrażana w wielu środowiskach na potrzeby odzyskiwania po awarii, wysokiej dostępności i lokalnych scenariuszy hybrydowych w chmurze. Te scenariusze wymagają replikacji danych z jednego wystąpienia platformy Kafka do drugiego przy użyciu funkcji dublowania platformy Apache Kafka. Dublowanie może być uruchamiane jako proces ciągły lub używane sporadycznie jako metoda migrowania danych z jednego klastra do innego.
Dublowanie nie należy traktować jako środka do osiągnięcia odporności na uszkodzenia. Przesunięcie elementów w temacie różni się między klastrami podstawowymi i pomocniczymi, więc klienci nie mogą używać tych dwóch zamiennie.
Jak działa dublowanie?
Dublowanie działa przy użyciu narzędzia MirrorMaker (część platformy Apache Kafka) do korzystania z rekordów z tematów w klastrze podstawowym, a następnie tworzenia kopii lokalnej w klastrze pomocniczym. Narzędzie MirrorMaker używa co najmniej jednego użytkownika odczytującego z klastra podstawowego i producenta zapisującego w lokalnym klastrze pomocniczym.
Najbardziej przydatna konfiguracja dublowania na potrzeby odzyskiwania po awarii korzysta z klastrów platformy Kafka w różnych regionach świadczenia usługi Azure. W tym celu sieci wirtualne, w których znajdują się klastry, są połączone za pomocą komunikacji równorzędnej.
Na poniższym diagramie przedstawiono proces dublowania i sposób przepływu komunikacji między klastrami:
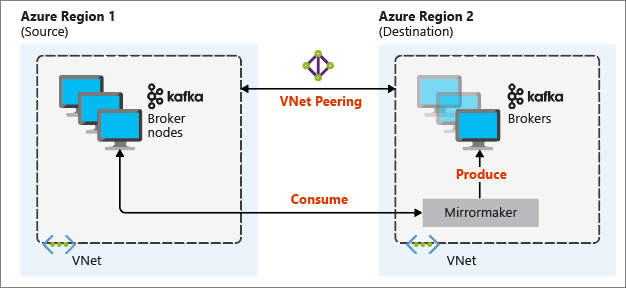
Klastry podstawowe i pomocnicze mogą być różne w liczbie węzłów i partycji, a przesunięcia w tych tematach również różnią się. Funkcja dublowania utrzymuje wartość klucza używaną do partycjonowania, więc kolejność rekordów jest zachowywana dla poszczególnych kluczy.
Dublowanie w granicach sieci
Jeśli konieczne jest dublowanie między klastrami platformy Kafka w różnych sieciach, należy wziąć pod uwagę następujące dodatkowe kwestie:
- Bramy: sieci muszą być w stanie komunikować się na poziomie TCP/IP.
-
Adresowanie serwera: możesz wybrać adresowanie węzłów klastra przy użyciu ich adresów IP lub w pełni kwalifikowanych nazw domen.
- Adresy IP: jeśli skonfigurujesz klastry platformy Kafka do korzystania z reklam adresów IP, możesz kontynuować konfigurację dublowania przy użyciu adresów IP węzłów brokera i węzłów usługi zookeeper.
- Nazwy domen: jeśli nie skonfigurujesz klastrów platformy Kafka na potrzeby reklam adresów IP, klastry muszą mieć możliwość łączenia się ze sobą przy użyciu w pełni kwalifikowanych nazw domen (FQDN). Wymaga to serwera systemu nazw domen (DNS) w każdej sieci skonfigurowanej do przekazywania żądań do innych sieci. Podczas tworzenia sieci wirtualnej platformy Azure zamiast używania automatycznego systemu DNS dostarczonego z siecią należy określić niestandardowy serwer DNS i adres IP serwera. Po utworzeniu sieci wirtualnej należy utworzyć maszynę wirtualną platformy Azure, która używa tego adresu IP, a następnie zainstalować i skonfigurować na niej oprogramowanie DNS.
Ostrzeżenie
Utwórz i skonfiguruj niestandardowy serwer DNS przed zainstalowaniem usługi HDInsight w sieci wirtualnej. Nie ma dodatkowej konfiguracji wymaganej dla usługi HDInsight do korzystania z serwera DNS skonfigurowanego dla sieci wirtualnej.