Ćwiczenie — przesyłanie strumieniowe danych platformy Kafka do notesu Jupyter i okna danych
Klaster Platformy Kafka zapisuje teraz dane w dzienniku, które można przetworzyć za pośrednictwem przesyłania strumieniowego ze strukturą platformy Spark.
Notes platformy Spark jest uwzględniony w sklonowanym przykładzie, więc musisz przekazać ten notes do klastra Spark, aby go użyć.
Przekazywanie notesu języka Python do klastra Spark
W witrynie Azure Portal kliknij pozycję Główne > klastry usługi HDInsight, a następnie wybierz właśnie utworzony klaster Spark (a nie klaster Platformy Kafka).
W okienku Pulpity nawigacyjne klastra kliknij pozycję Notes Jupyter.
Po wyświetleniu monitu o poświadczenia wprowadź nazwę użytkownika administratora i wprowadź hasło utworzone podczas tworzenia klastrów. Zostanie wyświetlona witryna internetowa Jupyter.
Kliknij pozycję PySpark, a następnie na stronie PySpark kliknij pozycję Przekaż.
Przejdź do lokalizacji, w której pobrano przykład z usługi GitHub, wybierz plik RealTimeStocks.ipynb, a następnie kliknij przycisk Otwórz, a następnie kliknij pozycję Przekaż, a następnie kliknij przycisk Odśwież w przeglądarce internetowej.
Po przekazaniu notesu do folderu PySpark kliknij pozycję RealTimeStocks.ipynb, aby otworzyć notes w przeglądarce.
Uruchom pierwszą komórkę w notesie, umieszczając kursor w komórce, a następnie klikając Shift+Enter, aby uruchomić komórkę.
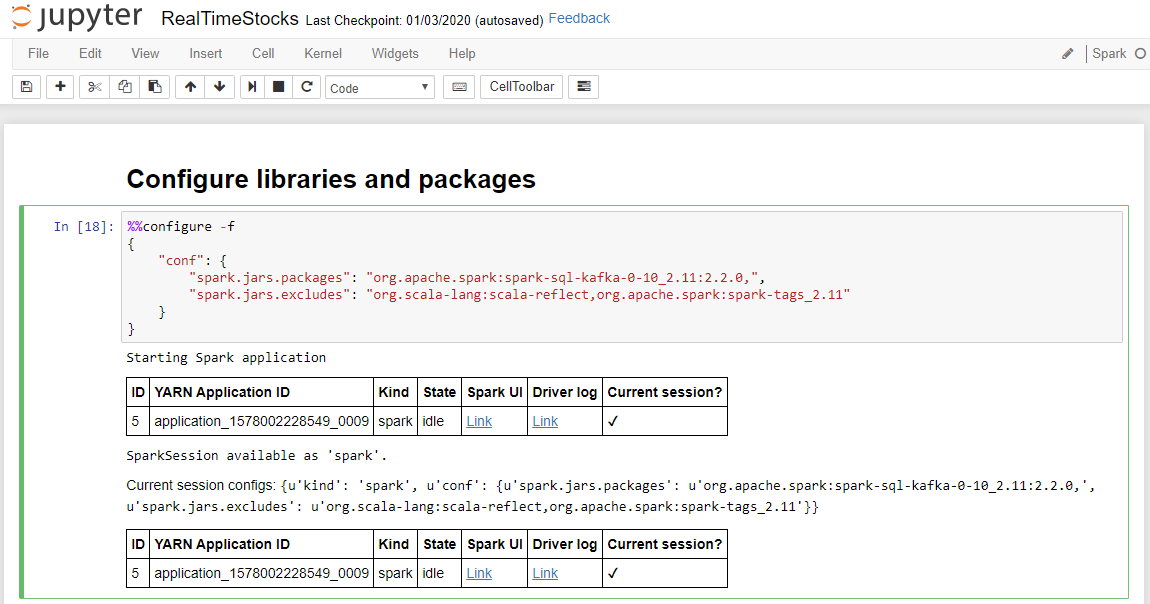
Komórka Konfigurowanie bibliotek i pakietów zakończy się pomyślnie po wyświetleniu komunikatu Uruchamianie aplikacji Spark i dodatkowych informacji, jak pokazano na poniższym podpisie ekranu.
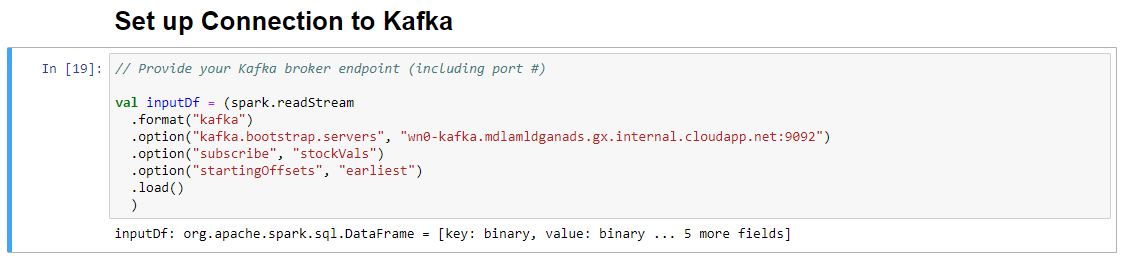
W komórce Konfigurowanie połączenia z platformą Kafka w wierszu .option("kafka.bootstrap.servers", "") wprowadź brokera platformy Kafka między drugim zestawem cudzysłowów. Na przykład .option("kafka.bootstrap.servers", "wn0-kafka.mdlamldganads.gx.internal.cloudapp.net:9092"), a następnie kliknij Shift+Enter, aby uruchomić komórkę.
Komórka Konfiguruj połączenie z platformą Kafka zostanie pomyślnie ukończona po wyświetleniu komunikatu inputDf: org.apache.spark.sql.DataFrame = [key: binary, value: binary ... 5 kolejnych pól]. Platforma Spark używa interfejsu API readStream do odczytywania danych.
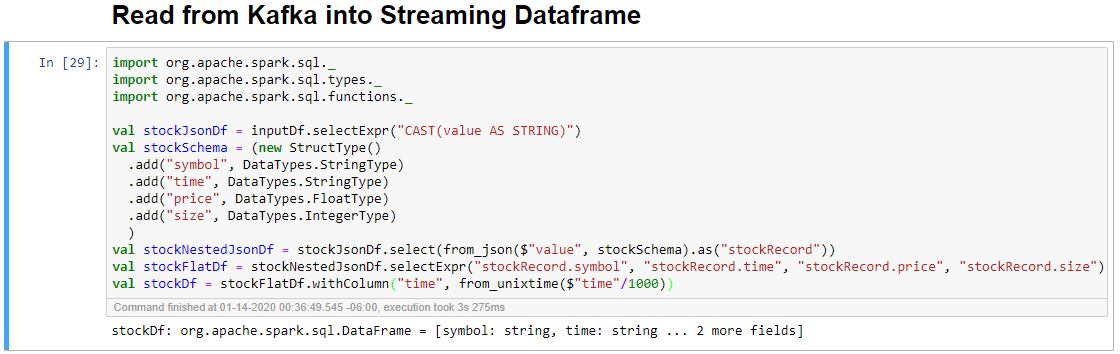
Wybierz komórkę Odczyt z platformy Kafka do ramki danych przesyłania strumieniowego, a następnie kliknij przycisk Shift+Enter, aby uruchomić komórkę.
Komórka zostanie pomyślnie ukończona po wyświetleniu następującego komunikatu: stockDf: org.apache.spark.sql.DataFrame = [symbol: ciąg, czas: ciąg... 2 więcej pól]
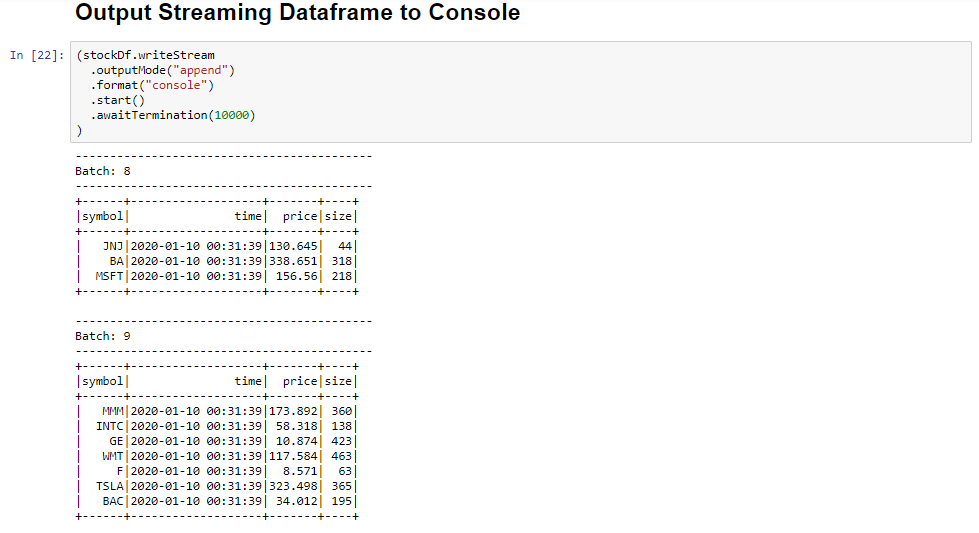
Wybierz komórkę Output Streaming Dataframe do konsoli , a następnie kliknij przycisk Shift+Enter, aby uruchomić komórkę.
Komórka zostanie pomyślnie ukończona po wyświetleniu informacji podobnych do poniższych. Dane wyjściowe pokazują wartość każdej komórki, ponieważ została przekazana w mikrosadowej partii, a jedna partia na sekundę.
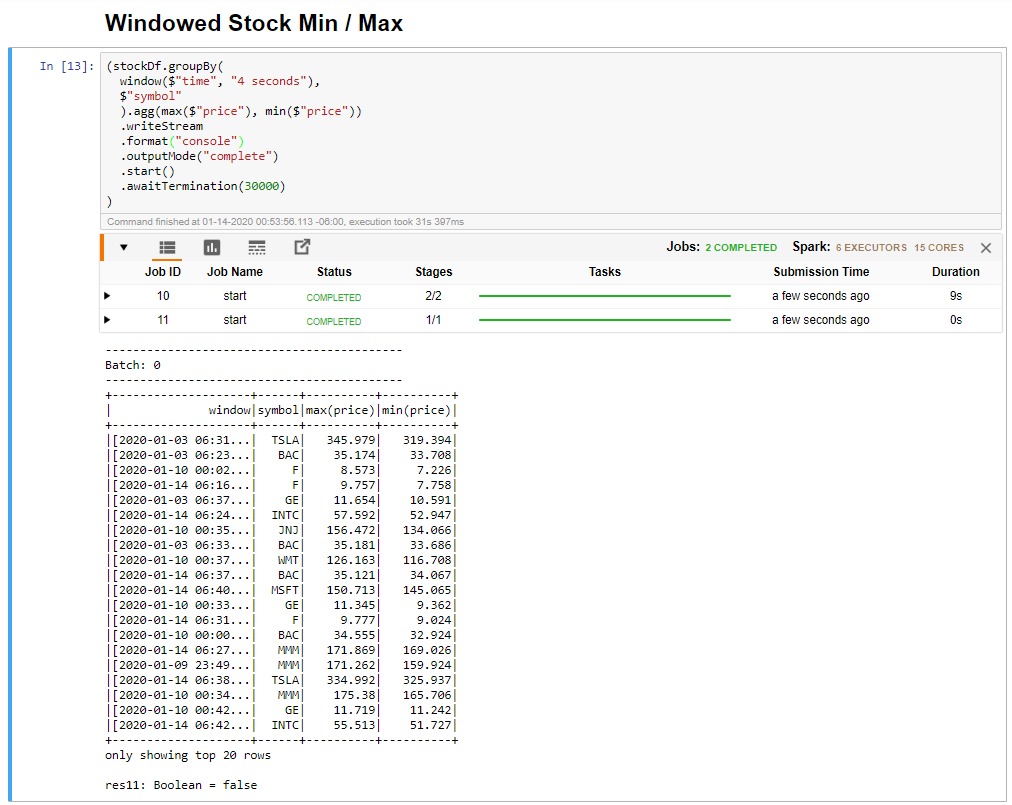
Wybierz komórkę Minimalna/Maksymalna w oknie, a następnie kliknij przycisk Shift + Enter, aby uruchomić komórkę.
Komórka kończy się pomyślnie, gdy zapewnia maksymalną i minimalną cenę dla każdej akcji w 4-sekundowym oknie zdefiniowanym w komórce. Jak wspomniano w poprzedniej lekcji, udostępnianie informacji o określonych oknach czasu jest jedną z korzyści, jakie zyskujesz przy użyciu przesyłania strumieniowego ze strukturą platformy Spark.
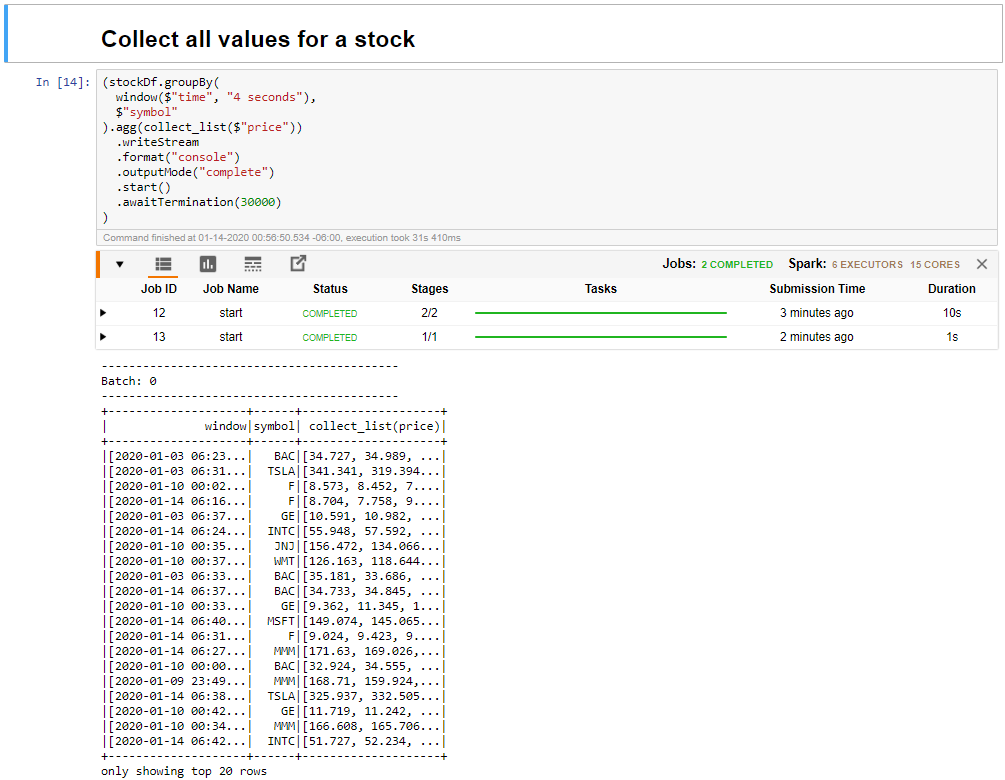
Wybierz pozycję Zbierz wszystkie wartości dla akcji w komórce okna, a następnie kliknij pozycję Shift + Enter, aby uruchomić komórkę.
Komórka zostanie pomyślnie ukończona, gdy zawiera tabelę wartości dla zapasów w tabeli. Moduł outputMode został ukończony, aby wyświetlić wszystkie dane.
W tej lekcji przekazano notes Jupyter do klastra Spark, połączono go z klastrem Platformy Kafka, wyprowadzono dane przesyłane strumieniowo utworzone przez plik producenta języka Python do notesu platformy Spark, zdefiniowano okno dla danych przesyłania strumieniowego i wyświetlono wysokie i niskie ceny zapasów w tym oknie oraz wyświetlono wszystkie wartości zapasów w tabeli. Gratulacje, pomyślnie wykonano przesyłanie strumieniowe ze strukturą przy użyciu platformy Spark i platformy Kafka!