Przesyłanie strumieniowe danych przy użyciu platformy Apache Kafka
Platforma Apache Kafka została utworzona przez firmę LinkedIn w 2010 r. z celem przenoszenia danych na bardzo dużą skalę przy bardzo małym opóźnieniu z wysokim poziomem odporności na uszkodzenia. Następnie linkedIn przekazał projekt fundacji Apache w 2012 roku, ale LinkedIn nadal korzysta z platformy Kafka w całym ekosystemie do śledzenia aktywności użytkowników, wymiany komunikatów i zbierania metryk.
Kafka to rozproszona platforma przesyłania strumieniowego, która została zaprojektowana w celu:
- Upraszczanie potoków danych
- Obsługa dużych ilości danych we wzorcu przesyłania strumieniowego
- Obsługa systemów w czasie rzeczywistym i wsadowych
- Masowe skalowanie w poziomie
Najpierw poznajmy czystą platformę Apache Kafka, a następnie na temat platformy Kafka w usłudze Azure HDInsight.
Składniki platformy Kafka
Zanim zrozumiemy, jak działa platforma Kafka, przyjrzyjmy się rolam niektórych kluczowych składników platformy Kafka i sposobom ich łączenia w celu zapewnienia wysoce skalowalnego i odpornego na błędy systemu obsługi komunikatów.
Broker
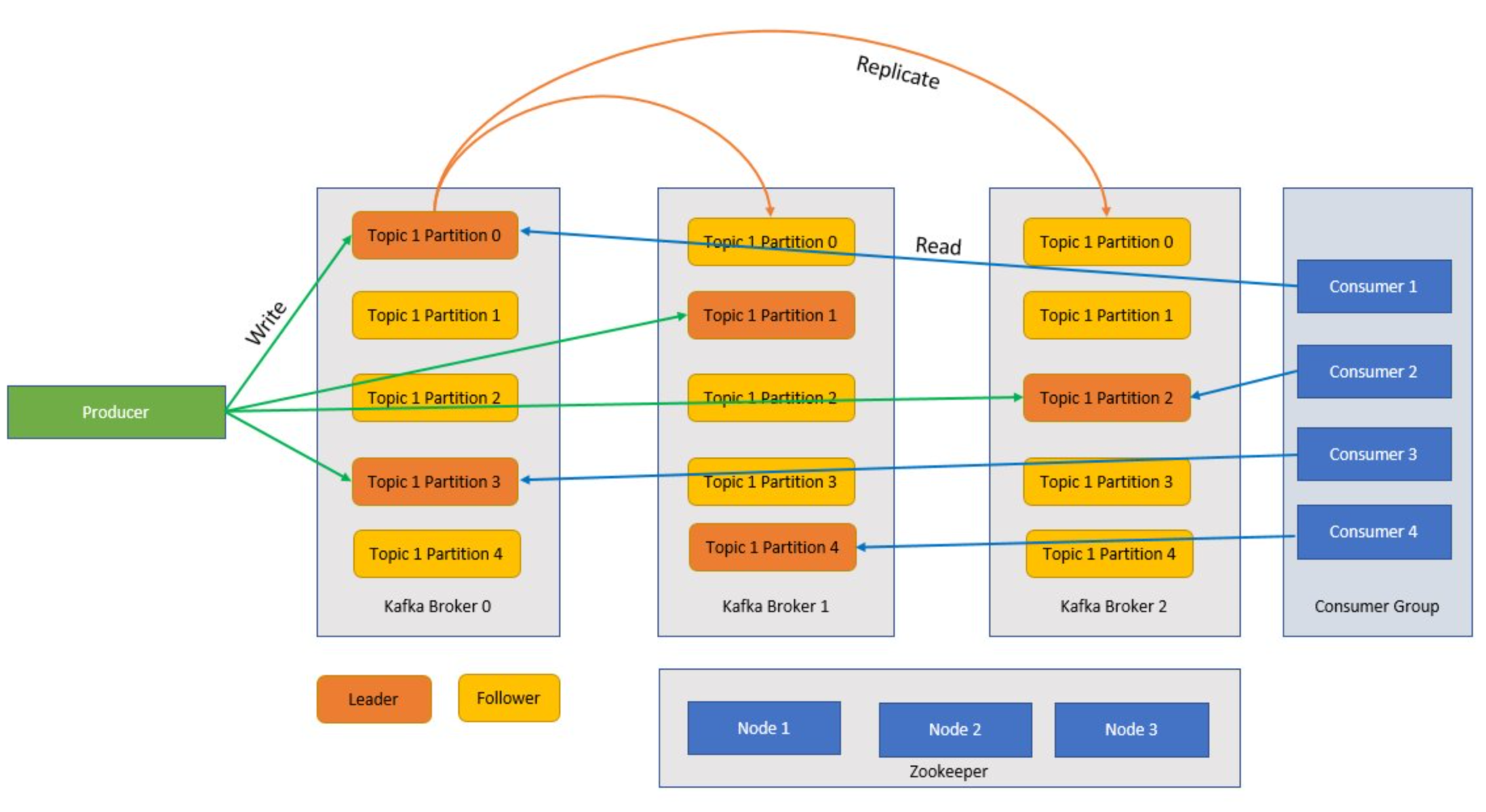
Kafka to usługa klastrowana, a pojedynczy klaster Kafka jest również nazywany brokerem. Brokerzy odbierają komunikaty od producentów i przechowują te komunikaty na dysku. Broker odpowiada również na żądania pobierania od konsumentów. W klastrze brokerów jeden broker służy jako kontroler i jest odpowiedzialny za operacje administracyjne i przypisywanie partycji do brokerów.
Komunikat
Jednostka danych w klastrze platformy Kafka. Komunikaty w większości wystąpień to pary klucz-wartość.
Tematy i partycje
Tematy i partycje to kategorie komunikatów na platformie Kafka. Tematy są zwykle podzielone na wiele partycji, które można ulepszyć, z zalecanym co najmniej trzema partycjami. Komunikaty są zapisywane w partycji tematu tylko w sposób dołączania. Partycje są dodatkowo replikowane między wieloma brokerami w celu zwiększenia nadmiarowości w przypadku awarii brokera. Partycje umożliwiają równoległe odczytywanie tematów, ponieważ umożliwiają one dzielenie danych między wieloma brokerami. Istnieje replika lidera, która obsługuje wszystkie żądania odczytu i zapisu, a obserwatorzy są replikowane od lidera. Jeśli lider ulegnie awarii, jedna z replik stanie się liderem.
Producenci i konsumenci
Producenci i konsumenci to klienci, którzy tworzą i zużywają komunikaty z systemu Kafka. Producenci publikują nowe wiadomości i kierują je do określonego tematu. Użytkownicy mogą również być projektowane tak, aby zapisywali dane w określonej partycji tematu. Użytkownicy z kolei subskrybują co najmniej jeden temat i czytają komunikaty z tych tematów.
Grupa konsumentów
Co najmniej jeden odbiorca może współpracować jako grupa i korzystać z komunikatów jako grupy. Jeśli liczba odbiorców jest równa liczbie partycji tematu, każdy odbiorca korzysta z jednej partycji tematu tworzącej równoległość.
Okres przetrzymywania
Komunikaty na platformie Kafka mogą być trwale przechowywane w klastrze Kafka przez wstępnie zdefiniowany okres czasu. Po osiągnięciu limitów przechowywania platforma Kafka może wygasnąć i usunąć te komunikaty.
Przesunięcie
Przesunięcie to po prostu pozycja komunikatu w partycji. Aktualizowanie bieżącego położenia w partycji w miarę przetwarzania komunikatów jest nazywane zatwierdzeniem. Po przetworzeniu komunikatu platforma Kafka zatwierdza przesunięcie komunikatu do specjalnego wewnętrznego tematu platformy Kafka. Gdy producent publikuje komunikat w partycji, jest przekazywany do lidera. Lider dodaje komunikat do dziennika zatwierdzeń i zwiększa przesunięcie komunikatu. Przesunięcie komunikatu to sposób identyfikowania komunikatów w temacie. Komunikat jest dostępny tylko dla użytkownika po zatwierdzeniu komunikatu w klastrze.
Dozorca
Zookeeper to usługa koordynacji, a w klastrze platformy Kafka usługa Zookeeper zapewnia zsynchronizowany widok stanu klastra. Platforma Kafka używa usługi Zookeeper do wyboru lidera wśród partycji brokera i tematu. Platforma Kafka używa usługi Zookeeper do zarządzania odnajdywaniem usług dla brokerów platformy Kafka tworzących klaster. Usługa Zookeeper wysyła zmiany topologii do platformy Kafka, więc każdy węzeł w klastrze wie, kiedy nowy broker dołączył, broker zmarł, temat został usunięty lub dodano temat.
Jak to wszystko się łączy?
Aplikacje (znane również jako producenci) wysyłają komunikaty do brokera platformy Kafka, a te komunikaty są przetwarzane przez jednego lub wielu użytkowników. Komunikaty w klastrze są podzielone na kategorie według tematów. Na przykład klient może utworzyć temat "Sprzedaż", aby wysłać wszystkie komunikaty, które są istotne dla sprzedaży i tak dalej. W miarę zwiększania rozmiaru tematów z coraz większymi komunikatami są one podzielone na partycje, a te partycje są dalej replikowane między brokerów platformy Kafka w celu zapewnienia nadmiarowości. Partycje są klasyfikowane jako liderzy i obserwatorzy. Partycja lidera jest zapisywana i odczytywana, podczas gdy partycje kontynuacji są po prostu replikami, które nadrabiają zaległości w stanie lidera. Aby określić, która partycja ma być zapisywana i odczytywana, producenci i konsumenci muszą wiedzieć, które partycje zostały zaprojektowane jako liderzy. Węzły zookeeper zarządzają stanem klastra Kafka i między innymi wybierają liderów partycji i udostępniają te informacje producentom i konsumentom.
Platforma Kafka gwarantuje, że komunikaty z partycją są uporządkowane w tej samej sekwencji, w której wystąpiły. Określony komunikat można wyraźnie zidentyfikować za pomocą przesunięcia, które jest jego pozycją w partycji. Odbiorca odczytuje komunikaty z partycji i przetwarzania końcowego, zatwierdza przesunięcie wskazujące, że komunikat został pomyślnie przetworzony. Platforma Kafka przechowuje wszystkie swoje rekordy na dysku i utrzymuje trwałość komunikatów. Jeśli konsument zostanie przerwany z jakiegoś powodu i przetwarzanie zostanie zatrzymane, platforma Kafka zachowuje te komunikaty dla wstępnie określonego okresu przechowywania, a po powrocie do trybu online konsument może ponownie uruchomić przetwarzanie z zatwierdzonego przesunięcia, w którym zostało przerwane przed przerwą.
Tematy dotyczące platformy Kafka
Temat platformy Kafka to źródło danych lub kolejka, w której komunikaty są przechowywane i publikowane. Producenci wypychają komunikaty do tematów, a konsumenci czytają tematy. Każdy węzeł w brokerze platformy Kafka może zawierać wiele tematów.
Jakie są zalety platformy Kafka w usłudze Azure HDInsight?
Wersja platformy Kafka typu open source oferuje wiele możliwości, ale istnieje wiele prac związanych z jego konfigurowaniem. Usługa Azure HDInsight zapewnia najlepsze platformy analizy typu open source na platformie Azure i ułatwia klientom konfigurowanie klastrów typu open source w ciągu kilku minut, zamiast poświęcać tygodnie lub miesiące na konfigurowanie tych klastrów i można ich używać od razu. Usługa HDInsight jest również gotowa do użycia w przedsiębiorstwie z następującymi korzyściami:
- Jest to usługa zarządzana zapewniająca uproszczony proces konfiguracji. W wyniku powstaje konfiguracja przetestowana i obsługiwana przez firmę Microsoft.
- Firma Microsoft zapewnia 99,9% umowy dotyczącej poziomu usług (SLA) na platformie Spark i na platformie Kafka.
- Jako magazynu zapasowego platforma Kafka używa funkcji Dyski zarządzane platformy Azure. Dyski zarządzane może zapewnić do 16 TB magazynu na brokera platformy Kafka z wieloma brokerami platformy Kafka.
- Usługa HDInsight oferuje najlepsze zabezpieczenia przedsiębiorstwa dzięki sieciom wirtualnym, precyzyjnym zabezpieczeniom z użyciem platformy Apache Ranger i szyfrowaniu byOK (Bring Your Own Key) dla danych magazynowanych
- Zgodność z normami HIPAA, SOC i PCI
- Możliwość wdrażania pełnych potoków przesyłania strumieniowego za pomocą platformy Spark i magazynu za pośrednictwem zautomatyzowanych szablonów usługi Azure Resource Manager (ARM) w tej samej sieci wirtualnej.
- Wysoką dostępność można osiągnąć za pomocą narzędzia Kafka MirrorMaker, który może korzystać z rekordów z tematów w klastrze podstawowym, a następnie utworzyć lokalną kopię w klastrze pomocniczym.
- Usługa HDInsight umożliwia zmianę liczby węzłów procesu roboczego (które hostują brokera platformy Kafka) po utworzeniu klastra. Skalowanie może być przeprowadzane w witrynie Azure Portal, w programie Azure PowerShell i w innych interfejsach zarządzania platformy Azure. W przypadku platformy Kafka po wykonaniu operacji skalowania należy przeprowadzić ponowne równoważenie replik partycji. Ponowne równoważenie partycji na platformie Kafka umożliwia skorzystanie z nowej liczby węzłów procesu roboczego.
- Do monitorowania platformy Kafka w usłudze HDInsight można użyć dzienników usługi Azure Monitor. Dzienniki usługi Azure Monitor zawierają informacje o poziomie maszyny wirtualnej, takie jak metryki dysku i karty sieciowej oraz metryki JMX z platformy Kafka.