Analizowanie klasyfikacji za pomocą krzywych charakterystyki operatora odbiorcy
Modele klasyfikacji muszą przypisać przykład do kategorii. Na przykład należy użyć takich funkcji jak rozmiar, kolor i ruch, aby określić, czy obiekt jest turystą, czy drzewem.
Możemy ulepszyć modele klasyfikacji na wiele sposobów. Na przykład możemy zagwarantować, że nasze dane są zrównoważone, czyste i skalowane. Możemy również zmienić naszą architekturę modelu i użyć hiperparametrów, aby wycisnąć jak najwięcej wydajności, jak to możliwe, z naszych danych i architektury. W końcu nie znajdziemy lepszego sposobu na poprawę wydajności zestawu testowego (lub wstrzymania) i zadeklarowania gotowego modelu.
Dostrajanie modelu do tego punktu może być złożone, ale możemy użyć ostatniego prostego kroku, aby jeszcze bardziej poprawić, jak dobrze działa nasz model. Aby to zrozumieć, musimy jednak wrócić do podstaw.
Prawdopodobieństwa i kategorie
Wiele modeli ma wiele etapów podejmowania decyzji, a ostatni często jest krokiem binaryzacji. Podczas binaryzacji prawdopodobieństwa są konwertowane na twardą etykietę. Załóżmy na przykład, że model jest dostarczany z funkcjami i oblicza, że istnieje 75% szans, że został pokazany turysta, a 25% szans na pokazano drzewo. Obiekt nie może być 75% podwyżki i 25% drzewa; to jeden lub drugi! W związku z tym model stosuje próg, który zwykle wynosi 50%. Ponieważ klasa turysty jest większa niż 50%, obiekt jest deklarowany jako turysta.
Próg 50% jest logiczny; oznacza to, że najbardziej prawdopodobna etykieta zgodnie z modelem jest zawsze wybierana. Jeśli jednak model jest stronniczy, ten próg 50% może nie być odpowiedni. Jeśli na przykład model ma niewielką tendencję do wybierania drzew więcej niż turystów, zbieranie drzew 10% częściej niż powinno, możemy dostosować nasz próg decyzyjny, aby to uwzględnić.
Odświeżanie macierzy decyzyjnych
Macierze decyzyjne to doskonały sposób na ocenę rodzajów błędów, jakie popełnia model. Daje to nam współczynniki prawdziwie dodatnich (TP), wartości prawdziwie ujemne (TN), fałszywie dodatnie (FP) i fałszywie ujemne (FN)

Możemy obliczyć kilka przydatnych cech z macierzy pomyłek. Dwie popularne cechy to:
- Współczynnik prawdziwie dodatni (czułość): jak często etykiety "True" są prawidłowo identyfikowane jako "True". Na przykład, jak często model przewiduje "turystę", gdy próbka jest wyświetlana, jest w rzeczywistości turystą.
- Współczynnik wyników fałszywie dodatnich (współczynnik alarmów fałszu): jak często etykiety "Fałsz" są niepoprawnie identyfikowane jako "Prawda". Na przykład, jak często model przewiduje "turystę", gdy jest wyświetlane drzewo.
Przyglądanie się prawdziwie dodatnim i fałszywie dodatnim wskaźnikom może pomóc nam zrozumieć wydajność modelu.
Rozważmy nasz przykład dla turystów. Najlepiej, że prawdziwie dodatni wskaźnik jest bardzo wysoki, a fałszywie dodatni wskaźnik jest bardzo niski, ponieważ oznacza to, że model identyfikuje turystów dobrze i nie identyfikuje drzew jako turystów bardzo często. Jednak jeśli prawdziwie dodatni wskaźnik jest bardzo wysoki, ale współczynnik wyników fałszywie dodatnich jest również bardzo wysoki, model jest stronniczy; identyfikuje prawie wszystko, co spotyka jako turysta. Podobnie nie chcemy, aby model z niskim współczynnikiem prawdziwie dodatnim, ponieważ wtedy, gdy model napotka turystę, oznaczy je jako drzewo.
Krzywe ROC
Krzywe charakterystyczne operatora odbiornika (ROC) to wykres, na którym wykreślimy prawdziwie dodatnie współczynniki i fałszywie dodatnie.
Krzywe ROC mogą być mylące dla początkujących z dwóch głównych powodów. Pierwszym powodem jest to, że początkujący wiedzą, że model ma tylko jedną wartość prawdziwie dodatnich i prawdziwie ujemnych wskaźników, więc wykres ROC musi wyglądać następująco:
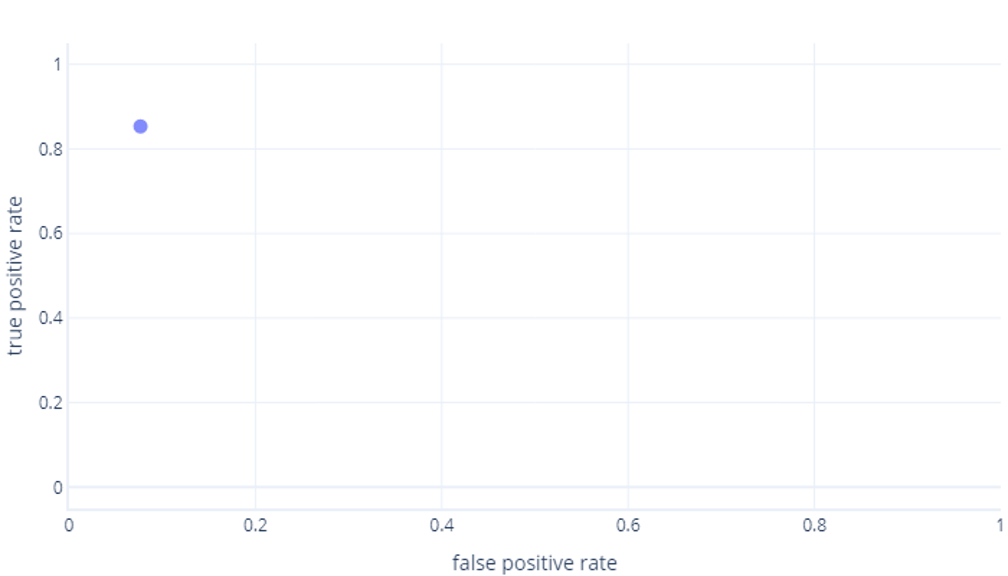
Jeśli myślisz to również, masz rację. Wytrenowany model generuje tylko jeden punkt. Należy jednak pamiętać, że nasze modele mają próg —zwykle 50%— używany do decydowania, czy należy użyć etykiety true (hiker) lub false (drzewa). Jeśli zmienimy ten próg na 30% i ponownie obliczymy prawdziwie dodatnie i fałszywie dodatnie wskaźniki, otrzymamy kolejny punkt:
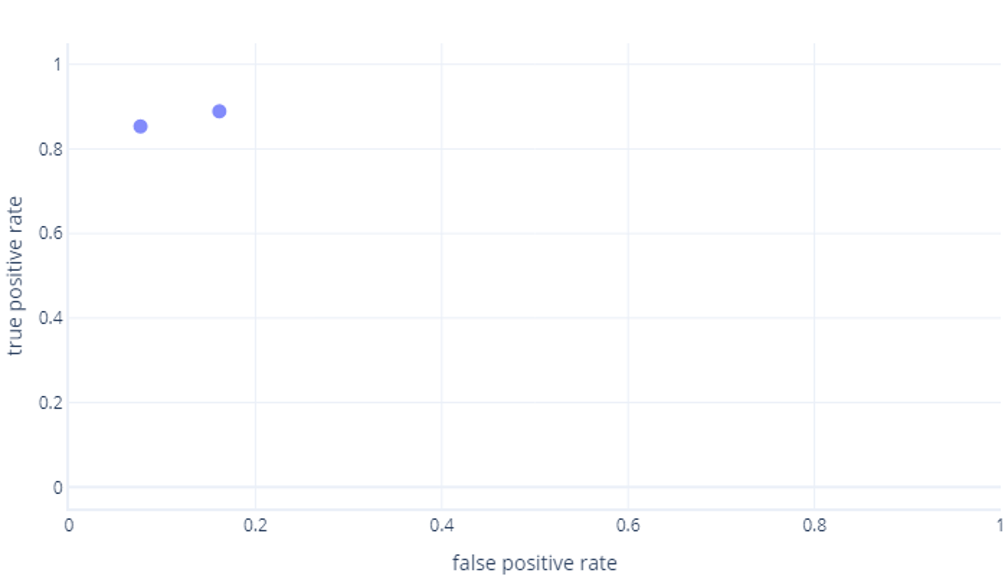
Jeśli zrobimy to dla progów z zakresu od 0%do 100%, możemy uzyskać wykres podobny do następującego:
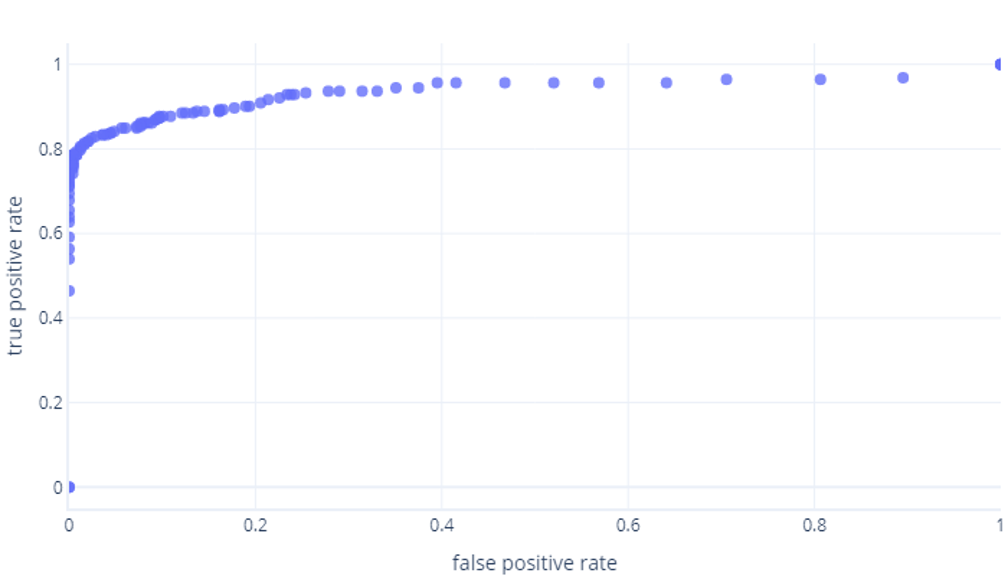
Które zwykle wyświetlamy jako wiersz, zamiast tego:
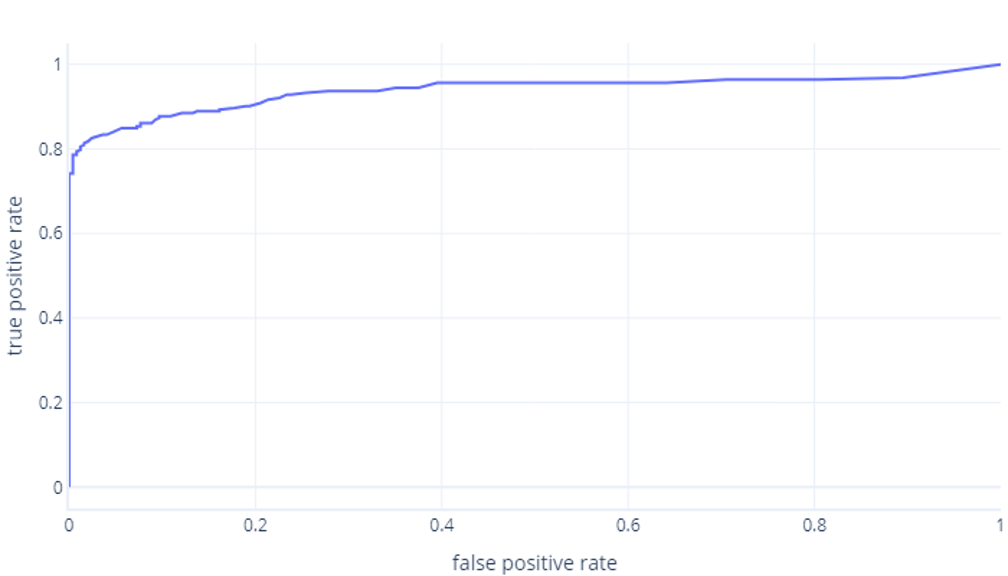
Drugim powodem, dla którego te wykresy mogą być mylące, jest żargon zaangażowany. Pamiętaj, że chcemy wysoki wskaźnik prawdziwie dodatni (identyfikując turystów jako takich) i niski wskaźnik wyników fałszywie dodatnich (nie identyfikując drzew jako turystów).
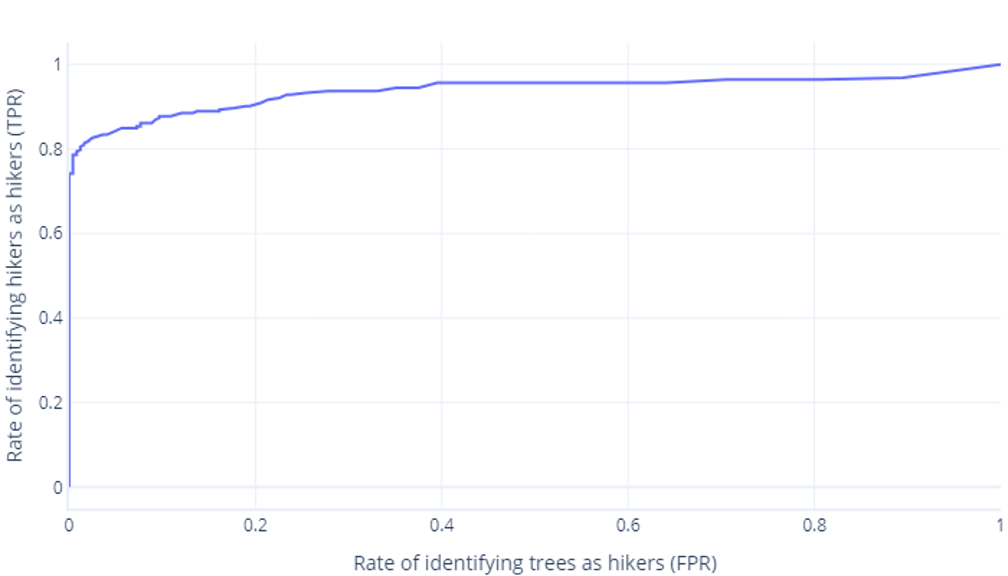
Dobry ROC, zły ROC
Zrozumienie dobrych i złych krzywych ROC jest czymś, co najlepiej zrobić w środowisku interaktywnym. Gdy wszystko będzie gotowe, przejdź do następnego ćwiczenia, aby zapoznać się z tym tematem.