Obsługa podobieństw między środowiskami przy użyciu szablonów potoków
Podczas wdrażania zmian w wielu środowiskach kroki wdrażania w każdym środowisku są podobne lub identyczne. W tej lekcji dowiesz się, jak używać szablonów potoków w celu uniknięcia powtórzeń i umożliwienia ponownego użycia kodu potoku.
Wdrażanie w wielu środowiskach
Po rozmowie ze współpracownikami w zespole witryny internetowej decydujesz się na następujący potok witryny internetowej twojej firmy:
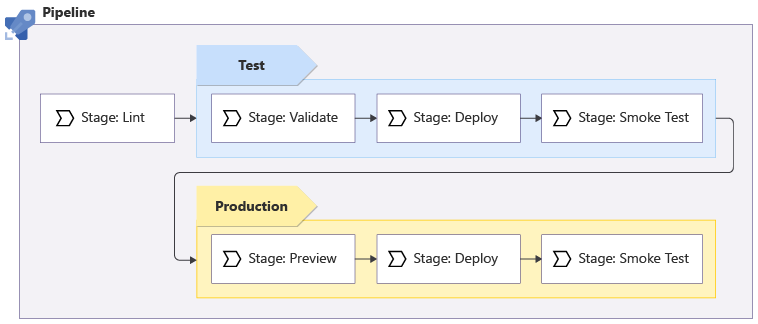
Potok uruchamia linter Bicep, aby sprawdzić, czy kod Bicep jest prawidłowy i postępuje zgodnie z najlepszymi rozwiązaniami.
Linting występuje w kodzie Bicep bez konieczności nawiązywania połączenia z platformą Azure, więc nie ma znaczenia, ile środowisk wdrażasz. Jest uruchamiany tylko raz.
Potok jest wdrażany w środowisku testowym. Ten etap wymaga:
- Uruchamianie weryfikacji wstępnej usługi Azure Resource Manager.
- Wdrażanie kodu Bicep.
- Uruchamianie niektórych testów w środowisku testowym.
Jeśli którakolwiek część potoku zakończy się niepowodzeniem, cały potok zostanie zatrzymany, aby można było zbadać i rozwiązać problem. Jeśli jednak wszystko powiedzie się, potok będzie nadal wdrażany w środowisku produkcyjnym:
- Potok uruchamia etap w wersji zapoznawczej, który uruchamia operację analizy warunkowej w środowisku produkcyjnym, aby wyświetlić listę zmian, które zostaną wprowadzone do produkcyjnych zasobów platformy Azure. Etap podglądu weryfikuje również wdrożenie, więc nie trzeba uruchamiać oddzielnego etapu weryfikacji dla środowiska produkcyjnego.
- Potok zostanie wstrzymany na potrzeby ręcznej weryfikacji.
- Jeśli zatwierdzenie zostanie odebrane, potok uruchamia wdrożenia i testy weryfikacyjne kompilacji w środowisku produkcyjnym.
Niektóre z tych etapów są powtarzane między środowiskami testowymi i produkcyjnymi, a niektóre są uruchamiane tylko dla określonych środowisk:
| Etap | Środowiska |
|---|---|
| Lint | Żadna z nich — linting nie działa w środowisku |
| Sprawdź poprawność | Tylko test |
| Podgląd | Tylko produkcja |
| Wdróż | Oba środowiska |
| Test weryfikacyjny kompilacji | Oba środowiska |
Jeśli musisz powtórzyć kroki w potoku, możesz spróbować skopiować i wkleić definicje kroków. Najlepiej jednak unikać tej praktyki. Łatwo jest przypadkowo popełnić subtelne błędy lub w przypadku rzeczy, które nie są zsynchronizowane podczas duplikowania kodu potoku. A w przyszłości, gdy musisz wprowadzić zmianę w krokach, musisz pamiętać, aby zastosować zmianę w wielu miejscach.
Szablony potoków
Szablony potoków umożliwiają tworzenie sekcji definicji potoków wielokrotnego użytku. Szablony mogą definiować kroki, zadania, a nawet całe etapy. Szablony można używać do wielokrotnego ponownego używania części potoku w jednym potoku, a nawet w wielu potokach. Można również utworzyć szablon dla zestawu zmiennych, które mają być ponownie używane w wielu potokach.
Szablon to po prostu plik YAML zawierający zawartość wielokrotnego użytku. Prosty szablon definicji kroku może wyglądać następująco i zostać zapisany w pliku o nazwie script.yml:
steps:
- script: |
echo Hello world!
Szablon w potoku można użyć, używając template słowa kluczowego w miejscu, w którym zwykle definiuje się pojedynczy krok:
jobs:
- job: Job1
pool:
vmImage: 'windows-latest'
steps:
- template: script.yml
- job: Job2
pool:
vmImage: 'ubuntu-latest'
steps:
- template: script.yml
Szablony zagnieżdżone
Szablony można również zagnieżdżać w innych szablonach. Załóżmy, że poprzedni plik nosił nazwę jobs.yml i tworzysz plik o nazwie azure-pipelines.yml , który ponownie używa szablonu zadania na wielu etapach potoku:
trigger:
branches:
include:
- main
pool:
vmImage: ubuntu-latest
stages:
- stage: Stage1
jobs:
- template: jobs.yml
- stage: Stage2
jobs:
- template: jobs.yml
W przypadku zagnieżdżania szablonów lub wielokrotnego używania ich w jednym potoku należy zachować ostrożność, aby nie używać tej samej nazwy dla wielu zasobów potoku. Na przykład każde zadanie w ramach etapu wymaga własnego identyfikatora. Dlatego jeśli zdefiniujesz identyfikator zadania w szablonie, nie możesz wielokrotnie używać go ponownie na tym samym etapie.
Podczas pracy ze złożonymi zestawami potoków wdrażania przydatne może być utworzenie dedykowanego repozytorium Git dla udostępnionych szablonów potoków. Następnie można ponownie użyć tego samego repozytorium w wielu potokach, nawet jeśli są one przeznaczone dla różnych projektów. Udostępniamy link do dodatkowych informacji w podsumowaniu.
Parametry szablonu potoku
Parametry szablonu potoku ułatwiają ponowne używanie plików szablonów, ponieważ można zezwolić na niewielkie różnice w szablonach za każdym razem, gdy ich używasz.
Podczas tworzenia szablonu potoku można wskazać jego parametry w górnej części pliku:
parameters:
- name: environmentType
type: string
default: 'Test'
- name: serviceConnectionName
type: string
Można zdefiniować dowolną liczbę parametrów. Ale podobnie jak parametry Bicep, spróbuj nie przejąć parametrów szablonu potoku. Należy ułatwić innym osobom ponowne użycie szablonu bez konieczności określania zbyt wielu ustawień.
Każdy parametr szablonu potoku ma trzy właściwości:
- Nazwa parametru, który jest używany do odwoływania się do parametru w plikach szablonu.
- Typ parametru. Parametry obsługują kilka różnych typów danych, w tym ciąg, liczbę i wartość logiczną. Można również zdefiniować bardziej złożone szablony, które akceptują obiekty ustrukturyzowane.
- Wartość domyślna parametru, który jest opcjonalny. Jeśli nie określisz wartości domyślnej, należy podać wartość podczas korzystania z szablonu potoku.
W tym przykładzie potok definiuje parametr ciągu o nazwie environmentType, który ma wartość Testdomyślną , i obowiązkowy parametr o nazwie serviceConnectionName.
W szablonie potoku używasz specjalnej składni, aby odwoływać się do wartości parametru. Użyj makra ${{parameters.YOUR_PARAMETER_NAME}} , tak jak w tym przykładzie:
steps:
- script: |
echo Hello ${{parameters.environmentType}}!
Wartość parametrów można przekazać do szablonu potoku przy użyciu parameters słowa kluczowego , na przykład w tym przykładzie:
steps:
- template: script.yml
parameters:
environmentType: Test
- template: script.yml
parameters:
environmentType: Production
Parametry można również użyć podczas przypisywania identyfikatorów do zadań i etapów w szablonach potoków. Ta technika pomaga w przypadku wielokrotnego ponownego użycia tego samego szablonu w potoku, w następujący sposób:
parameters:
- name: environmentType
type: string
default: 'Test'
jobs:
- job: Job1-${{parameters.environmentType}}
pool:
vmImage: 'windows-latest'
steps:
- template: script.yml
- job: Job2-${{parameters.environmentType}}
pool:
vmImage: 'ubuntu-latest'
steps:
- template: script.yml
Warunki
Możesz użyć warunków potoku, aby określić, czy krok, zadanie, czy nawet etap powinien być uruchamiany w zależności od określonej reguły. Parametry szablonu i warunki potoku można połączyć, aby dostosować proces wdrażania w wielu różnych sytuacjach.
Załóżmy na przykład, że definiujesz szablon potoku, który uruchamia kroki skryptu. Planujesz ponownie użyć szablonu dla każdego środowiska. Podczas wdrażania środowiska produkcyjnego chcesz uruchomić kolejny krok. Poniżej przedstawiono sposób, w jaki można to osiągnąć za pomocą if makra i eq operatora (równa się):
parameters:
- name: environmentType
type: string
default: 'Test'
steps:
- script: |
echo Hello ${{parameters.environmentType}}!
- ${{ if eq(parameters.environmentType, 'Production') }}:
- script: |
echo This step only runs for production deployments.
Warunek przekłada się na: jeśli wartość parametru environmentType jest równa wartości Production, uruchom następujące kroki.
Napiwek
Zwróć uwagę na wcięcie pliku YAML podczas używania warunków, takich jak w przykładzie. Kroki, które ma zastosowanie warunek, muszą być wcięcia o jeden dodatkowy poziom.
Można również określić condition właściwość na etapie, zadaniu lub kroku. Oto przykład pokazujący, jak można użyć operatora (nie równa się), aby określić warunek, taki jak jeśli wartość parametru ne environmentType nie jest równa produkcji, a następnie uruchom następujące kroki:
- script: |
echo This step only runs for non-production deployments.
condition: ne('${{ parameters.environmentType }}', 'Production')
Mimo że warunki są sposobem na dodanie elastyczności do potoku, spróbuj użyć zbyt wielu z nich. Komplikują one potok i utrudniają zrozumienie przepływu. Jeśli w szablonie potoku istnieje wiele warunków, szablon może nie być najlepszym rozwiązaniem dla przepływu pracy, który planujesz uruchomić, i może być konieczne przeprojektowanie potoku.
Należy również rozważyć użycie komentarzy YAML w celu wyjaśnienia warunków, których używasz, oraz wszelkich innych aspektów potoku, które mogą wymagać większego wyjaśnienia. Komentarze ułatwiają zrozumienie potoku i pracę z tym w przyszłości. W ćwiczeniach w tym module znajdują się przykładowe komentarze YAML.