Konfigurowanie magazynu i baz danych
Często część procesu wdrażania wymaga połączenia z bazami danych lub usługami magazynu. To połączenie może być konieczne do zastosowania schematu bazy danych, dodania niektórych danych referencyjnych do tabeli bazy danych lub przekazania niektórych obiektów blob. W tej lekcji dowiesz się, jak rozszerzyć przepływ pracy na usługi danych i magazynowania.
Konfigurowanie baz danych z przepływu pracy
Wiele baz danych ma schematy, które reprezentują strukturę danych zawartych w bazie danych. Często dobrym rozwiązaniem jest zastosowanie schematu do bazy danych z przepływu pracy wdrażania. Ta praktyka pomaga zapewnić, że wszystkie potrzeby rozwiązania są wdrażane razem. Gwarantuje to również, że w przypadku wystąpienia problemu podczas stosowania schematu przepływ pracy wyświetla błąd, aby można było rozwiązać problem i wdrożyć go ponownie.
Podczas pracy z usługą Azure SQL należy zastosować schematy bazy danych, łącząc się z serwerem bazy danych i wykonując polecenia przy użyciu skryptów SQL. Te polecenia to operacje płaszczyzny danych. Przepływ pracy musi uwierzytelnić się na serwerze bazy danych, a następnie wykonać skrypty. Funkcja GitHub Actions udostępnia azure/sql-action akcję, która może łączyć się z serwerem bazy danych Azure SQL Database i wykonywać polecenia.
Niektóre inne usługi danych i magazynowania nie muszą być konfigurowane przy użyciu interfejsu API płaszczyzny danych. Na przykład podczas pracy z usługą Azure Cosmos DB dane są przechowywane w kontenerze. Kontenery można skonfigurować przy użyciu płaszczyzny sterowania bezpośrednio z poziomu pliku Bicep. Podobnie można również wdrażać większość aspektów kontenerów obiektów blob usługi Azure Storage i zarządzać nimi w usłudze Bicep. W następnym ćwiczeniu zobaczysz przykład tworzenia kontenera obiektów blob na podstawie Bicep.
Dodaj dane
Wiele rozwiązań wymaga dodania danych referencyjnych do baz danych lub kont magazynu przed ich pracą. Przepływy pracy mogą być dobrym miejscem do dodawania tych danych. Oznacza to, że po uruchomieniu przepływu pracy środowisko jest w pełni skonfigurowane i gotowe do użycia.
Warto również mieć przykładowe dane w bazach danych, szczególnie w środowiskach nieprodukcyjnych. Przykładowe dane pomagają testerom i innym osobom korzystającym z tych środowisk natychmiast przetestować rozwiązanie. Te dane mogą obejmować przykładowe produkty lub takie rzeczy jak fałszywe konta użytkowników. Ogólnie rzecz biorąc, nie chcesz dodawać tych danych do środowiska produkcyjnego.
Podejście używane do dodawania danych zależy od używanej usługi. Na przykład:
- Aby dodać dane do bazy danych Azure SQL Database, musisz wykonać skrypt, podobnie jak konfigurowanie schematu.
- Jeśli musisz wstawić dane do usługi Azure Cosmos DB, musisz uzyskać dostęp do interfejsu API płaszczyzny danych, co może wymagać pisania kodu niestandardowego skryptu.
- Aby przekazać obiekty blob do kontenera obiektów blob usługi Azure Storage, możesz użyć różnych narzędzi ze skryptów przepływu pracy, w tym aplikacji wiersza polecenia narzędzia AzCopy, programu Azure PowerShell lub interfejsu wiersza polecenia platformy Azure. Każde z tych narzędzi rozumie, jak uwierzytelniać się w usłudze Azure Storage w Twoim imieniu oraz jak nawiązać połączenie z interfejsem API płaszczyzny danych w celu przekazania obiektów blob.
Idempotencja
Jedną z cech przepływów pracy wdrażania i infrastruktury jako kodu jest możliwość ponownego wdrożenia bez żadnych negatywnych skutków ubocznych. Na przykład podczas ponownego wdrażania pliku Bicep, który został już wdrożony, usługa Azure Resource Manager porównuje przesłany plik z istniejącym stanem zasobów platformy Azure. Jeśli nie ma żadnych zmian, usługa Resource Manager nic nie robi. Możliwość ponownego wykonania operacji wielokrotnie jest nazywana idempotencją. Dobrym rozwiązaniem jest upewnienie się, że skrypty i inne kroki przepływu pracy są idempotentne.
Idempotencja jest szczególnie ważna w przypadku interakcji z usługami danych, ponieważ zachowują one stan. Wyobraź sobie, że wstawiasz przykładowego użytkownika do tabeli bazy danych z przepływu pracy. Jeśli nie uważasz, nowy przykładowy użytkownik zostanie utworzony za każdym razem, gdy uruchamiasz przepływ pracy. Ten wynik prawdopodobnie nie jest odpowiedni.
W przypadku stosowania schematów do bazy danych Azure SQL Database można użyć pakietu danych nazywanego również plikiem DACPAC w celu wdrożenia schematu. Przepływ pracy tworzy plik DACPAC z kodu źródłowego i tworzy artefakt przepływu pracy, podobnie jak w przypadku aplikacji. Następnie zadanie wdrożenia w przepływie pracy publikuje plik DACPAC w bazie danych:
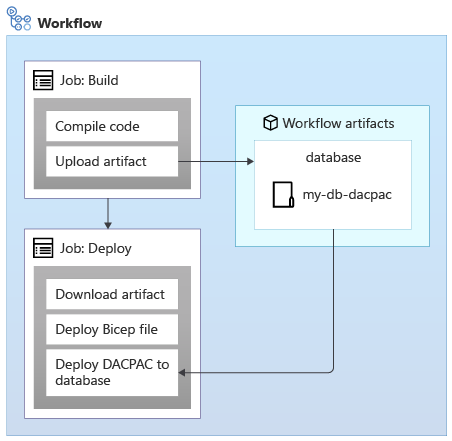
Po wdrożeniu pliku DACPAC zachowuje się w idempotentny sposób, porównując stan docelowy bazy danych ze stanem zdefiniowanym w pakiecie. W wielu sytuacjach oznacza to, że nie trzeba pisać skryptów, które są zgodne z zasadą idempotencji, ponieważ narzędzie obsługuje je za Ciebie. Niektóre narzędzia dla usług Azure Cosmos DB i Azure Storage również działają prawidłowo.
Jednak podczas tworzenia przykładowych danych w bazie danych Azure SQL Database lub innej usłudze magazynu, która nie działa automatycznie w sposób idempotentny, dobrym rozwiązaniem jest napisanie skryptu, aby utworzyć dane tylko wtedy, gdy jeszcze nie istnieją.
Ważne jest również, aby rozważyć, czy może być konieczne wycofanie wdrożeń, takich jak ponowne uruchomienie starszej wersji przepływu pracy wdrażania. Wycofywanie danych może stać się skomplikowane, dlatego starannie zastanów się, jak będzie działać rozwiązanie, jeśli musisz zezwolić na wycofywanie.
Bezpieczeństwo sieci
Czasami można zastosować ograniczenia sieci do niektórych zasobów platformy Azure. Te ograniczenia mogą wymuszać reguły dotyczące żądań wysyłanych do płaszczyzny danych zasobu, takich jak:
- Ten serwer bazy danych jest dostępny tylko z określonej listy adresów IP.
- To konto magazynu jest dostępne tylko z zasobów wdrożonych w określonej sieci wirtualnej.
Ograniczenia sieci są powszechne w przypadku baz danych, ponieważ może się wydawać, że w Internecie nie ma potrzeby nawiązywania połączenia z serwerem bazy danych.
Jednak ograniczenia sieci mogą również utrudnić przepływom pracy wdrażania pracę z płaszczyznami danych zasobów. W przypadku korzystania z modułu uruchamiającego hostowanego w usłudze GitHub jego adres IP nie jest łatwo znany z wyprzedzeniem i może zostać przypisany z dużej puli adresów IP. Ponadto moduły uruchamiane w usłudze GitHub nie mogą być połączone z własnymi sieciami wirtualnymi.
Niektóre akcje, które ułatwiają wykonywanie operacji płaszczyzny danych, mogą obejść te problemy. Na przykład akcja azure/sql-action :
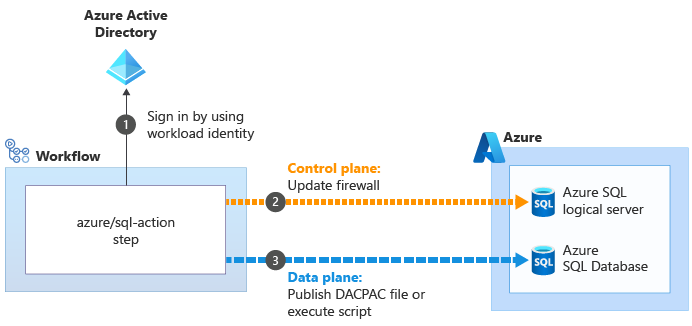
Gdy używasz azure/sql-action akcji do pracy z serwerem logicznym lub bazą danych azure SQL, używa tożsamości obciążenia do nawiązywania połączenia z płaszczyzną sterowania dla serwera logicznego usługi Azure SQL. Aktualizuje zaporę, aby umożliwić modułowi uruchamiającego dostęp do serwera z jego adresu
obciążenia do nawiązywania połączenia z płaszczyzną sterowania dla serwera logicznego usługi Azure SQL. Aktualizuje zaporę, aby umożliwić modułowi uruchamiającego dostęp do serwera z jego adresu IP. Następnie można pomyślnie przesłać plik DACPAC lub skrypt do wykonania
IP. Następnie można pomyślnie przesłać plik DACPAC lub skrypt do wykonania . Następnie akcja automatycznie usuwa regułę zapory po jej zakończeniu.
. Następnie akcja automatycznie usuwa regułę zapory po jej zakończeniu.
W innych sytuacjach nie można utworzyć takich wyjątków. W takich okolicznościach rozważ użycie własnego modułu uruchamiającego, który działa na maszynie wirtualnej lub innym zasobie obliczeniowym, który kontrolujesz. Następnie można skonfigurować ten moduł uruchamiający, jednak jest potrzebny. Może używać znanego adresu IP lub łączyć się z własną siecią wirtualną. W tym module nie omawiamy modułów uruchamianych samodzielnie, ale udostępniamy linki do dodatkowych informacji na stronie Podsumowanie modułu.
Przepływ pracy wdrażania
W następnym ćwiczeniu zaktualizujesz przepływ pracy wdrażania, aby dodać nowe zadania w celu skompilowania składników bazy danych witryny internetowej, wdrożenia bazy danych i dodania danych inicjowania:
