Konfigurowanie magazynu i baz danych
Często część procesu wdrażania wymaga połączenia z bazami danych lub usługami magazynu. To połączenie może być konieczne do zastosowania schematu bazy danych, dodania pewnych danych referencyjnych do tabeli bazy danych lub przesłania niektórych obiektów blob. W tej jednostce dowiesz się, jak rozszerzyć potok, aby współpracować z usługami danych i magazynowania.
Konfigurowanie baz danych z potoku
Wiele baz danych ma schematy , które reprezentują strukturę danych zawartych w bazie danych. Często dobrym rozwiązaniem jest zastosowanie schematu do bazy danych z pipeliny wdrożeniowej. Ta praktyka pomaga zapewnić, że wszystko, czego potrzebuje twoje rozwiązanie, jest wdrażane razem. Gwarantuje również, że w przypadku wystąpienia problemu podczas stosowania schematu potok wyświetla błąd. Błąd umożliwia rozwiązanie problemu i ponowne wdrożenie.
Podczas pracy z usługą Azure SQL należy zastosować schematy bazy danych, łącząc się z serwerem bazy danych i wykonując polecenia przy użyciu skryptów SQL. Te polecenia to operacje płaszczyzny danych. Potok zadań musi uwierzytelniać się na serwerze bazy danych, a następnie wykonywać skrypty. Usługa Azure Pipelines udostępnia zadanie SqlAzureDacpacDeployment, które może łączyć się z serwerem usługi Azure SQL Database i wykonywać polecenia.
Niektóre inne usługi danych i magazynowania nie muszą być konfigurowane przy użyciu interfejsu API warstwy danych. Na przykład podczas pracy z usługą Azure Cosmos DB dane są przechowywane w kontenerze . Kontenery można skonfigurować przy użyciu płaszczyzny sterowania bezpośrednio z poziomu pliku Bicep. Podobnie, w ramach Bicep można wdrażać i zarządzać większością aspektów kontenerów obiektów blob usługi Azure Storage. W następnym ćwiczeniu zobaczysz przykład tworzenia kontenera blobów przy użyciu Bicep.
Dodawanie danych
Wiele rozwiązań wymaga dodania danych referencyjnych do baz danych lub kont magazynowych, zanim zaczną działać. Rury mogą być dobrym miejscem do dodawania tych danych. Gdy potok zostanie uruchomiony, środowisko jest w pełni skonfigurowane i gotowe do użycia.
Warto również mieć przykładowe dane w bazach danych, szczególnie w środowiskach nieprodukcyjnych. Przykładowe dane pomagają testerom i innym osobom korzystającym z tych środowisk natychmiast przetestować rozwiązanie. Te dane mogą obejmować przykładowe produkty lub takie rzeczy jak fałszywe konta użytkowników. Ogólnie rzecz biorąc, nie chcesz dodawać tych danych do środowiska produkcyjnego.
Podejście używane do dodawania danych zależy od używanej usługi. Na przykład:
- Aby dodać dane do bazy danych Azure SQL Database, musisz wykonać skrypt, podobnie jak konfigurowanie schematu.
- Aby wstawić dane do bazy danych Azure Cosmos DB, musisz uzyskać dostęp do API warstwy danych, co może wymagać napisania trochę kodu skryptu dostosowanego do potrzeb.
- Aby przekazać obiekty blob do kontenera usługi Azure Storage, możesz użyć różnych narzędzi w skryptach potokowych, w tym aplikacji wiersza polecenia AzCopy, programu Azure PowerShell lub interfejsu wiersza polecenia Azure CLI. Każde z tych narzędzi rozumie, jak uwierzytelniać się w usłudze Azure Storage w Twoim imieniu oraz jak nawiązać połączenie z interfejsem API płaszczyzny danych w celu przekazania obiektów blob.
Idempotencja
Jedną z cech potoków wdrażania i infrastruktury jako kodu jest możliwość ponownego dokonywania wdrożeń bez żadnych negatywnych skutków. Na przykład po ponownym wdrożeniu wcześniej wdrożonego pliku Bicep usługa Azure Resource Manager porównuje przesłany plik z istniejącym stanem zasobów platformy Azure. Jeśli nie ma żadnych zmian, usługa Resource Manager nic nie robi. Możliwość ponownego wykonania operacji wielokrotnie jest nazywana idempotence. Dobrym rozwiązaniem jest upewnienie się, że skrypty i inne kroki potoku są idempotentne.
Idempotencja ma szczególne znaczenie w interakcji z usługami danych, ponieważ utrzymują one stan. Wyobraź sobie, że wstawiasz przykładowego użytkownika do tabeli bazy danych z przepływu pracy. Jeśli nie jesteś ostrożny, za każdym razem, gdy uruchamiasz potok, zostanie utworzony nowy przykładowy użytkownik. Ten wynik prawdopodobnie nie jest tym, czego chcesz.
W przypadku stosowania schematów do bazy danych Azure SQL Database można użyć pakietu danych nazywanego również plikiem DACPAC w celu wdrożenia schematu. Twój przepływ pracy buduje plik DACPAC z kodu źródłowego i tworzy artefakt przepływu pracy, podobnie jak w przypadku aplikacji. Następnie etap wdrażania w ciągu publikacji przesyła plik DACPAC do bazy danych:
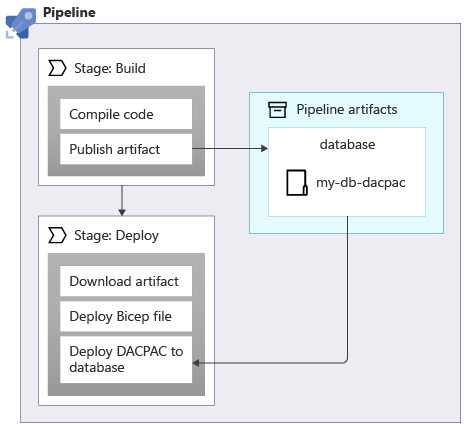
Po wdrożeniu pliku DACPAC, zachowuje się on w sposób idempotentny. Porównuje ona stan docelowy bazy danych z stanem zdefiniowanym w pakiecie. W wielu sytuacjach oznacza to, że nie trzeba pisać skryptów, które są zgodne z zasadą idempotencji, ponieważ narzędzie obsługuje je za Ciebie. Niektóre narzędzia dla usług Azure Cosmos DB i Azure Storage również działają prawidłowo.
Jednak podczas tworzenia przykładowych danych w bazie danych Azure SQL lub innej usłudze magazynowania, która nie działa automatycznie w trybie idempotentnym. Dobrą praktyką jest napisanie skryptu w taki sposób, aby tworzył dane tylko wtedy, gdy jeszcze nie istnieją.
Ważne jest również, aby rozważyć, czy może być konieczne wycofanie wdrożeń, takich jak ponowne uruchomienie starszej wersji pipeline'u wdrożeniowego. Wycofywanie zmian w danych może stać się skomplikowane, dlatego należy dokładnie rozważyć, jak funkcjonuje Twoje rozwiązanie, jeśli konieczne jest wycofanie zmian.
Zabezpieczenia sieci
Czasami można zastosować ograniczenia sieci do niektórych zasobów platformy Azure. Te ograniczenia mogą wymuszać reguły dotyczące żądań wysyłanych do płaszczyzny danych zasobu, takich jak:
- Ten serwer bazy danych jest dostępny tylko z określonej listy adresów IP.
- To konto magazynowe jest dostępne tylko z zasobów wdrożonych w określonej sieci wirtualnej.
Ograniczenia sieci są powszechne w przypadku baz danych, ponieważ może się wydawać, że w Internecie nie ma potrzeby nawiązywania połączenia z serwerem bazy danych.
Jednakże ograniczenia sieci mogą również utrudniać działanie potoków wdrożeniowych z płaszczyznami danych zasobów. Jeśli używasz agenta potoku hostowanego przez firmę Microsoft, jego adres IP nie może być łatwo znany z wyprzedzeniem i może zostać przypisany z dużej puli adresów IP. Ponadto agenci potoków hostowanych przez firmę Microsoft nie mogą łączyć się z Twoimi własnymi sieciami wirtualnymi.
Niektóre zadania usługi Azure Pipelines, które ułatwiają wykonywanie operacji płaszczyzny danych, mogą obejść te problemy. Na przykład zadanie SqlAzureDacpacDeployment:
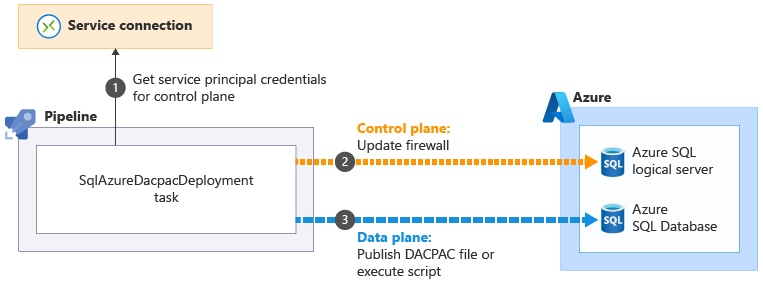
Gdy używasz zadania SqlAzureDacpacDeployment do pracy z serwerem logicznym lub bazą danych Azure SQL, wykorzystywana jest jednostka usługi potoku do łączenia się z płaszczyzną sterowania serwera logicznego Azure SQL. Aktualizuje zaporę, aby umożliwić agentowi potoku dostęp do serwera z jego adresu IP
do łączenia się z płaszczyzną sterowania serwera logicznego Azure SQL. Aktualizuje zaporę, aby umożliwić agentowi potoku dostęp do serwera z jego adresu IP . Następnie można pomyślnie przesłać plik DACPAC lub skrypt do wykonania
. Następnie można pomyślnie przesłać plik DACPAC lub skrypt do wykonania . Następnie zadanie automatycznie usuwa regułę zapory po zakończeniu.
. Następnie zadanie automatycznie usuwa regułę zapory po zakończeniu.
W innych sytuacjach nie można utworzyć tego typu wyjątków. W takich okolicznościach rozważ użycie własnego agenta potoku, który działa na maszynie wirtualnej lub innej jednostce obliczeniowej, którą kontrolujesz. Następnie można skonfigurować tego agenta według własnych potrzeb. Może on używać znanego adresu IP lub może być połączony z własną siecią wirtualną. W tym module nie omawiamy własnych agentów, ale udostępniamy linki do dodatkowych informacji na stronie Podsumowanie na końcu modułu.
Potok wdrażania
W następnym ćwiczeniu zaktualizujesz potok wdrażania, aby dodać nowe zadania w celu zbudowania składników bazy danych witryny, wdrożenia bazy danych i dodania danych początkowych.
