Konfigurowanie aplikacji i maszyn wirtualnych
Często tworzy się aplikacje i inny kod niestandardowy dla rozwiązania Azure. Aplikacje niestandardowe mogą obejmować witryny internetowe, interfejsy API i aplikacje w tle, które działają bez żadnej interakcji z człowiekiem. W tej lekcji dowiesz się, jak zaprojektować pipeline w celu budowania i wdrożenia aplikacji wraz z jej infrastrukturą.
Tworzenie aplikacji
Aby można było używać wielu typów aplikacji, należy skompilować lub skompilować. Proces kompilacji pobiera kod źródłowy aplikacji, wykonuje na niej sekwencję działań, a następnie tworzy zestaw plików, które można wdrożyć.
Proces kompilacji kompiluje kod źródłowy do plików binarnych lub plików wykonywalnych, ale zwykle obejmuje również inne działania:
- Kompresowanie plików graficznych, które są przesyłane użytkownikom Twojej witryny internetowej.
- linting kodu, aby sprawdzić, czy jest on zgodny z dobrymi rozwiązaniami w zakresie kodowania.
- Uruchamianie testów jednostkowych, które weryfikują działanie poszczególnych elementów Twojej aplikacji.
Oprócz tych kroków można również wykonać kroki, takie jak cyfrowe podpisywanie plików, aby upewnić się, że nie można ich modyfikować.
Jakakolwiek byłaby seria kroków, wynik procesu kompilacji jest wdrażalnym artefaktem . Artefakt jest zwykle zapisywany w systemie plików agenta potoku. Późniejsze etapy potoku muszą współpracować z artefaktem, aby wdrożyć go w środowiskach i testować go, gdy przechodzi przez bramy jakości zdefiniowane w definicji potoku.
Notatka
Być może znasz terminy ciągłej integracji i ciągłego wdrażania, czyli CI i CD. Proces kompilacji znajduje się w części potoku odpowiadającej za ciągłą integrację.
Artefakty potoku danych
Artefakty generowane w potoku nie są przechowywane w repozytorium Git. Pochodzą one z kodu źródłowego, ale nie są same w kodzie, dlatego nie należą do repozytorium kontroli źródła. Są one tworzone w systemie plików agenta potoku. Nowy agent jest tworzony dla każdego zadania w potoku, więc potrzebny jest sposób przekazywania plików między zadaniami i agentami.
artefakty potoków umożliwiają przechowywanie plików w usłudze Azure Pipelines i są skojarzone z konkretnym uruchomieniem potoku. Za pomocą wbudowanego zadania potoku PublishBuildArtifacts należy poinstruować usługę Azure Pipelines o opublikowaniu pliku lub folderu z systemu plików agenta jako artefaktu potoku:
- task: PublishBuildArtifacts@1
displayName: Publish folder as a pipeline artifact
inputs:
artifactName: my-artifact-name
pathToPublish: '$(Build.ArtifactStagingDirectory)/my-folder'
Właściwość pathToPublish to lokalizacja, która zawiera skompilowany kod lub pliki wyjściowe w systemie plików agenta potokowego. Zawartość znajdująca się w tej lokalizacji jest publikowana jako artefakt. Można określić pojedynczy plik lub folder.
Każdy artefakt ma nazwę, którą określasz przy użyciu właściwości zadania artifactName. Nazwa artefaktu służy do odwoływania się do niej w dalszej części potoku. Kolejne zadania potoku i etapy mogą pobierać artefakt, aby mogły z nim pracować, na przykład wdrożyć witrynę internetową na serwerze, który go hostuje:
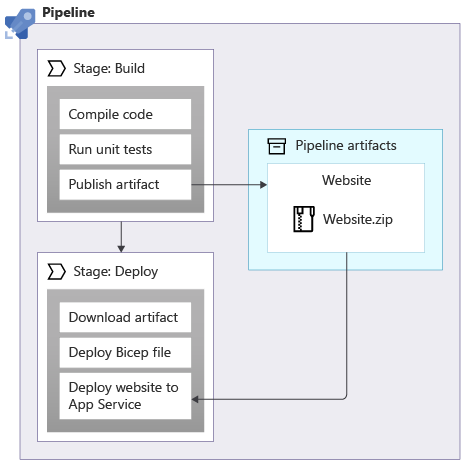
W przypadku korzystania z zadań wdrażania artefakty potoku są automatycznie pobierane domyślnie. Jeśli używasz zwykłych zadań, użyj zadania DownloadBuildArtifacts, aby pobrać artefakt potoku:
- task: DownloadBuildArtifacts@0
inputs:
buildType: current
downloadType: single
artifactName: my-artifact-name
downloadPath: '$(System.ArtifactsDirectory)'
Wdrażanie aplikacji
Proces kompilacji aplikacji generuje i publikuje wdrażalny artefakt. Późniejsze etapy pipeline'u wdrażają artefakt. Sposób wdrażania aplikacji zależy od usługi używanej do jej hostowania.
Wdrażanie w usłudze Azure App Service
Twoja firma używa usługi Azure App Service do hostowania swojej witryny internetowej. Aplikację usługi App Service można utworzyć i skonfigurować przy użyciu aplikacji Bicep. Jednak jeśli przychodzi czas na wdrożenie aplikacji, masz kilka opcji, aby skompilować aplikację w infrastrukturze hostingu. Te opcje są zarządzane w ramach płaszczyzny danych usługi App Service.
Najczęstszym podejściem jest użycie zadania AzureRmWebAppDeployment Azure Pipelines:
- task: AzureRmWebAppDeployment@4
inputs:
azureSubscription: MyServiceConnection
ResourceGroupName: MyResourceGroup
WebAppName: my-app-service
Package: '$(Pipeline.Workspace)/my-artifact-name/website.zip'
Aby wdrożyć aplikację w usłudze App Service, musisz podać kilka informacji. Te informacje obejmują grupę zasobów i nazwę zasobu aplikacji usługi App Service, która jest określana przy użyciu ResourceGroupName i WebAppName danych wejściowych. Jak się nauczyłeś/aś w poprzedniej jednostce, powinieneś/aś dodać dane wyjściowe do pliku Bicep i użyć zmiennej pipeline do propagowania nazwy aplikacji w całym pipeline. Należy również określić plik .zip z aplikacją do wdrożenia przy użyciu danych wejściowych Package, które są zwykle ścieżką do artefaktu potoku.
Usługa App Service ma własny system uwierzytelniania płaszczyzny danych używany do wdrożeń. Zadanie AzureRmWebAppDeployment automatycznie obsługuje proces uwierzytelniania:
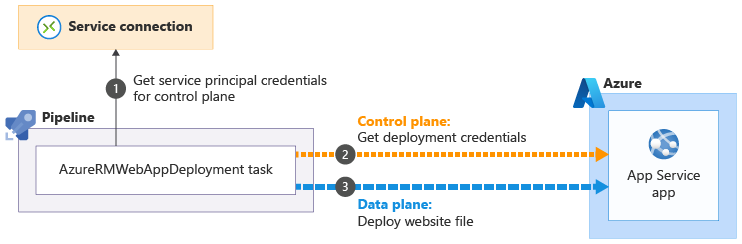
Zadanie AzureRmWebAppDeployment używa głównej usługi związanej z połączeniem usługi do automatycznego tworzenia i pobierania potrzebnych poświadczeń do wdrożenia
do automatycznego tworzenia i pobierania potrzebnych poświadczeń do wdrożenia . Następnie używa poświadczeń wdrożenia podczas komunikowania się z interfejsem API App Service obsługującym płaszczyznę danych
. Następnie używa poświadczeń wdrożenia podczas komunikowania się z interfejsem API App Service obsługującym płaszczyznę danych .
.
Usługa App Service udostępnia również kilka innych funkcji związanych z wdrażaniem, w tym miejsca wdrożenia . Sloty ułatwiają bezpieczne wdrażanie nowych wersji aplikacji bez przestojów. Ułatwiają one również przygotowanie i rozgrzewkę nowej wersji aplikacji przed wysłaniem do niej ruchu produkcyjnego. Nie używamy slotów w tym module, ale na stronie Podsumowania na końcu modułu udostępniamy link do dodatkowych informacji o nich.
Wdrażanie aplikacji w innych usługach platformy Azure
Platforma Azure oferuje wiele innych opcji hostowania aplikacji, z których każda ma własne podejście do wdrażania.
Usługa Azure Functions jest oparta na usłudze App Service i używa procesu wdrażania podobnego do opisanego wcześniej.
W przypadku wdrożenia na maszynie wirtualnej zwykle musisz nawiązać połączenie z wystąpieniem maszyny wirtualnej, aby zainstalować aplikację. Do organizowania wdrożenia na maszynach wirtualnych często trzeba używać wyspecjalizowanych narzędzi, takich jak Chef, Puppet lub Ansible.
Jeśli używasz platformy Kubernetes lub usługi Azure Kubernetes Service (AKS), użyj nieco innego podejścia do kompilowania i wdrażania rozwiązania. Po utworzeniu aplikacji potok tworzy obraz kontenera i publikuje go w rejestrze kontenerów , z którego następnie odczytuje klaster Kubernetes. Ponieważ rejestr kontenerów przechowuje skompilowaną aplikację, zazwyczaj nie używasz artefaktu potoku.
W tym module skupimy się na usłudze Azure App Service, aby zilustrować koncepcje potoku z nim związane. Na stronie Podsumowanie na końcu modułu udostępniamy linki do dodatkowych informacji na temat wdrażania w innych usługach hostingowych.
Testowanie aplikacji w ciągu
W poprzednim module przedstawiono wartość i znaczenie uruchamiania testów automatycznych z pipeliny. Podczas wdrażania aplikacji dobrą praktyką jest uruchomienie mechanizmu w pipeline, który wykonuje testy wywołujące kod aplikacji. Takie testy zmniejszają ryzyko, że błąd aplikacji lub wdrożenia może spowodować przestój. W bardziej zaawansowanych scenariuszach można nawet wykonać zestaw przypadków testowych dla aplikacji, takich jak wywoływanie interfejsów API lub przesyłanie i monitorowanie transakcji syntetycznej.
Wiele aplikacji implementuje punkty końcowe kontroli kondycji . Gdy punkt końcowy kontroli kondycji odbiera żądanie, wykonuje serię sprawdzeń na stronie internetowej, takich jak sprawdzenie, czy bazy danych i usługi sieciowe są osiągalne w środowisku aplikacji. Odpowiedź zwrócona przez witrynę wskazuje, czy aplikacja jest w dobrej kondycji. Deweloperzy mogą pisać i dostosowywać własne kontrole kondycji zgodnie z wymaganiami aplikacji. Jeśli aplikacja ma punkt końcowy sprawdzania kondycji zdrowotnej, często warto monitorować go z poziomu potoku po zakończeniu etapu wdrażania.
Potok wdrażania
W kolejnym ćwiczeniu zaktualizujesz przepływ wdrażania, aby dodać nowe zadania w celu zbudowania aplikacji Twojej witryny i wdrożenia jej w każdym środowisku.
