Wprowadzenie
Język SQL
SQL to skrót od języka Structured Query Language. Język SQL służy do komunikowania się z relacyjnymi bazami danych. Instrukcje SQL służą do wykonywania zadań takich jak aktualizowanie danych w bazie danych lub pobieranie danych z bazy danych. Na przykład instrukcja SQL SELECT służy do wykonywania zapytań względem bazy danych i zwracania zestawu wierszy danych. Niektóre typowe systemy zarządzania relacyjnymi bazami danych korzystające z języka SQL to Microsoft SQL Server, MySQL, PostgreSQL, MariaDB i Oracle.
Istnieje standard języka SQL zdefiniowany przez American National Standards Institute (ANSI). Każdy dostawca dodaje własne odmiany i rozszerzenia.
Ten moduł obejmuje następujące zagadnienia:
- Informacje o tym, czym jest usługa SQL i jak jest używana
- Identyfikowanie obiektów bazy danych w schematach
- Identyfikowanie typów instrukcji SQL
- Używanie instrukcji SELECT do wykonywania zapytań dotyczących tabel w bazie danych
- Praca z typami danych
- Obsługa list NUL
Transact-SQL
Podstawowe instrukcje SQL, takie jak SELECT, INSERT, UPDATE i DELETE , są dostępne niezależnie od systemu relacyjnej bazy danych, z którym pracujesz. Chociaż te instrukcje SQL są częścią standardu ANSI SQL, wiele systemów zarządzania bazami danych ma również własne rozszerzenia. Rozszerzenia te zapewniają funkcjonalność nieobjętą standardem SQL, a także obejmują obszary takie jak zarządzanie zabezpieczeniami i programowanie. Systemy baz danych firmy Microsoft, takie jak SQL Server, Azure SQL Database, Microsoft Fabric i inne, używają dialektu SQL o nazwie Transact-SQL lub T-SQL. Język T-SQL obejmuje rozszerzenia języka do pisania procedur składowanych i funkcji, które są kodem aplikacji przechowywanym w bazie danych i zarządzaniem kontami użytkowników.
SQL to język deklaratywny
Języki programowania można podzielić na kategorie proceduralne lub deklaratywne. Języki proceduralne umożliwiają zdefiniowanie sekwencji instrukcji, które komputer wykonuje w celu wykonania zadania. Języki deklaratywne umożliwiają opisywanie żądanych danych wyjściowych i pozostawienie szczegółów kroków wymaganych do utworzenia danych wyjściowych aparatu wykonywania.
Język SQL obsługuje składnię proceduralną, ale wykonywanie zapytań dotyczących danych przy użyciu języka SQL zwykle odbywa się według semantyki deklaratywnej. Użyjesz języka SQL, aby opisać żądane wyniki, a procesor zapytań aparatu bazy danych opracowuje plan zapytania, aby go pobrać. Procesor zapytań używa statystyk dotyczących danych w bazie danych i indeksach zdefiniowanych w tabelach w celu utworzenia dobrego planu zapytania.
Dane relacyjne
Język SQL jest najczęściej (choć nie zawsze) używany do wykonywania zapytań dotyczących danych w relacyjnych bazach danych. Relacyjna baza danych jest bazą danych, w której dane zostały zorganizowane w wielu tabelach (technicznie określanych jako relacje), z których każda reprezentuje określony typ jednostki (np. klient, produkt lub zamówienie sprzedaży). Atrybuty tych jednostek (na przykład nazwa klienta, cena produktu lub data zamówienia sprzedaży) są definiowane jako kolumny lub atrybuty tabeli, a każdy wiersz w tabeli reprezentuje wystąpienie typu jednostki (na przykład określonego klienta, produktu lub zamówienia sprzedaży).
Tabele w bazie danych są powiązane ze sobą przy użyciu kolumn kluczy , które jednoznacznie identyfikują określoną reprezentowaną jednostkę. Klucz podstawowy jest definiowany dla każdej tabeli, a odwołanie do tego klucza jest definiowane jako klucz obcy w dowolnej powiązanej tabeli. Jest to łatwiejsze do zrozumienia, patrząc na przykład:
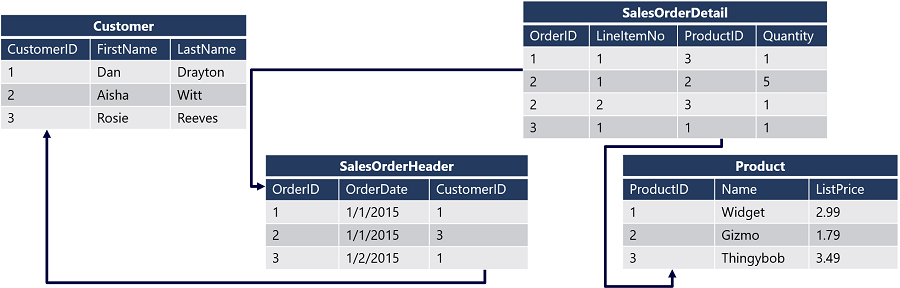
Diagram przedstawia relacyjną bazę danych zawierającą cztery tabele:
- Klient
- SalesOrderHeader
- SalesOrderDetail
- Produkt
Każdy klient jest identyfikowany przez unikatowe pole CustomerID — to pole jest kluczem podstawowym tabeli Customer (Klient). Tabela SalesOrderHeader ma klucz podstawowy o nazwie OrderID w celu zidentyfikowania każdego zamówienia, a także zawiera klucz obcy CustomerID , który odwołuje się do klucza podstawowego w tabeli Klient , aby zidentyfikować, który klient jest skojarzony z każdym zamówieniem. Dane dotyczące poszczególnych elementów w zamówieniu są przechowywane w tabeli SalesOrderDetail , która zawiera złożony klucz podstawowy, który łączy identyfikator OrderID w tabeli SalesOrderHeader z wartością LineItemNo . Kombinacja tych wartości jednoznacznie identyfikuje element wiersza. Pole OrderID jest również używane jako klucz obcy, aby wskazać kolejność, do której należy element wiersza, pole ProductID jest używane jako klucz obcy do klucza podstawowego ProductID tabeli Product, aby wskazać, który produkt został uporządkowany.
Przetwarzanie oparte na zestawie
Teoria zestawów jest jednym z matematycznych podstaw modelu relacyjnego zarządzania danymi i ma podstawowe znaczenie dla pracy z relacyjnymi bazami danych. Chociaż możesz zapisywać zapytania w języku T-SQL bez dokładnego zrozumienia zestawów, może w końcu mieć trudności z pisaniem niektórych bardziej złożonych typów instrukcji, które mogą być potrzebne w celu uzyskania optymalnej wydajności.
Bez zagłębienia się w matematykę teorii zestaw można traktować jako "zbiór określonych, odrębnych obiektów uważanych za całość". Jeśli chodzi o bazy danych programu SQL Server, można traktować zestaw jako kolekcję odrębnych obiektów zawierających zero lub więcej elementów członkowskich tego samego typu. Na przykład tabela Customer (Klient) reprezentuje zestaw: w szczególności zestaw wszystkich klientów. Zobaczysz, że wyniki instrukcji SELECT również tworzą zestaw.
Gdy dowiesz się więcej na temat instrukcji zapytań języka T-SQL, ważne jest, aby zawsze myśleć o całym zestawie, a nie o poszczególnych elementach członkowskich. Ten sposób myślenia lepiej zapewni ci pisanie kodu opartego na zestawie, zamiast myśleć o jednym wierszu naraz. Praca z zestawami wymaga myślenia w zakresie operacji, które występują "naraz" zamiast jednego naraz.
Jedną z ważnych cech, które należy zwrócić uwagę na teorię zestawów, jest to, że nie ma żadnej specyfikacji dotyczącej kolejności elementów członkowskich zestawu. Ten brak kolejności dotyczy tabel relacyjnej bazy danych. Nie istnieje pojęcie pierwszego wiersza, drugiego wiersza lub ostatniego wiersza. Dostęp do elementów można uzyskać (i pobrać) w dowolnej kolejności. Jeśli chcesz zwrócić wyniki w określonej kolejności, musisz ją jawnie określić przy użyciu klauzuli ORDER BY w zapytaniu SELECT.