Używanie usługi Azure Data Lake Storage Gen2 w obciążeniach analizy danych
Usługa Azure Data Lake Store Gen2 to technologia umożliwiająca korzystanie z wielu przypadków użycia analizy danych. Przyjrzyjmy się kilku typowym typom obciążenia analitycznego i zidentyfikujmy, jak usługa Azure Data Lake Storage Gen2 współpracuje z innymi usługami platformy Azure, aby je obsługiwać.
Przetwarzanie i analiza danych big data
Scenariusze danych big data zwykle odnoszą się do obciążeń analitycznych, które obejmują ogromne ilości danych w różnych formatach, które muszą być przetwarzane z dużą szybkością — tzw. "trzy maszyny wirtualne". Usługa Azure Data Lake Storage Gen 2 zapewnia skalowalny i bezpieczny rozproszony magazyn danych, w którym usługi danych big data, takie jak Azure Synapse Analytics, Azure Databricks i Azure HDInsight, mogą stosować struktury przetwarzania danych, takie jak Apache Spark, Hive i Hadoop. Rozproszony charakter magazynu i obliczeń przetwarzania umożliwia równoległe wykonywanie zadań, co zapewnia wysoką wydajność i skalowalność nawet podczas przetwarzania ogromnych ilości danych.
Magazynowanie danych
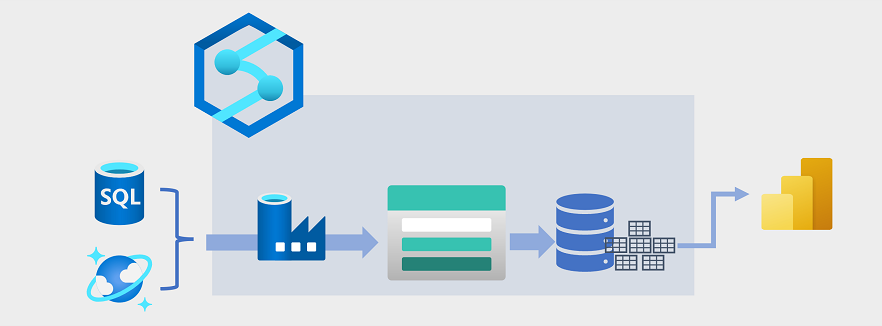
Magazynowanie danych ewoluowało w ostatnich latach, aby zintegrować duże ilości danych przechowywanych jako pliki w usłudze Data Lake z tabelami relacyjnymi w magazynie danych. W typowym przykładzie rozwiązania do magazynowania danych dane są wyodrębniane z operacyjnych magazynów danych, takich jak baza danych Azure SQL Database lub Azure Cosmos DB, i przekształcane w struktury bardziej odpowiednie dla obciążeń analitycznych. Często dane są etapowane w usłudze Data Lake w celu ułatwienia przetwarzania rozproszonego przed załadowaniem do relacyjnego magazynu danych. W niektórych przypadkach magazyn danych używa tabel zewnętrznych do definiowania warstwy relacyjnych metadanych na plikach w usłudze Data Lake i tworzenia hybrydowej architektury "data lakehouse" lub "lake database". Magazyn danych może następnie obsługiwać zapytania analityczne na potrzeby raportowania i wizualizacji.
Istnieje wiele sposobów implementowania tego rodzaju architektury magazynowania danych. Na diagramie przedstawiono rozwiązanie, w którym potoki hostów usługi Azure Synapse Analytics do wykonywania procesów wyodrębniania, przekształcania i ładowania (ETL) przy użyciu technologii azure Data Factory. Te procesy wyodrębniają dane z operacyjnych źródeł danych i ładują je do magazynu data lake hostowanego w kontenerze usługi Azure Data Lake Storage Gen2. Dane są następnie przetwarzane i ładowane do magazynu danych relacyjnych w dedykowanej puli SQL usługi Azure Synapse Analytics, z której mogą obsługiwać wizualizacje danych i raportowanie przy użyciu usługi Microsoft Power BI.
Analiza danych w czasie rzeczywistym
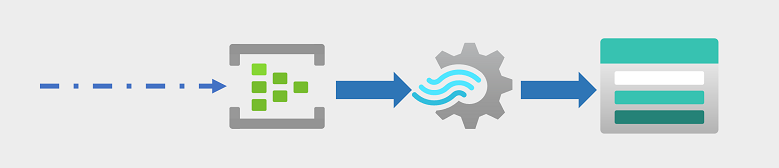
Coraz częściej firmy i inne organizacje muszą przechwytywać i analizować bezterminowe strumienie danych oraz analizować je w czasie rzeczywistym (lub niemal w czasie rzeczywistym). Te strumienie danych mogą być generowane na podstawie połączonych urządzeń (często nazywanych internetem rzeczy lub urządzeniami IoT ) lub z danych generowanych przez użytkowników na platformach mediów społecznościowych lub innych aplikacjach. W przeciwieństwie do tradycyjnych obciążeń przetwarzania wsadowego dane przesyłane strumieniowo wymagają rozwiązania, które umożliwia przechwytywanie i przetwarzanie nieograniczonego strumienia zdarzeń danych w miarę ich występowania.
Zdarzenia przesyłania strumieniowego są często przechwytywane w kolejce do przetwarzania. Istnieje wiele technologii, których można użyć do wykonania tego zadania, w tym usługi Azure Event Hubs, jak pokazano na ilustracji. W tym miejscu dane są przetwarzane, często w celu agregowania danych w oknach czasowych (na przykład w celu zliczenia liczby wiadomości w mediach społecznościowych przy użyciu danego tagu co pięć minut lub obliczenia średniego odczytu czujnika połączonego z Internetem na minutę). Usługa Azure Stream Analytics umożliwia tworzenie zadań, które wysyłają zapytania i agregują dane zdarzeń w miarę ich nadejścia, i zapisują wyniki w ujściu danych wyjściowych. Jednym z takich ujścia jest usługa Azure Data Lake Storage Gen2; z miejsca, w którym przechwycone dane w czasie rzeczywistym można analizować i wizualizować.
Nauka o danych i uczenie maszynowe

Nauka o danych obejmuje statystyczną analizę dużych ilości danych, często przy użyciu narzędzi takich jak Apache Spark i języków skryptów, takich jak Python. Usługa Azure Data Lake Storage Gen 2 udostępnia wysoce skalowalny magazyn danych oparty na chmurze dla ilości danych wymaganych w obciążeniach nauki o danych.
Uczenie maszynowe to obszar nauki o danych, który zajmuje się trenowanie modeli predykcyjnych. Trenowanie modelu wymaga ogromnych ilości danych i możliwości wydajnego przetwarzania tych danych. Azure Machine Learning to usługa w chmurze, w której analitycy danych mogą uruchamiać kod języka Python w notesach przy użyciu dynamicznie przydzielanych rozproszonych zasobów obliczeniowych. Obliczenia przetwarzają dane w kontenerach usługi Azure Data Lake Storage Gen2 w celu trenowania modeli, które następnie można wdrożyć jako produkcyjne usługi internetowe w celu obsługi obciążeń analitycznych predykcyjnych.