Jak działa usługa Azure HDInsight
Tutaj dowiesz się, jak działa usługa Azure HDInsight. Dowiesz się więcej o następujących składnikach i sposobie ich dopasowania w celu zapewnienia kontroli danych i zarządzania nimi:
- Apache Hadoop
- Magazyn usługi HDInsight
- Przetwarzanie usługi HDInsight
Co to jest apache Hadoop?
Apache Hadoop to rozproszony w chmurze system przetwarzania danych w rdzeniu usługi HDInsight. Zawiera trzy składniki, które opisano w poniższej tabeli:
| Składnik Apache Hadoop | Opis |
|---|---|
| System plików HDFS | Rozproszony system plików Apache Hadoop (HDFS) udostępnia magazyn dla systemu Hadoop. |
| PRZĘDZA | Składnik YARN (Apache Hadoop Yet Another Resource Negotiator) zapewnia przetwarzanie systemu. |
| MapReduce | MapReduce to model programowania, który umożliwia przetwarzanie i analizowanie danych. |
W jaki sposób składniki współdziałają?
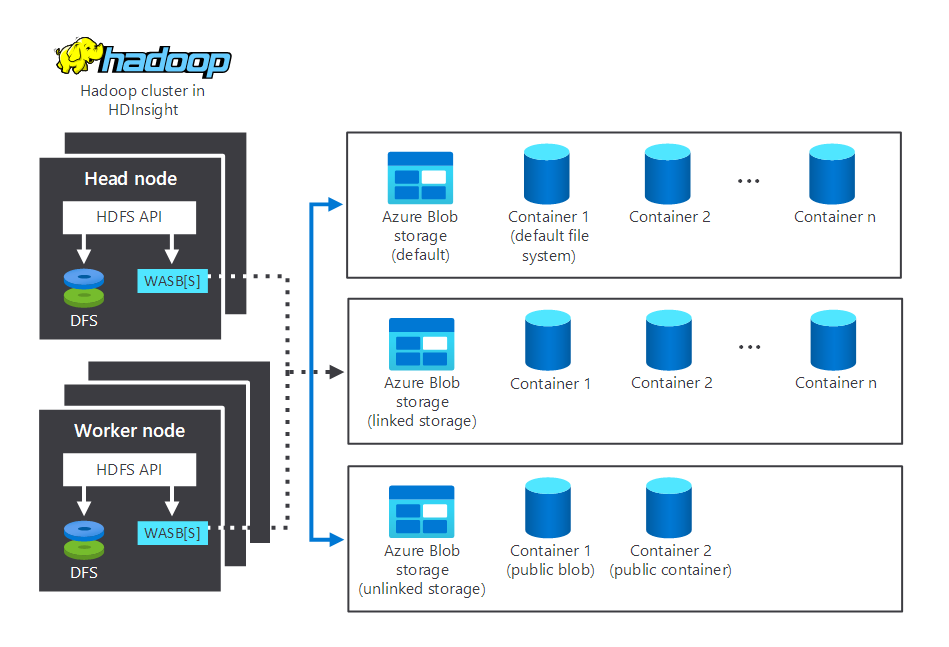
Na poniższym diagramie przedstawiono składniki magazynu i przetwarzania wchodzące w interakcje w typowym klastrze hadoop usługi HDInsight. Ilustruje on następujące składniki:
- Węzeł główny i węzły robocze, które wykonują przetwarzanie.
- Wiele centrów magazynów danych obiektowych (WASB) usługi Microsoft Azure Storage, znajdujących się w obrębie węzłów. System plików HDFS współdziała z tymi kontenerami.
- Wiele domyślnych, połączonych i niepołączonych kontenerów. Są one dostępne dla dwóch węzłów.
Teraz sprawdźmy, jak działa magazyn i przetwarzanie.
Jak działa magazyn?
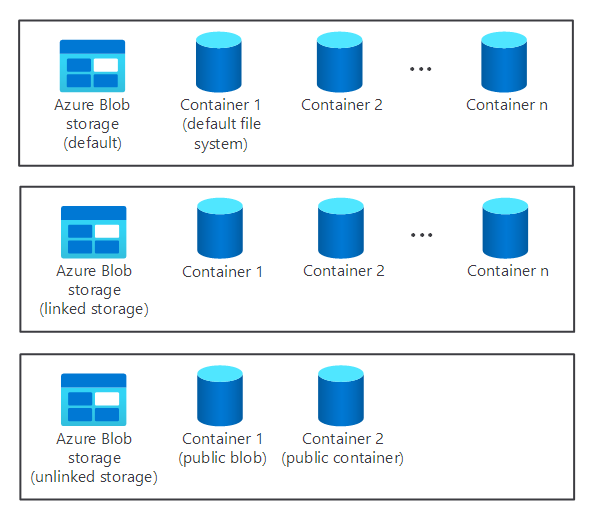
Składnik magazynu klastra nie jest tworzony automatycznie podczas tworzenia klastra usługi HDInsight. Zamiast tego jest dostarczany przez system zgodny z systemem plików HDFS, taki jak Azure Storage lub Azure Data Lake.
Istnieją korzyści wynikające z oddzielenia składnika magazynu klastra od składnika przetwarzania. Można na przykład bezpiecznie usunąć wszystkie klastry usługi HDInsight używane tylko do obliczeń bez obaw o utratę danych. Podczas dodawania klastra usługi HDInsight należy zdefiniować domyślny system plików.
Ważny
W przypadku usługi Azure Storage należy określić kontener obiektów blob jako domyślny system plików.
Zapewnienie domyślnego systemu plików gwarantuje, że usługa HDInsight może rozpoznać względne odwołania do plików podczas wyszukiwania plików.
Napiwek
Jeśli chcesz zwiększyć dostępny magazyn, możesz połączyć i odłączyć dodatkowe systemy plików zgodnie z potrzebami.
Jak działa przetwarzanie?
Podczas przetwarzania danych składnik obliczeniowy klastra Hadoop w usłudze HDInsight dzieli się na dwa obszary logiczne. W poniższej tabeli opisano te dwa obszary:
| Składnik | Opis |
|---|---|
| Węzeł główny | Węzeł główny akceptuje żądania klientów, zarządza nimi i przekazuje je do węzłów roboczych. |
| Węzeł roboczy | Węzły robocze przetwarzają dane. |
Notatka
Węzeł główny jest czasami nazywany węzłem nadrzędnym.
Większość klastrów zawiera dwa węzły główne, w tym:
- Aktywny węzeł główny, który zarządza połączeniami klientów.
- Pasywny węzeł główny, który zapewnia odporność, jeśli aktywny węzeł przejdzie w tryb offline.
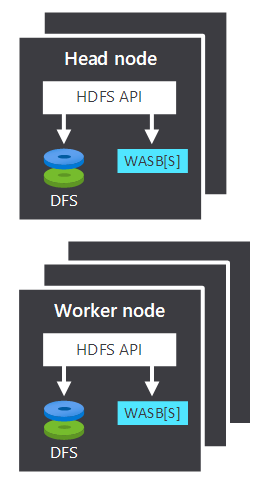
Węzły główne i robocze mogą łączyć się bezpośrednio z lokalnie dołączonym systemem plików HDFS lub uzyskiwać dostęp do danych przechowywanych w usłudze Azure Blob lub Azure Data Lake. To, jakie dane są zarządzane, zależy od dwóch czynników:
- Jak model programowania MapReduce zdefiniował sposób pracy z danymi
- Jak węzeł główny przydziela pracę
Co robi usługa YARN?
YARN wykonuje zarządzanie zasobami w klastrze HDInsight. Podczas przetwarzania danych ta usługa zarządza zasobami i planowaniem zadań.
Usługa YARN znajduje się między systemem plików HDFS a systemem obliczeniowym klastra usługi HDInsight. Współdziała on z węzłem głównym, aby ułatwić dystrybucję zadania między węzłami roboczymi klastra. Pomaga to zapewnić równoległe działanie zadań przetwarzania danych.