Co to jest usługa Azure HDInsight?
Przyjrzyjmy się funkcjom i użyciu usługi HDInsight. To omówienie pomoże Ocenić, czy usługa HDInsight spełnia wymagania organizacji.
What is big data?
Termin dane big data opisuje ogromne ilości ustrukturyzowanych i nieustrukturyzowanych danych zbieranych przez organizacje. Te dane mogą być bardzo przydatne dla organizacji. W szczególności jeśli organizacja może analizować dane pod kątem szczegółowych informacji, lepiej jest podejmować decyzje. W rezultacie te decyzje mogą pomóc organizacji w udanych działaniach. Na przykład analiza danych big data może umożliwić organizacji komercyjnej rozpoznawanie nawyków klientów, co może prowadzić do zwiększenia sprzedaży.
Definicja usługi Azure HDInsight
Azure HDInsight to w pełni zarządzana, oparta na chmurze usługa analizy typu open source dla przedsiębiorstw. Usługa HDInsight umożliwia kontrolowanie danych big data i zarządzanie nimi. HDInsight:
To dystrybucja w chmurze składników platformy Hadoop.
Ułatwia, szybsze i bardziej ekonomiczne przetwarzanie ogromnych ilości danych.
Obsługuje korzystanie z platform typu open source, takich jak:
- Hadoop
- Apache Spark
- Apache Hive
- Apache Kafka
Uwaga
Za pomocą tych platform można realizować rozmaite scenariusze związane z wyodrębnianiem, transformacją i ładowaniem danych, magazynowaniem danych, uczeniem maszynowym oraz Internetem rzeczy (IoT).
Usługa HDInsight zapewnia kilka korzyści dla organizacji, które pracują z danymi big data. To:
Open source: umożliwia tworzenie zoptymalizowanych klastrów dla różnych platform typu open source.
Niezawodne: zapewnia kompleksową umowę SLA dla wszystkich obciążeń produkcyjnych.
Skalowalne: umożliwia skalowanie obciążeń w odpowiedzi na zmiany zapotrzebowania.
Napiwek
Tworząc klastry na żądanie, można zmniejszyć koszty. Płacisz wyłącznie za rzeczywiste użycie.
Zabezpieczanie: umożliwia ochronę zasobów danych przedsiębiorstwa za pomocą integracji z:
- Azure Virtual Network
- Technologie szyfrowania na platformie Azure
- Microsoft Entra ID
Zgodne: spełnia popularne standardy zgodności z branży i instytucji rządowych.
Monitorowane: integruje się z dziennikami usługi Azure Monitor, aby zapewnić jeden interfejs. Monitoruj wszystkie klastry przy użyciu jednego interfejsu.
Jak usługa HDInsight może pomóc w pracy z danymi big data
Usługi HDInsight można używać w wielu scenariuszach korzystających z przetwarzania danych big data. Dane mogą być następujące:
- Dane historyczne: te dane są już zbierane i przechowywane.
- Dane w czasie rzeczywistym: te dane są przesyłane strumieniowo bezpośrednio ze źródła.
Następujące kategorie zawierają podsumowanie scenariuszy przetwarzania dla tych danych:
- Przetwarzanie wsadowe
- Magazynowanie danych
- IoT
- Nauka o danych
- Połączenie hybrydowe
Przyjrzyjmy się bliżej tym kategoriom.
Przetwarzanie wsadowe
Organizacje używają zadań przetwarzania wsadowego do przygotowania danych big data do dalszej analizy. Zazwyczaj ten proces obejmuje trzy etapy:
- Odczytywanie plików danych źródłowych z heterogenicznych źródeł danych.
- Przetwarzanie danych.
- Zapisywanie danych w skalowalnym magazynie.
Uwaga
Ten proces jest często określany jako ETL.
Przekształcone dane można używać do magazynowania danych lub nauki o danych.
Napiwek
Istotnym wymaganiem dla etl jest skalowanie obliczeń w poziomie. Umożliwia to przetwarzanie dużych ilości danych.
Magazynowanie danych
Magazyn danych udostępnia organizacji gdzieś przechowywanie danych big data podczas oczekiwania na ich przeanalizowanie. Magazynowanie danych umożliwia:
- Przechowywanie danych.
- Przygotuj dane do analizy.
- Podaj przygotowane dane w formacie ustrukturyzowanym. Następnie możesz wykonywać zapytania dotyczące danych przy użyciu narzędzi analitycznych.
Na poniższym diagramie przedstawiono sposób zbierania i przechowywania danych z kilku źródeł w usłudze Apache Hadoop w usłudze HDInsight. Apache Spark i Apache Hive przygotowują i analizują dane. Na koniec dane są modelowane do użycia z narzędziami analizy biznesowej (BI). Usługa Power BI jest używana do wizualizacji danych.
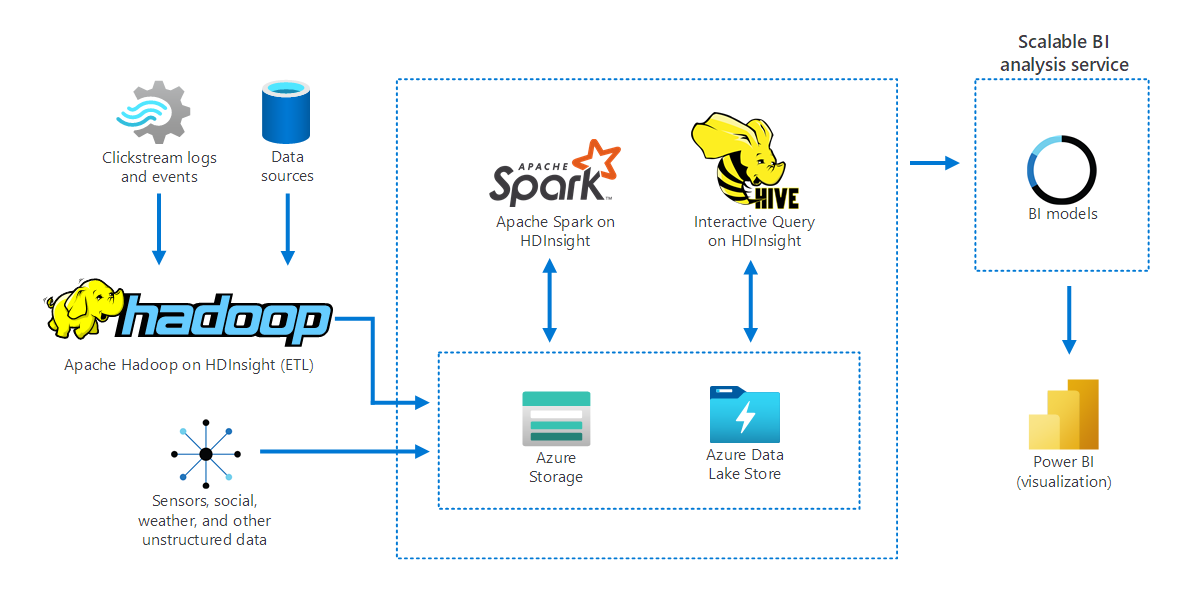
Składniki w tym scenariuszu obejmują:
- Apache Spark to platforma przetwarzania równoległego. Obsługuje przetwarzanie w pamięci, co pomaga zwiększyć wydajność aplikacji analitycznych big data.
- Apache Hive w usłudze HDInsight to system magazynu danych dla platformy Apache Hadoop. Usługa Hive umożliwia podsumowywanie, wykonywanie zapytań i analizę danych. Tych składników można używać do wykonywania zapytań w skali petabajtów na danych ustrukturyzowanych i nieustrukturyzowanych w dowolnym formacie.
Napiwek
Zapytania Hive są pisane w języku HiveQL, języku zapytań podobnym do języka SQL.
Internet rzeczy
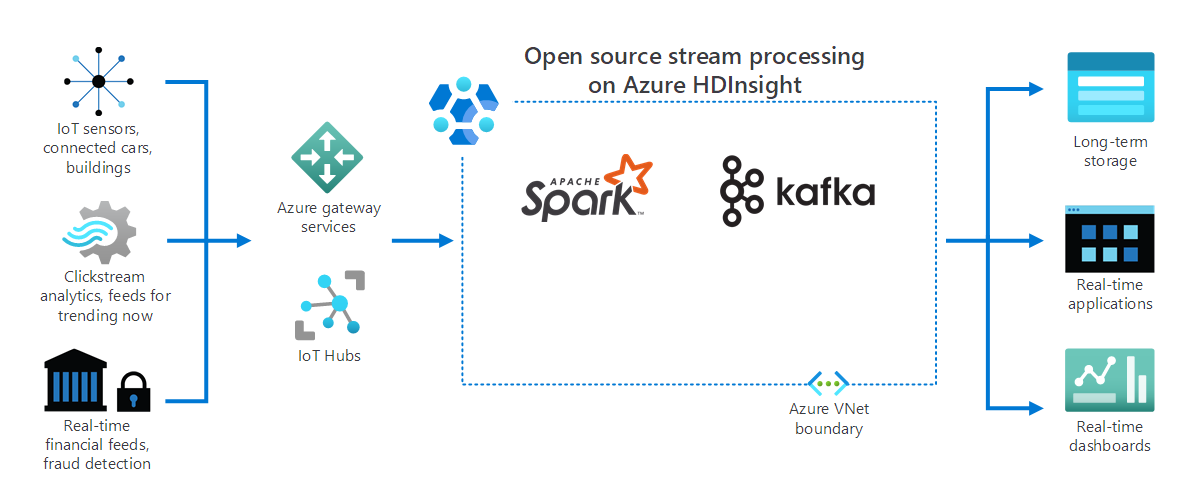
Jak pokazano na poniższym diagramie, usługa HDInsight przetwarza dane przesyłane strumieniowo w czasie rzeczywistym z różnych urządzeń i czujników. W tym przykładzie kilka platform typu open source zapewnia przetwarzanie strumienia, w tym platformy Apache Spark i Apache Kafka.
Usługi bramy platformy Azure i centra IoT kierują dane z różnych źródeł do tych struktur. Następnie struktury przetwarzają dane i przechodzą do:
- Magazyn długoterminowy.
- Aplikacje w czasie rzeczywistym.
- Pulpity nawigacyjne w czasie rzeczywistym.
Nauka o danych
Usługi HDInsight można używać do wykonywania typowych zadań nauki o danych, takich jak:
- Pozyskiwanie danych.
- Inżynieria cech.
- Modelowania.
- Ocena modelu.
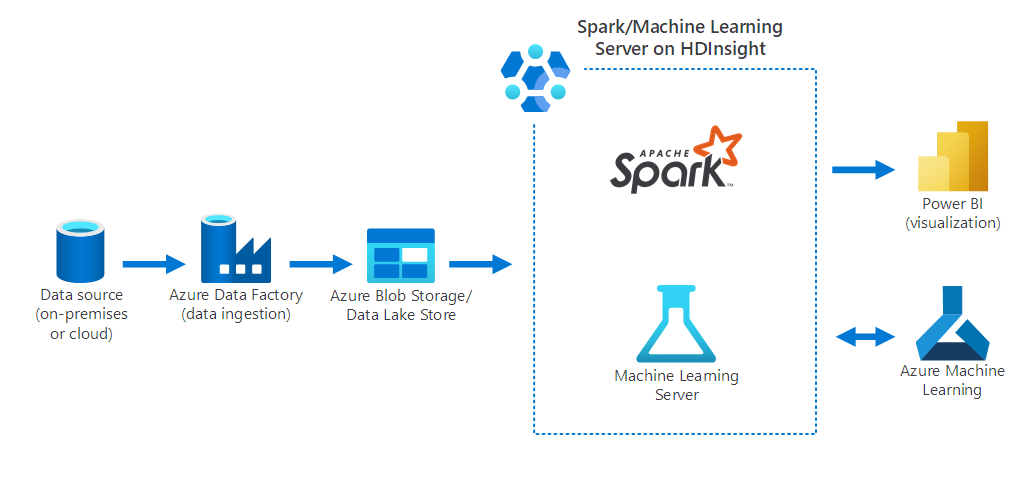
Na poniższym diagramie przedstawiono scenariusz nauki o danych, w którym:
- Dane są zbierane z lokalnego źródła danych przy użyciu usługi Azure Data Factory.
- Pozyskane dane są następnie przechowywane w usłudze Azure Storage (Azure Blob Storage lub Data Lake Store).
- Platforma Azure Spark w usłudze HDInsight przetwarza i przygotowuje dane do usługi Azure Machine Learning. Dane są również wizualizowane przy użyciu usługi Power BI.
Połączenie hybrydowe
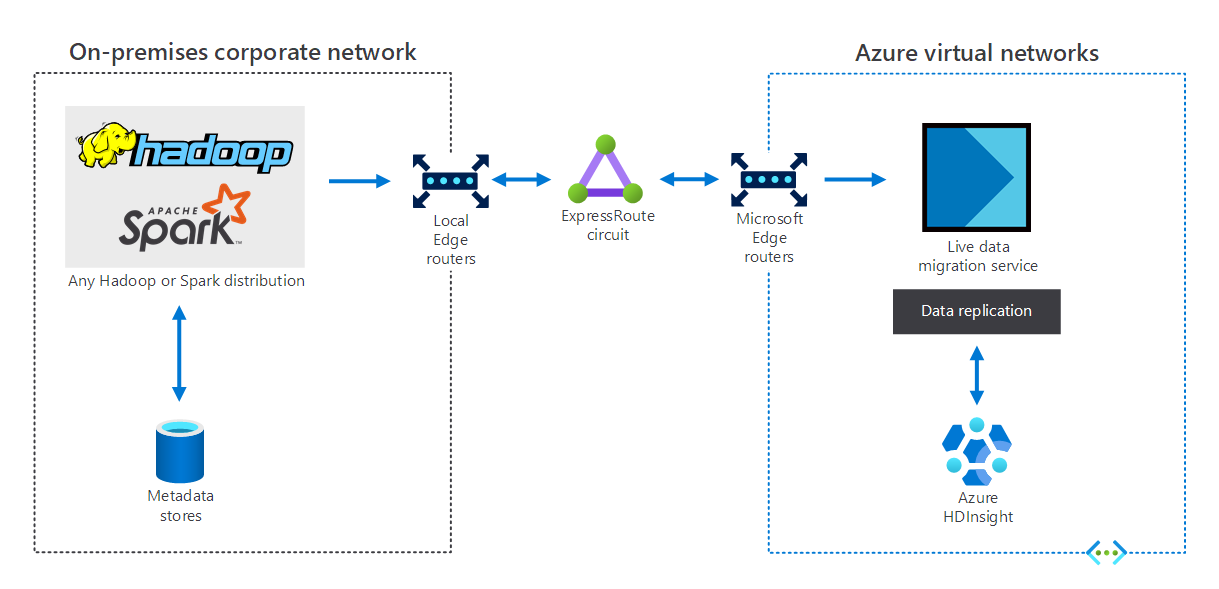
Organizacje, które mają lokalną infrastrukturę danych big data, mogą używać usługi HDInsight do rozszerzania na platformę Azure. Zapewnia to korzyści z zaawansowanych funkcji analizy w chmurze platformy Azure. Na poniższym diagramie przedstawiono scenariusz hybrydowy, w którym:
- Lokalna infrastruktura danych big data składa się z magazynów metadanych oraz dystrybucji Hadoop lub Spark na lokalnych maszynach wirtualnych.
- Obwód usługi Azure ExpressRoute łączy lokalne środowisko sieciowe firmowe z sieciami wirtualnymi platformy Azure.
- Migracja danych na żywo dla platformy Azure replikuje dane odebrane ze środowiska lokalnego do usługi HDInsight.