Jak działa usługa HDInsight
HDInsight to rozproszony system przetwarzania danych w chmurze, który jest domyślnie wysoce dostępny i bezpieczny. W centrum tego systemu jest Apache Hadoop. Platforma Apache Hadoop zawiera dwa podstawowe składniki: rozproszony system plików Apache Hadoop (HDFS), który jest używany do magazynowania, oraz negocjator zasobów Apache Hadoop (YARN), który zapewnia przetwarzanie. Ponadto jest to prosty model programowania MapReduce, który umożliwia przetwarzanie i analizowanie danych. Korzyści wynikające z używania usługi MapReduce są łatwe do skonfigurowania i można kontrolować koszty za pomocą funkcji skalowania automatycznego.
Storage
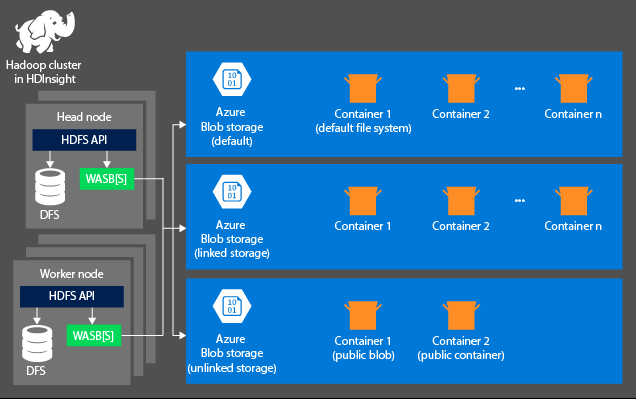
Aspekt magazynu nie jest tworzony automatycznie podczas aprowizacji klastra usługi HDInsight. Zamiast tego jest on dostarczany przez system zgodny z systemem plików HDFS, taki jak Azure Storage lub Azure Data Lake. Oddzielenie magazynu z warstwy przetwarzania umożliwia bezpieczne usuwanie klastrów usługi HDInsight używanych do obliczeń bez utraty danych użytkownika. Podczas dodawania klastra usługi HDInsight należy zdefiniować domyślny system plików. W razie potrzeby można łączyć i odłączać systemy plików w celu zwiększenia rozmiaru magazynu.
Poniższe informacje są specyficzne dla usługi HDInsight 3.6 lub nowszej. Podczas procesu tworzenia klastra usługi HDInsight można wybrać usługę Azure Storage lub Azure Data Lake Storage Gen2 jako domyślny system plików z kilkoma wyjątkami. Zapewnienie domyślnego systemu plików gwarantuje, że względne odwołania do plików można rozpoznać podczas wyszukiwania plików. W przypadku usługi Azure Storage należy określić kontener obiektów blob jako domyślny system plików.
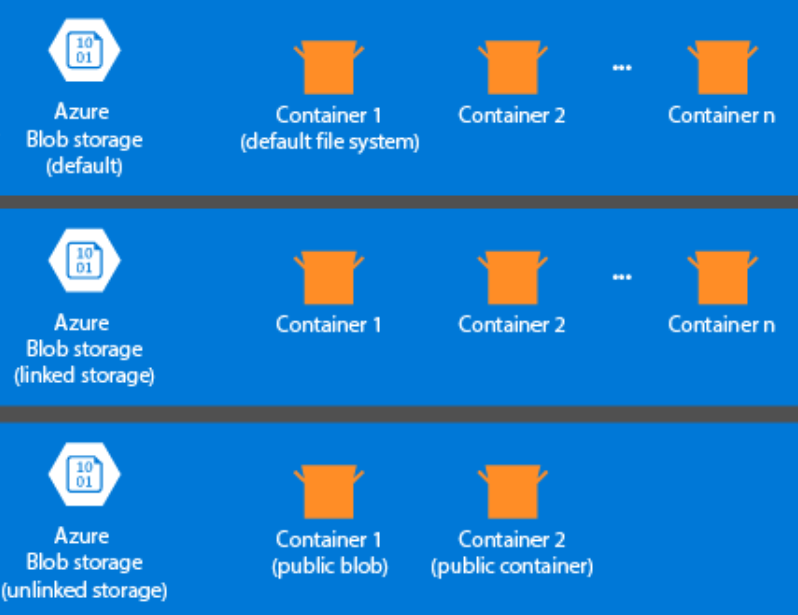
Większość konfiguracji używa usługi Azure Data Lake Storage Gen2. Ten typ instalacji korzysta z podstawowych funkcji systemu plików, które są zgodne z integracją platformy Hadoop, firmą Microsoft Entra i listami kontroli dostępu opartymi na systemie POSIX(ACL). Usługę Azure Blob Storage można używać do zapewnienia zgodności z poprzednimi wersjami, ale zdecydowanie zaleca się korzystanie z usługi Azure Data Lake Storage Gen2 wszędzie tam, gdzie to możliwe.
Przetwarzanie
Podczas przetwarzania danych aspekt obliczeniowy klastra Hadoop w usłudze HDInsight jest podzielony na dwa obszary logiczne. Węzły główne (główne) i węzły procesu roboczego. Węzeł główny (główny) jest odpowiedzialny za akceptowanie żądań klientów i zarządzanie nimi, a następnie przekazywanie żądania do węzłów procesu roboczego w celu wykonania przetwarzania danych. Zazwyczaj istnieją dwa węzły główne. Aktywny węzeł główny, który będzie zarządzać połączeniami klienta. Drugi pasywny węzeł główny, który zapewnia odporność w przypadku, gdy podstawowy powinien stać się w trybie offline.
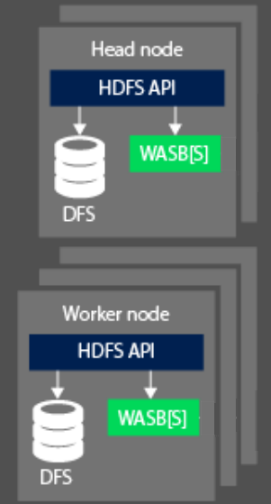
Węzeł roboczy jest odpowiedzialny za przetwarzanie danych, które zostały do niego przypisane przez węzeł główny. Zarządzane dane zależą od sposobu, w jaki model programowania MapReduce zdefiniował sposób pracy z danymi i jak węzeł główny przydziela pracę. Węzeł Główny i Roboczy mogą łączyć się bezpośrednio z lokalnie dołączonym rozproszonym systemem plików (DFS) lub uzyskiwać dostęp do danych przechowywanych w usłudze Azure Blob lub Azure Data Lake.
Z punktu widzenia systemu operacyjnego możliwości zarządzania zasobami klastra usługi HDInsight są wykonywane przez usługę YARN. Ta usługa zarządza zasobami i planowaniem zadań, które są podejmowane podczas przetwarzania danych. Znajduje się on między systemem plików HDFS a systemem obliczeniowym klastra usługi HDInsight. Usługa współpracuje z innymi technologiami systemu operacyjnego, aby upewnić się, że zasoby do przetwarzania zadania usługi HDInsight są dostępne. Usługa YARN współpracuje z węzłem głównym w celu dystrybucji zadania między węzłami roboczymi klastra w celu zapewnienia równoległości zadań przetwarzania danych.
HdFS, YARN i MapReduce to trzy podstawowe usługi wymagane dla usługi Hadoop w usłudze HDInsight. Typowe jest użycie dodatkowych technologii systemu operacyjnego, aby ułatwić tworzenie rozwiązania. Na przykład można użyć programu Hive jako warstwy abstrakcji. Jeden, który znajduje się na szczycie mapReduce, dzięki czemu można napisać konstrukcje języka typu SQL w celu wykonywania przetwarzania i analizy danych ad hoc. Możesz też użyć narzędzia Apache Ambari do monitorowania w klastrze usługi HDInsight.