Co to jest skalowalność?
W świecie biznesu wzrost może być korzystny. Jednak gdy wzrost występuje zbyt szybko, a gdy nie zostały odpowiednio przygotowane, wzrost może powodować problemy. Jednym z tych problemów jest wzrost niezawodności aplikacji i usług, które nie zostały zaprojektowane do obsługi dużego wzrostu ruchu.
Dla klientów i użytkowników awaria jest awarią. Nie wiedzą ani interesuje ich, że nie są w stanie uzyskać dostępu do witryny z powodu wadliwego kodu lub dlatego, że zbyt wiele innych osób próbuje użyć idealnie zakodowanej witryny w tym samym czasie.
Skalowalność to możliwość adaptacji do zwiększonych wymagań lub zmieniających się potrzeb. Twoje aplikacje i usługi muszą być w stanie obsłużyć większe obciążenie, aby poradzić sobie ze wzrostem. Skalowalne aplikacje są w stanie obsłużyć większą liczbę żądań w czasie bez negatywnego wpływu na dostępność lub wydajność.
W tej lekcji zapoznasz się z relacją między skalowalnością a niezawodnością, znaczeniem planowania pojemności w osiąganiu skalowalności oraz krótko przejrzyj niektóre podstawowe pojęcia i terminy związane ze skalowaniem.
Relacja skalowalności/niezawodności
Dobra wiadomość jest taka, że aplikacja, która stanie się bardziej skalowalna, może też być bardziej niezawodna. Jeśli na przykład system autoskaluje, biorąc pod uwagę awarię składnika na jednej maszynie wirtualnej, usługa skalowania automatycznego aprowizuje inne wystąpienie w celu spełnienia minimalnych wymagań dotyczących liczby maszyn wirtualnych. System staje się bardziej niezawodny. W innym przykładzie używasz usługi wyższego poziomu, takiej jak Azure Storage, która jest z założenia skalowalna. Jeśli masz problem z magazynem, usługa została skompilowana w taki sposób, aby dane były replikowane.
Oto analogia: Pomyśl o rampach ułatwień dostępu, które często widzisz poza budynkami, które zostały początkowo zaprojektowane tak, aby pomieścić ludzi na wózkach inwalidzkich. Służą one do tego celu. Ale są one również używane przez rodziców z dziećmi w wózkach lub wagonach, lub przez małe dzieci, dla których schody są zbyt głębokie lub wysokie. To użycie jest dodatkową korzyścią.
Niezawodność jest często dodatkową korzyścią skalowalności. Jeśli projektujesz systemy tak, aby były skalowalne, prawdopodobnie będą one również bardziej niezawodne.
Planowanie skalowalności i pojemności
Planowanie pojemności obejmuje określenie zasobów potrzebnych do spełnienia zarówno obecnych, jak i przyszłych wymagań. To planowanie można wykonać przez przeanalizowanie bieżącego użycia zasobów, a następnie zaplanowanie przyszłego wzrostu.
Aby oszacować przyszłe potrzeby związane z pojemnością, należy wziąć pod uwagę następujące czynniki:
- Oczekiwany wzrost biznesowy
- Okresowe wahania (sezonowe itd.)
- Ograniczenia aplikacji
- Identyfikacja wąskich gardeł i współczynników ograniczających
Należy również ustawić cele poziomu usług, aby można było utworzyć plan zarządzania pojemnością, który niezawodnie spełnia lub przekracza te cele w miarę zmiany obciążenia i środowiska.
Planowanie wydajności jest procesem iteracyjnym. W ramach tego modułu dowiesz się, jak mapować wymagania dotyczące zasobów dla składników aplikacji.
Pojęcia i terminologia
Zanim będzie można w pełni zrozumieć pojęcia i strategie napotkane w tym module, musisz mieć pewną wiedzę na temat wymagań wstępnych kilku podstawowych pojęć i podstawowych terminów związanych ze skalowaniem.
- Skalowanie w górę: zwiększanie składnika w celu obsługi zwiększonego obciążenia. Określane również jako skalowanie w pionie.
- Skalowanie w górę: dodawanie większej liczby składników lub zasobów w celu rozłożenia obciążenia na architekturę rozproszoną. Na przykład użycie prostej architektury, która ma wiele zapleczy za zestawem frontonów. Wraz ze wzrostem obciążenia dodamy więcej serwerów zaplecza (i frontonu), aby je obsłużyć. Określane również jako skalowanie w poziomie.
- Ręczne skalowanie: akcja człowieka jest niezbędna do zwiększenia ilości zasobów.
- Skalowanie automatyczne: system automatycznie dostosowuje ilość zasobów na podstawie obciążenia. Aby było jasne, kwota jest dostosowywana zarówno w górę, jak i w dół na podstawie zwiększonego lub zmniejszonego obciążenia.
- Skalowanie diY: Skalowanie typu "zrób to samodzielnie", w którym trzeba skonfigurować skalowanie automatyczne.
- Nieodłączna skala: usługi, które zostały utworzone w celu zapewnienia skalowalności i obsługi tego skalowania w tle, bez żadnej interwencji ze swojej strony. Z perspektywy użytkownika wyglądają jako niemal nieskończenie skalowalne, ponieważ możesz po prostu korzystać z większej ilości zasobów bez konieczności ich ręcznego dostarczania.
Architektura firmy Tailwind Traders
W tym module użyjemy przykładowej architektury fikcyjnej firmy sprzętowej o nazwie Tailwind Traders. Platforma handlu elektronicznego tej firmy wygląda następująco:
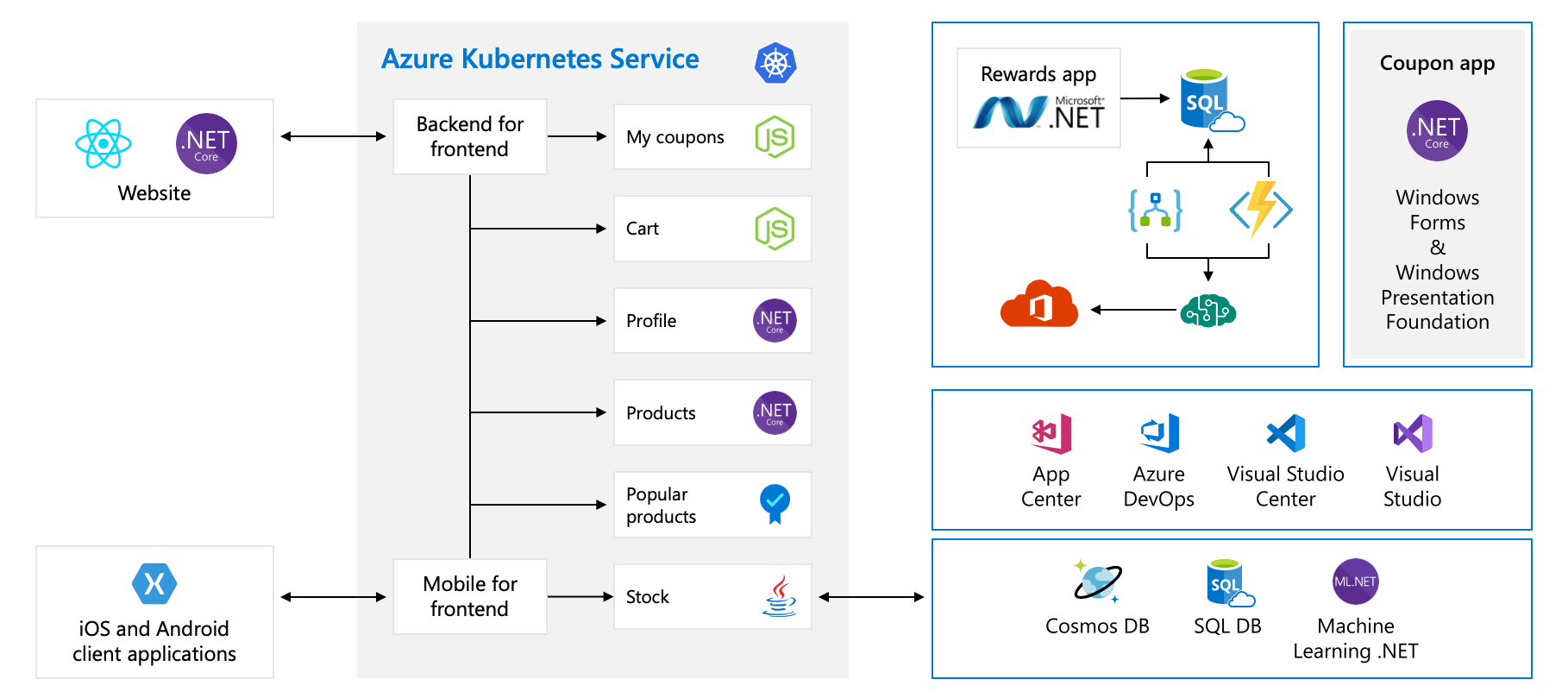
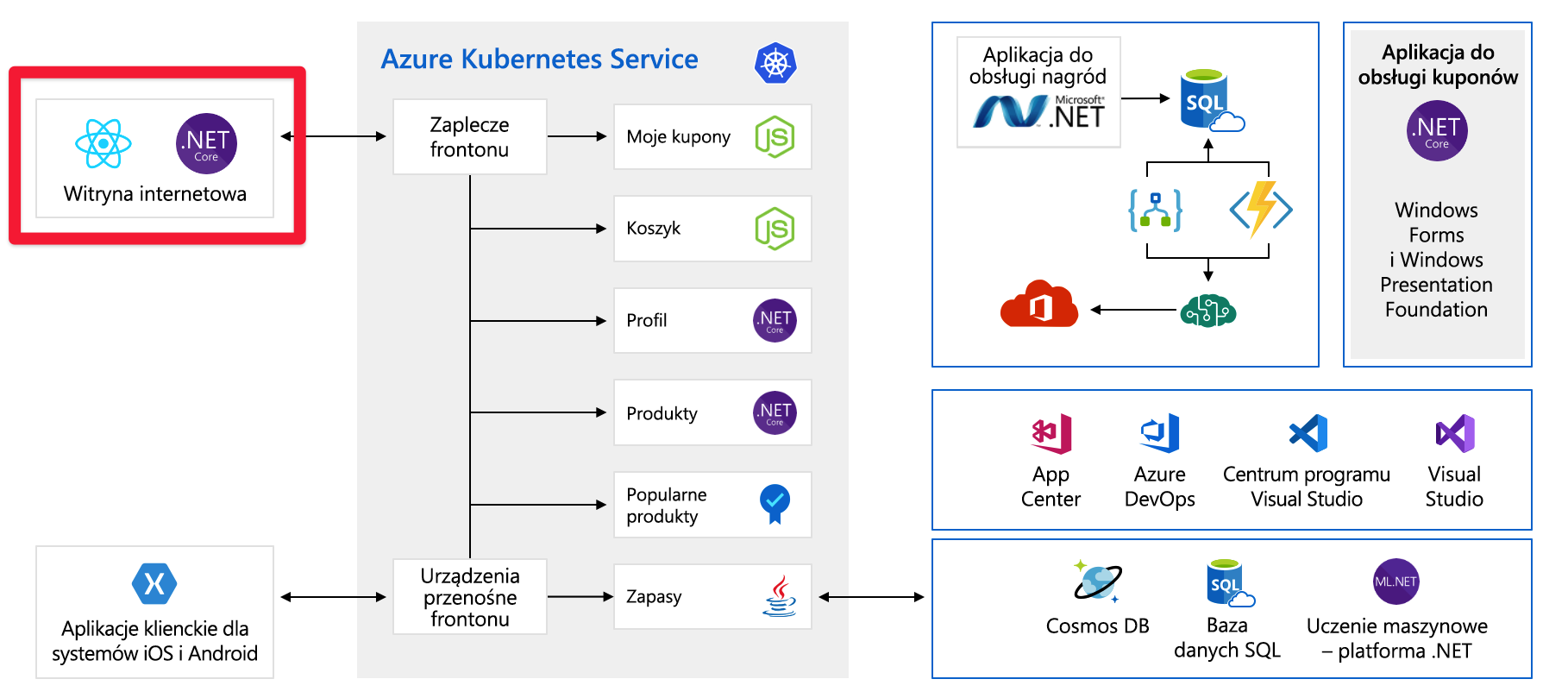
Ten diagram jest dość złożony na pierwszy rzut oka, więc przyjrzyjmy się temu. Witryna internetowa ma fronton. to, z czym rozmawiasz, jeśli idziesz do tailwindtraders.com.
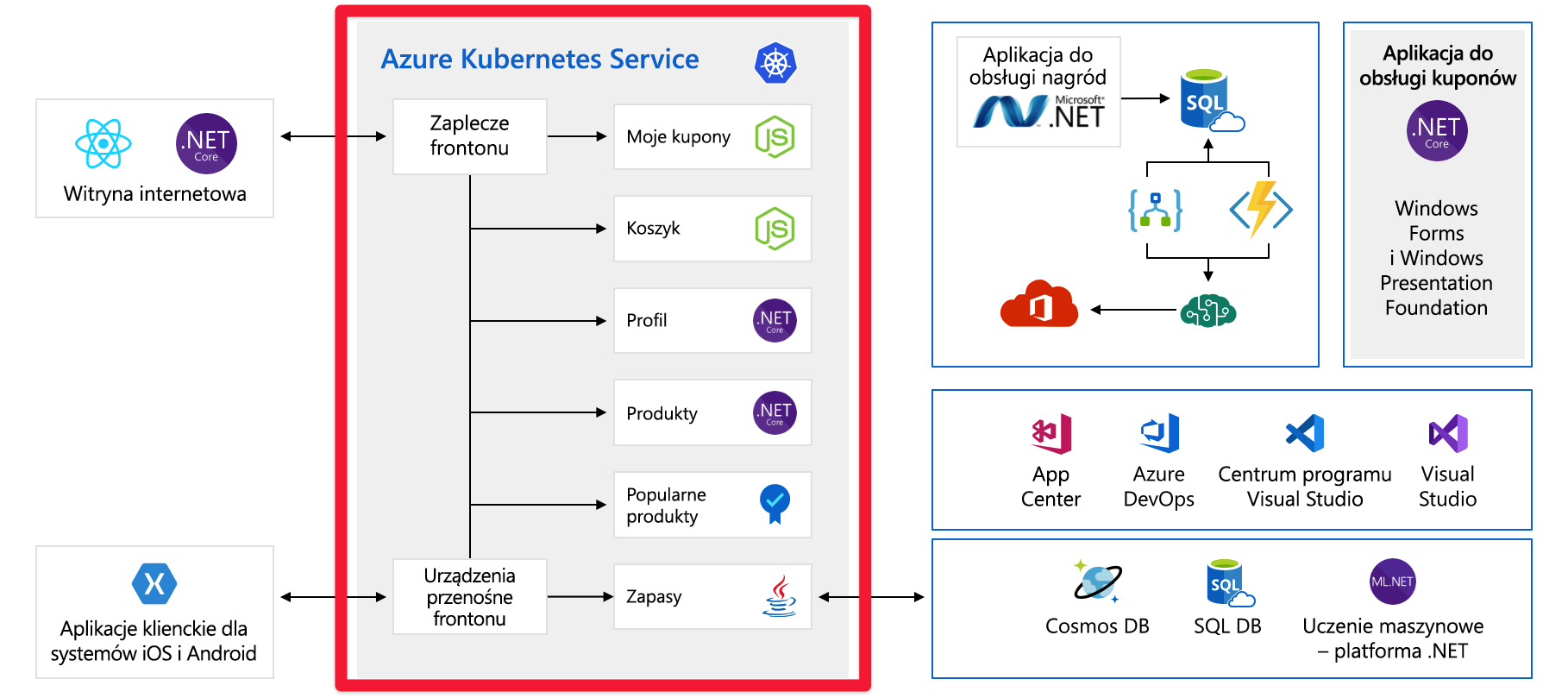
Fronton rozmawia z zestawem usług zaplecza. Te usługi zaplecza obejmują typowe elementy, takie jak usługa kuponowa, usługa koszyka zakupów, usługa zapasów itd. Wszystkie są uruchomione w usłudze Azure Kubernetes Service. W przypadku tej aplikacji istnieją inne części i technologie. Wszystko, na co należy się skupić, to fronton i usługi zaplecza uruchomione na platformie Kubernetes.
Pojedyncze punkty awarii
Teraz, gdy widzisz całą architekturę, poświęćmy chwilę na przeanalizowanie pojedynczych punktów awarii i miejsc, na które warto zwrócić uwagę, jeśli myślisz o skalowaniu.
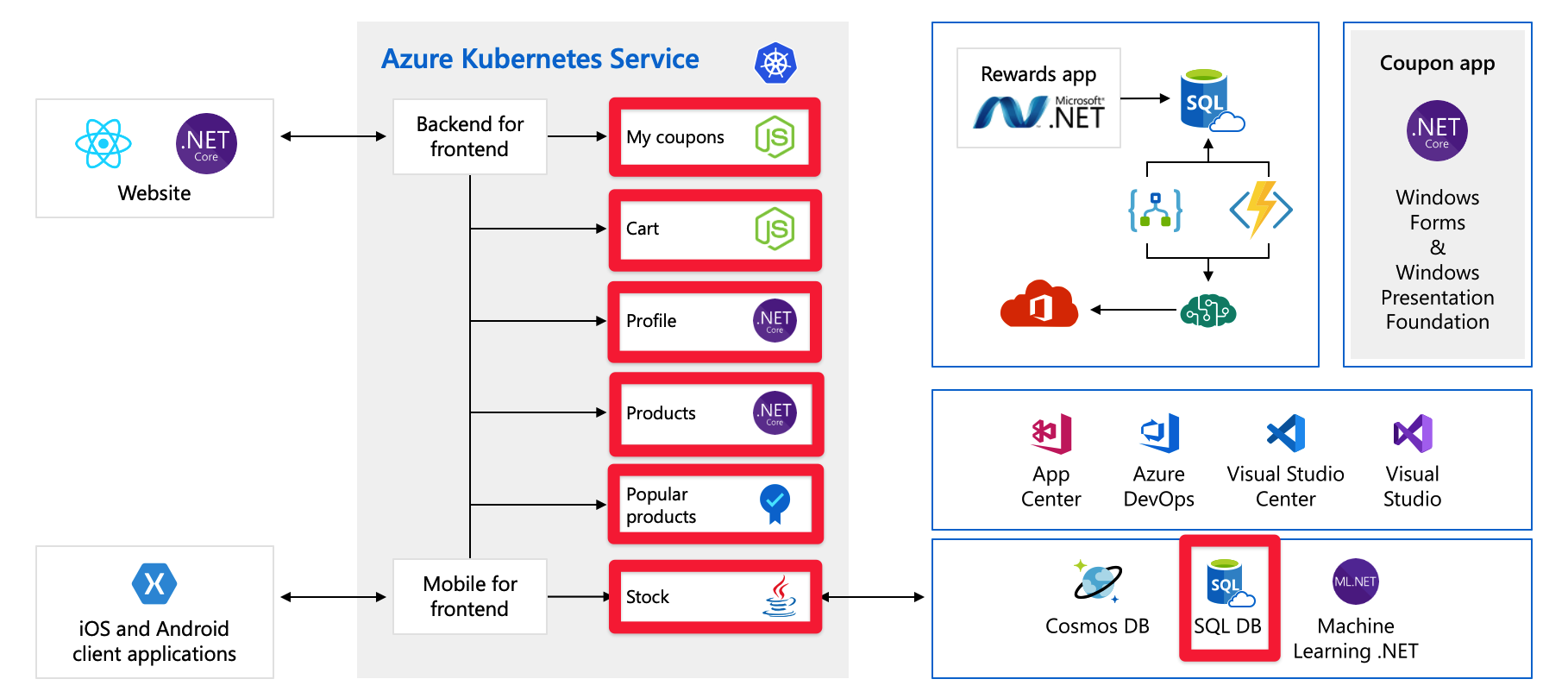
Wszystkie te usługi są pojedynczym punktem awarii — nie są tworzone pod kątem odporności ani skalowania. Jeśli jeden z nich zostanie przeciążony, prawdopodobnie ulegnie awarii i nie ma łatwego sposobu rozwiązania tego w tej chwili.
W dalszej części tego modułu przyjrzymy się innym sposobom projektowania tych usług, aby były bardziej skalowalne i niezawodne.
Wstępnie aprowizowana pojemność
Przyjrzyjmy się innemu problemowi, który może okazać się kłopotliwy. Poniżej przedstawiono usługi/składniki, które wymagają wstępnej aprowizacji pojemności:
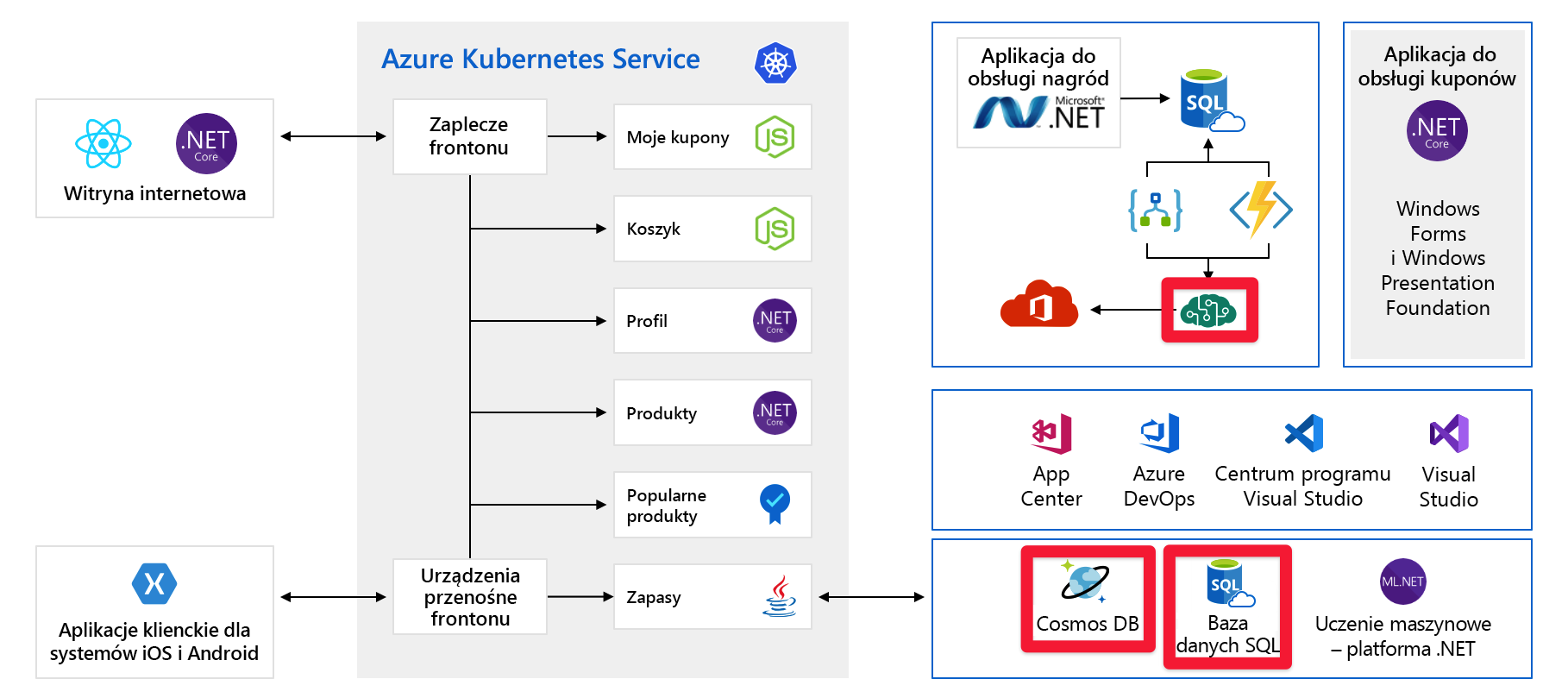
Na przykład w usłudze Cosmos DB wstępnie aprowizujemy przepływność. W przypadku przekroczenia tych limitów będziemy mogli zacząć zwracać komunikaty o błędach do naszych klientów. W przypadku usług azure AI wybieramy warstwę, a ta warstwa ma maksymalną liczbę żądań na sekundę. Po osiągnięciu jednego z limitów klienci będą ograniczani.
Czy znaczący wzrost ruchu, na przykład uruchomienie nowego produktu, sprawi, że osiągniemy te limity? W tej chwili nie wiemy. W dalszej części tego modułu omówimy kolejną kwestię.
Koszty
Nawet wtedy, gdy wszystko działa prawidłowo, nadal trzeba planować rozwój. Poniżej przedstawiono usługi z płatnością za użycie:
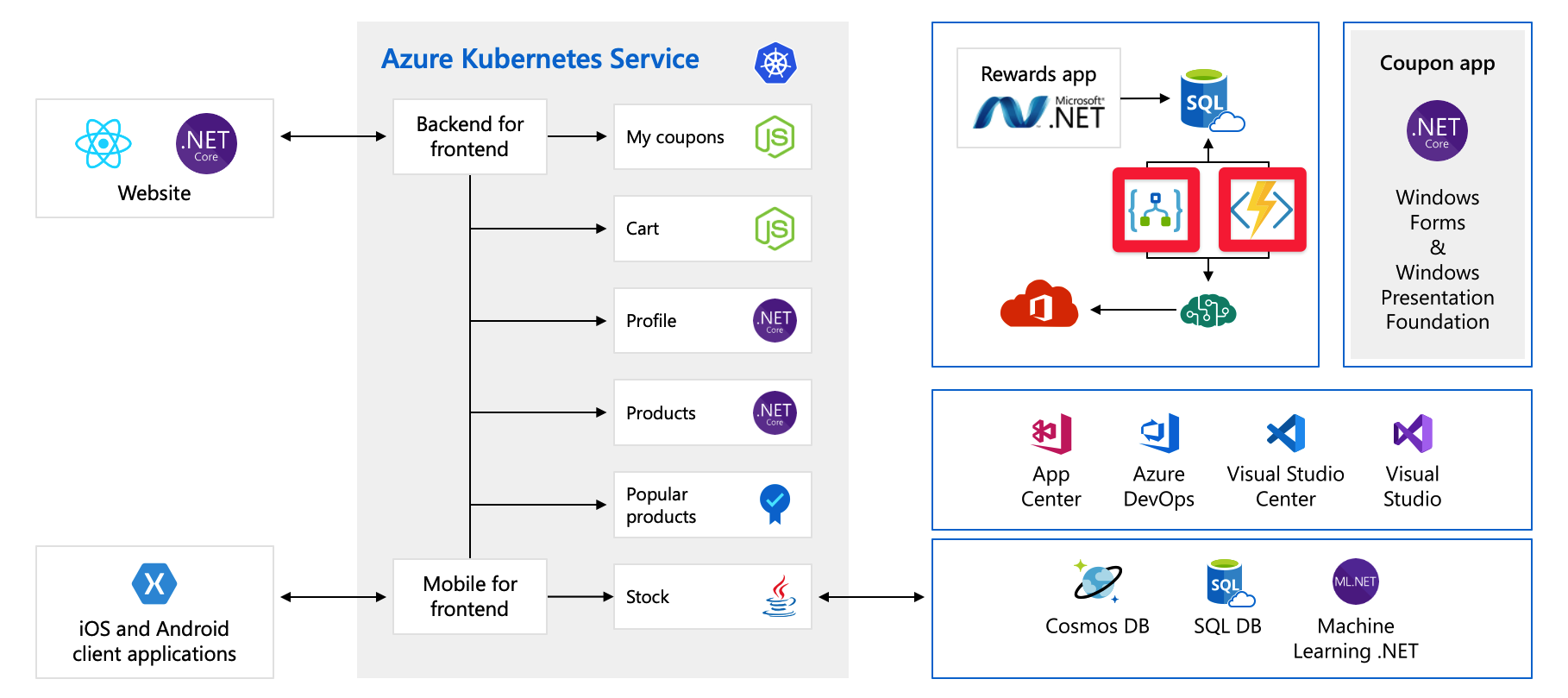
W tym miejscu używamy usług Azure Logic Apps i Azure Functions, które są przykładami technologii bezserwerowej. Te usługi są skalowane automatycznie i płacimy za żądanie. Koszty rosną w miarę rozwoju bazy klientów. Należy co najmniej mieć świadomość tego, jaki wpływ na wydatki na chmurę mogą wywrzeć nadchodzące wydarzenia, np. wprowadzenie nowego produktu. Pracujemy nad zrozumieniem i przewidywaniem wydatków na chmurę w dalszej części tego modułu.