Śledzenie zdarzeń
Zdarzenia mają cykl życia. Aby skutecznie reagować, musisz mieć możliwość śledzenia ewolucji samego zdarzenia oraz ewolucji odpowiedzi na nie od samego początku tego cyklu życia.
Ocenianie, co wiesz
Dobrym sposobem oceny procedury śledzenia zdarzeń przy użyciu określonego zdarzenia jest zadawanie sobie szeregu pytań:
- Kiedy po raz pierwszy wiesz o problemie? Jeśli twoim celem jest skrócenie czasu potrzebnego do odzyskania sprawności po zdarzeniach, musisz rozpocząć przechwytywanie informacji od momentu, w którym zapoznasz się z problemami.
- Jak dowiesz się o problemie? Czy system monitorowania powiadomił Cię o zdarzeniu? Czy po raz pierwszy słyszałeś o tym od klientów narzekających, bezpośrednio lub w mediach społecznościowych?
- Jeśli dopiero dowiadujesz się o problemie, czy jesteś pierwszym, który się o nim dowiaduje? Jeśli tak, kto musi powiadomić? Jeśli nie, kto inny jest świadomy problemu?
- Jeśli inni są świadomi, co (jeśli w ogóle) się z tym robi? Czy wszyscy zakładają, że ktoś inny go bada, czy ktoś zaczął podejmować działania w celu rozwiązania tego problemu?
- Jak jest to złe? Możemy nie mieć żadnego pojęcia dotkliwości lub skutków i nie mamy możliwości, aby dowiedzieć się, jak poważny jest problem i kogo dotyczy.
Mogą to być trudne pytania, aby odpowiedzieć, jeśli nic nie jest śledzone.
Standaryzacja miejsca śledzenia informacji o zdarzeniu
Istnieje wiele możliwych miejsc, które można przechowywać i udostępniać listę zdarzeń (aktywnych lub innych) oraz wszystkie bieżące informacje o tych zdarzeniach. Mogą to być tak proste, jak udostępniony obszar plików z dokumentami programu Word i tak złożone, jak wysoce wyspecjalizowane oprogramowanie i usługi śledzenia zdarzeń. Między tymi dwoma skrajnymi rozwiązaniami są systemy do obsługi biletów i śledzenia pracy, które można wykorzystać do tego zadania. Wybrany system jest w rzeczywistości mniej ważny niż sposób jego używania. Niezależnie od używanego systemu każdy, kto może mieć jakiekolwiek połączenie ze zdarzeniami (inżynierowie, obsługa klienta, zarządzanie, public relations, legalne itd.) muszą wiedzieć, gdzie znaleźć system, jak zgłosić zdarzenie i jak uzyskać dostęp do danych, gdy jest to konieczne. Jednym z pewnych sposobów, aby nie powiodło się śledzenie zdarzeń, jest sytuacja, gdy osoby, które mają być obsługiwane przez system, nie wiedzą, jak do niego dotrzeć ("jaki był znowu adres URL naszego systemu?"), kiedy tego potrzebują.
W tym module użyjemy funkcji elementu roboczego usługi Azure DevOps na potrzeby naszego przykładowego systemu śledzenia.
Tworzenie mostka konwersacji
Aby odpowiedzieć na niektóre pytania w poprzedniej sekcji Ocenić, co wiesz i rozpocząć proces reagowania na zdarzenia, musisz mieć sposób komunikowania się z innymi osobami o zdarzeniu. Idealnie, byłoby to pewnego rodzaju elektroniczne medium do współpracy zespołowej, choć telekonferencje również działają. Połączenia konferencyjne/mostki telefoniczne są mniej preferowane opcje, ponieważ trudniej jest z perspektywy czasu przejrzeć komunikację incydentu (stąd wspomniana wcześniej rola "Skrzypek").
Niezależnie od wybranego medium, należy pamiętać, aby utworzyć unikatowy kanał komunikacyjny, który jest ograniczony wyłącznie do dyskusji na temat tego incydentu i nic innego. Ważne jest, aby unikać nieistotnych dyskusji na tym kanale, ponieważ musisz mieć możliwość zebrania danych i ich analizy podczas późniejszego przeglądu po zdarzeniu.
W tym module użyjemy usługi Microsoft Teams jako metody komunikacji z incydentami.
Automatyzacja uruchomienia śledzenia incydentów
Więc przyjrzyjmy się fragmentom, które zebraliśmy do tej pory. Mamy:
- Lista osób na wezwanie (i rotacja zdefiniowana dla nich).
- Rola, jaką możemy przypisać do osób pracujących nad incydentem.
- Konkretne miejsce, gdzie zadeklarujemy incydent i będziemy go śledzić.
- Unikatowy kanał dla osób pracujących nad tym zdarzeniem w celu komunikowania się na jego temat.
Możesz i należy zautomatyzować tworzenie wszystkich tych elementów i zarządzanie nimi w możliwie najszerszym zakresie. Gdy pojawi się pilny problem, nie chcesz przypomnieć sobie wszystkich kroków niezbędnych do zgłoszenia zdarzenia, wprowadzenia odpowiednich osób i śledzenia go. Wszystko, co naprawdę chcesz zrobić, to być w stanie nacisnąć przycisk "start", aby praca mogła natychmiast rozpocząć się i rozwiązać problem.
Używanie usługi Logic Apps do automatyzacji bez kodu
Jednym ze sposobów automatyzacji początkowej odpowiedzi jest użycie usługi Logic Apps, która może uprościć zadanie planowania, automatyzowania i organizowania zadań, procesów biznesowych i przepływów pracy.
Logic Apps to usługa w chmurze platformy Azure służąca do tworzenia rozwiązań integracji. Używa łączników do automatyzacji przepływów pracy. Wyzwalacze uruchamiają Aplikację Logiki, gdy wystąpi określone zdarzenie lub gdy dane spełniają określone kryteria. Akcje to operacje, które następnie są wykonywane w przepływie pracy aplikacji logicznej.
W naszym przykładzie użyjemy następujących łączników usług Logic Apps do śledzenia incydentów.
- Azure Boards (część Azure DevOps), które można używać do tworzenia i śledzenia zgłoszeń/incydentów.
- usługi Azure Storage, gdzie można przechowywać i pobierać informacje o tym, kto jest na dyżurze, aby przypisać odpowiednie osoby do reagowania na zdarzenie. W naszym przykładzie będziemy używać usługi Azure Table Storage, ponieważ oferuje ona bardzo prosty skład klucz-wartość, który ułatwia przechowywanie listy inżynierów i ich statusu dyżuru.
- usługi Microsoft Teams, za pomocą którego można utworzyć nowy, unikatowy kanał zdarzeń w celu śledzenia rozmów zespołów inżynieryjnych w czasie rzeczywistym podczas komunikowania się o określonych zdarzeniach. Dzięki temu można zachować interakcje w odniesieniu do osi czasu zdarzeń podczas późniejszego przeglądu po zdarzeniu.
Teraz połączmy to wszystko razem z aplikacją logiki. Najpierw przyjrzyj się pełnej aplikacji, jak pokazano w Projektancie aplikacji usługi Logic Apps, a następnie omówimy ją krok po kroku.
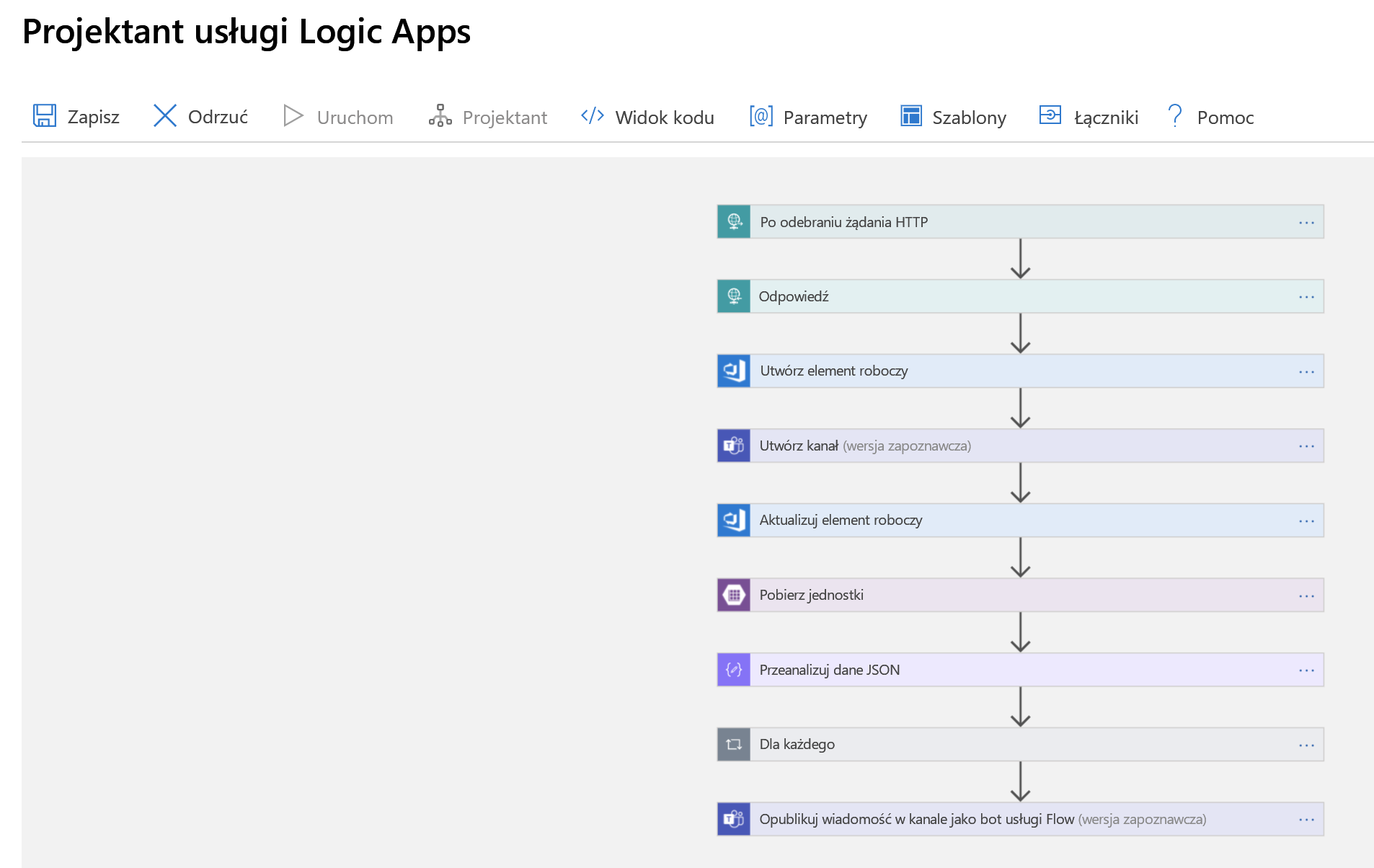
Pierwszym krokiem jest obsługa wyzwalacza, czyli tego wspomnianego żądania HTTP. Żądanie HTTP POST jest wykonywane w naszej aplikacji logiki zawierającej ładunek JSON zawierający informacje o zdarzeniu, które chcemy zadeklarować. Analizujemy ten ładunek i wysyłamy potwierdzenie, które otrzymaliśmy:
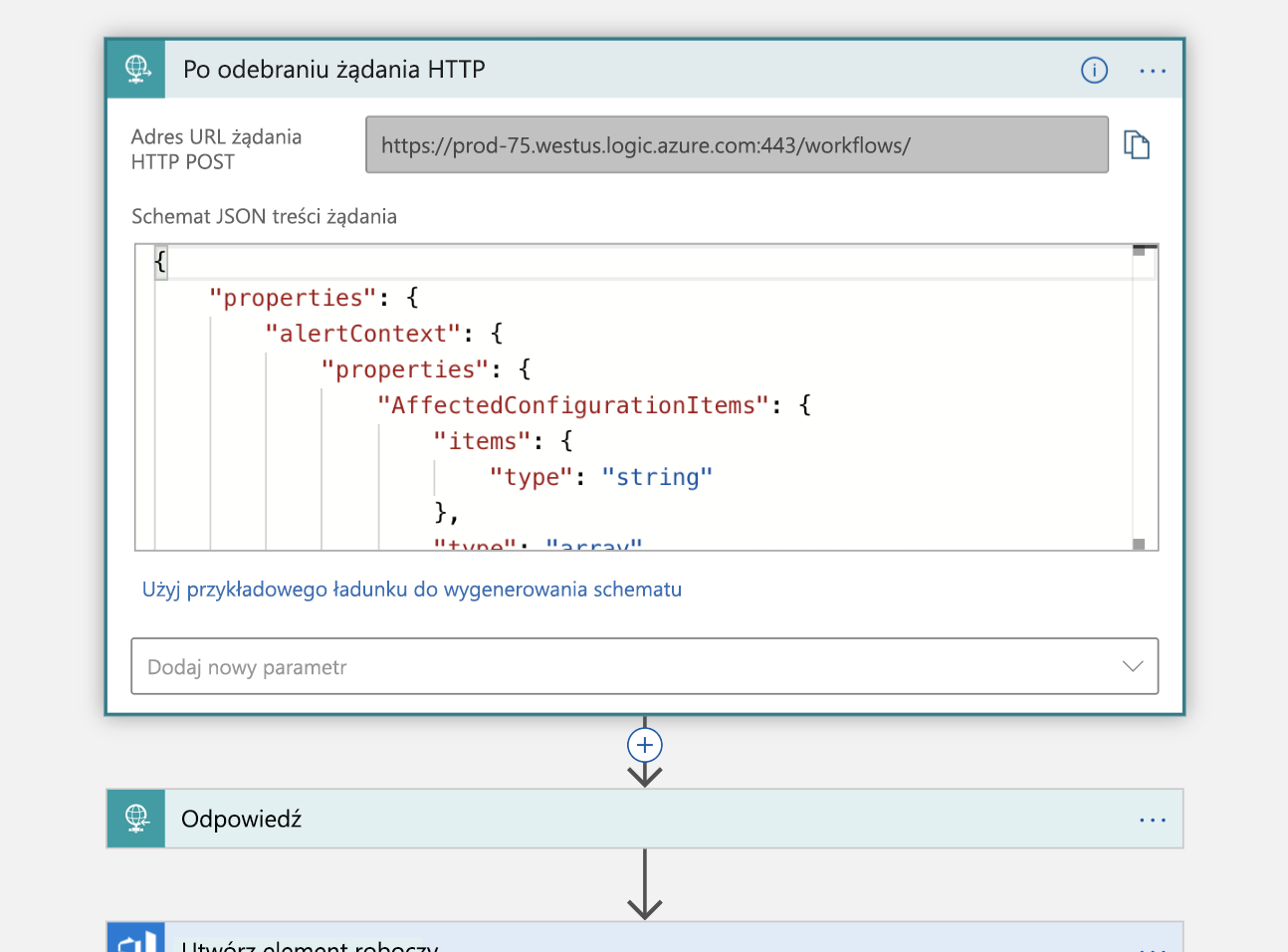
Korzystając z tych informacji, utworzymy nowy element roboczy w naszej organizacji usługi Azure DevOps reprezentującej to zdarzenie.
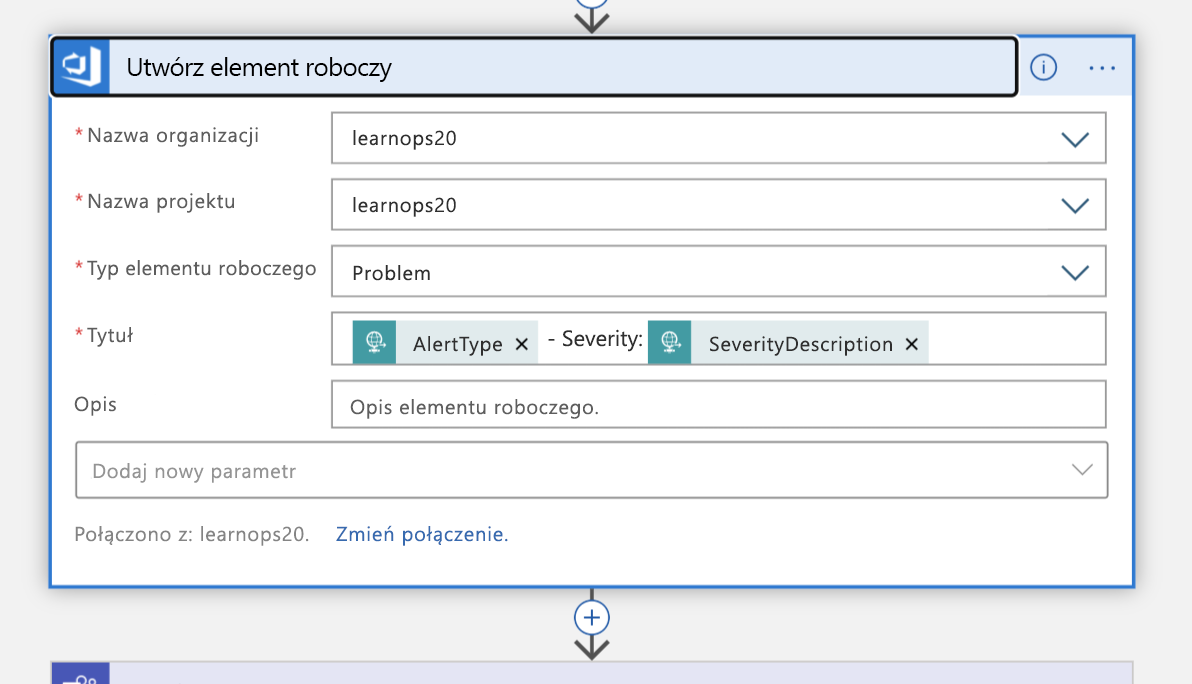
Następnie utworzy nowy kanał usługi Teams dla zdarzenia:
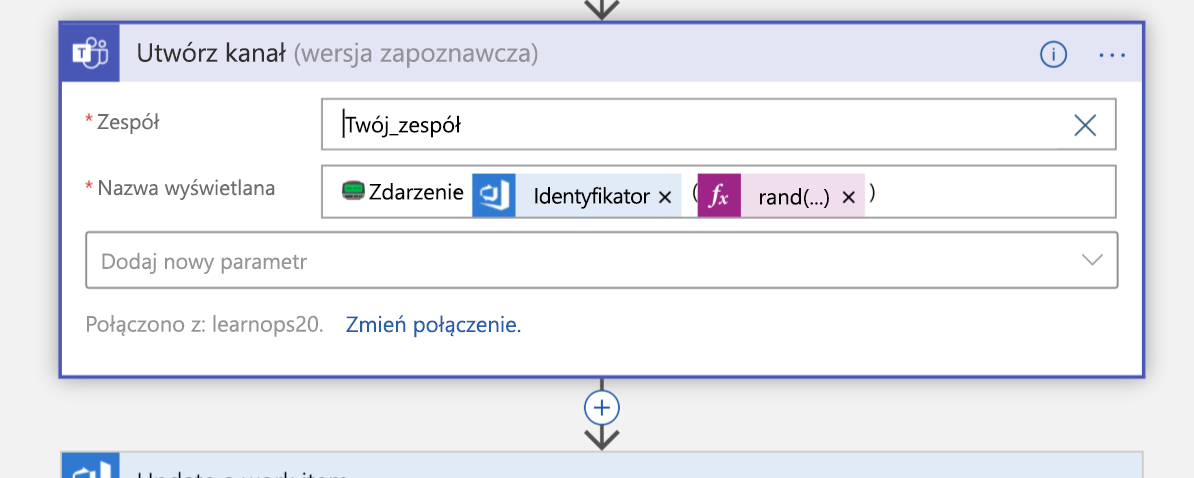
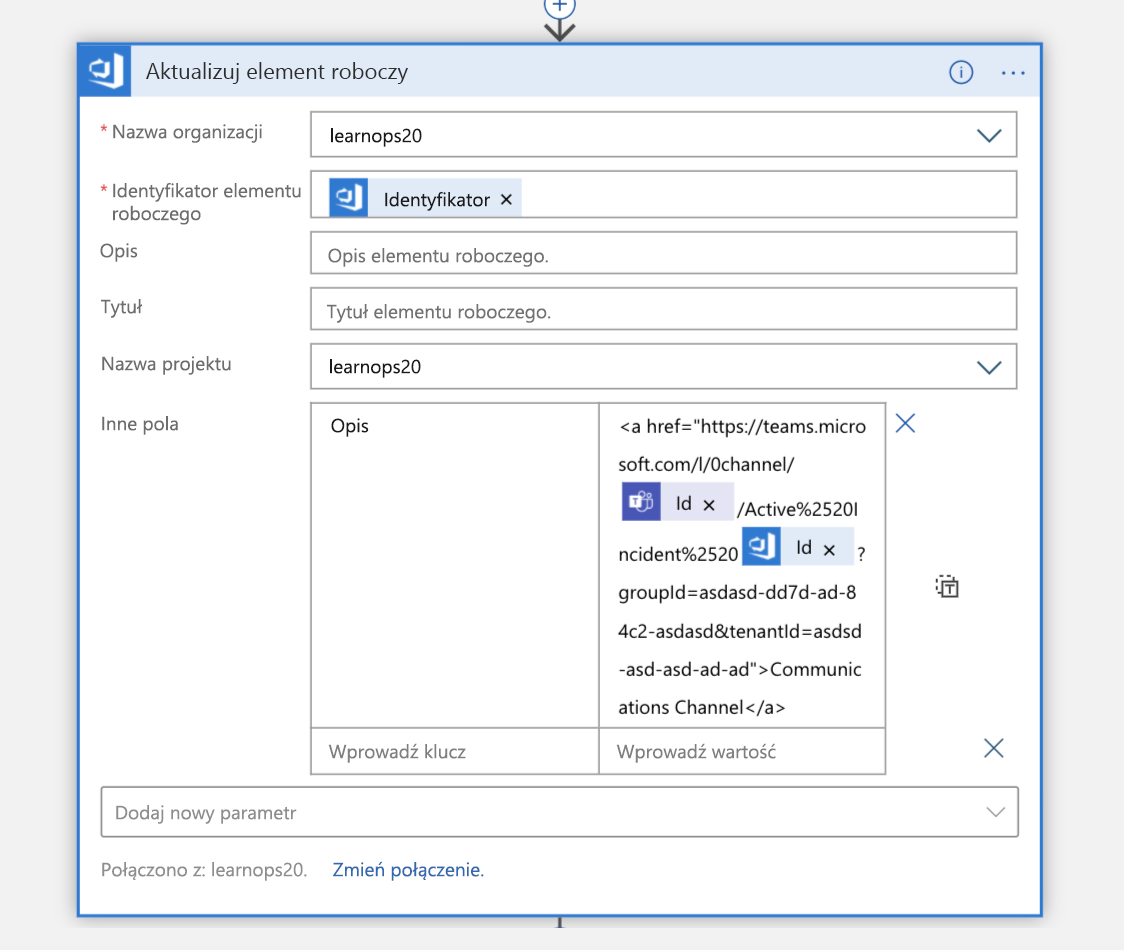
Po utworzeniu kanału element roboczy, który utworzyliśmy chwilę temu, zostanie zaktualizowany za pomocą linku do nowego kanału. Dzięki temu wszystkie informacje będą znajdować się w tym samym miejscu (element roboczy) i umożliwiają osobom przeglądających je później, aby wiedzieć, gdzie przejść, jeśli chcą dołączyć do tego kanału.
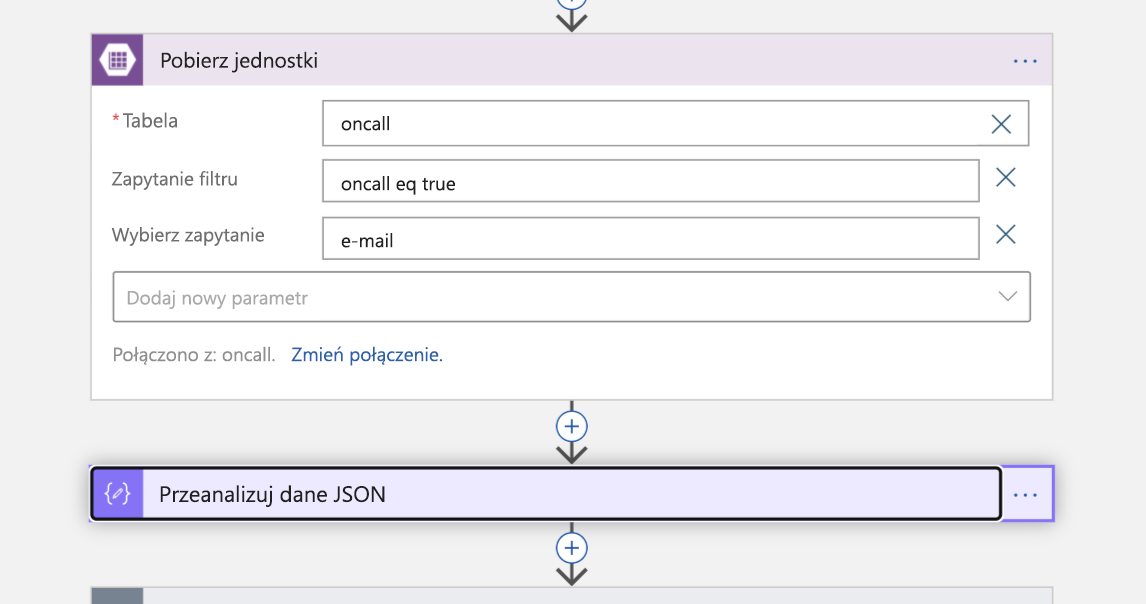
Teraz nadszedł czas, aby uwzględnić osobę na wezwanie. Prowadzimy wyszukiwanie w tabelach Azure Table Storage w celu uzyskania adresu e-mail inżyniera wymienionego jako osoba dyżurująca. Zwraca to odpowiedź JSON, którą następnie parsujemy.
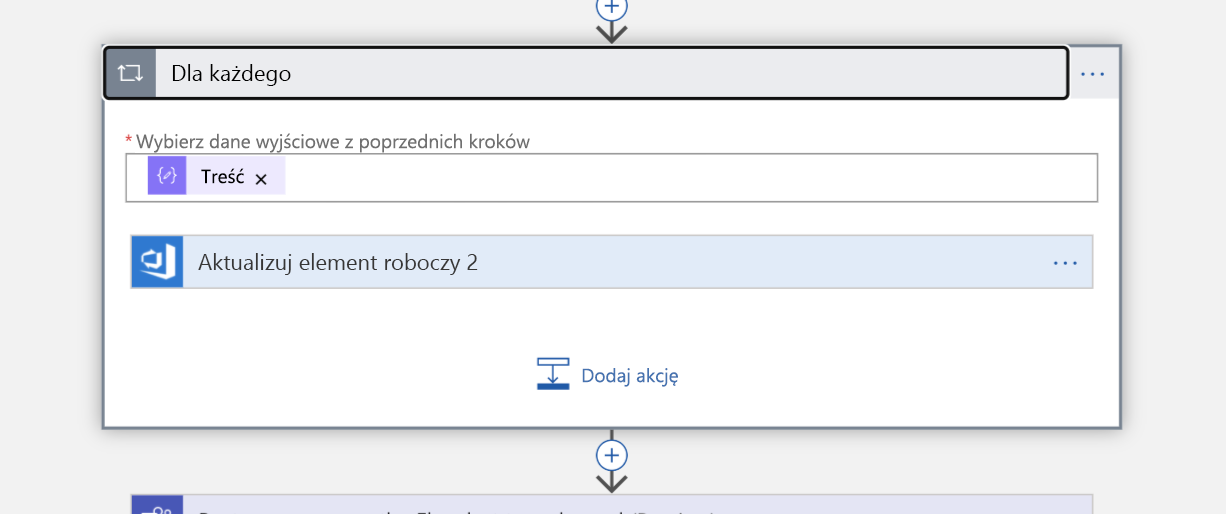
Ponieważ nasze zapytanie zwróci listę, musimy iterować poszczególne elementy na tej liście jako kolejny krok. Przypisujemy zadanie każdej osobie (są teraz "właścicielami" incydentu).
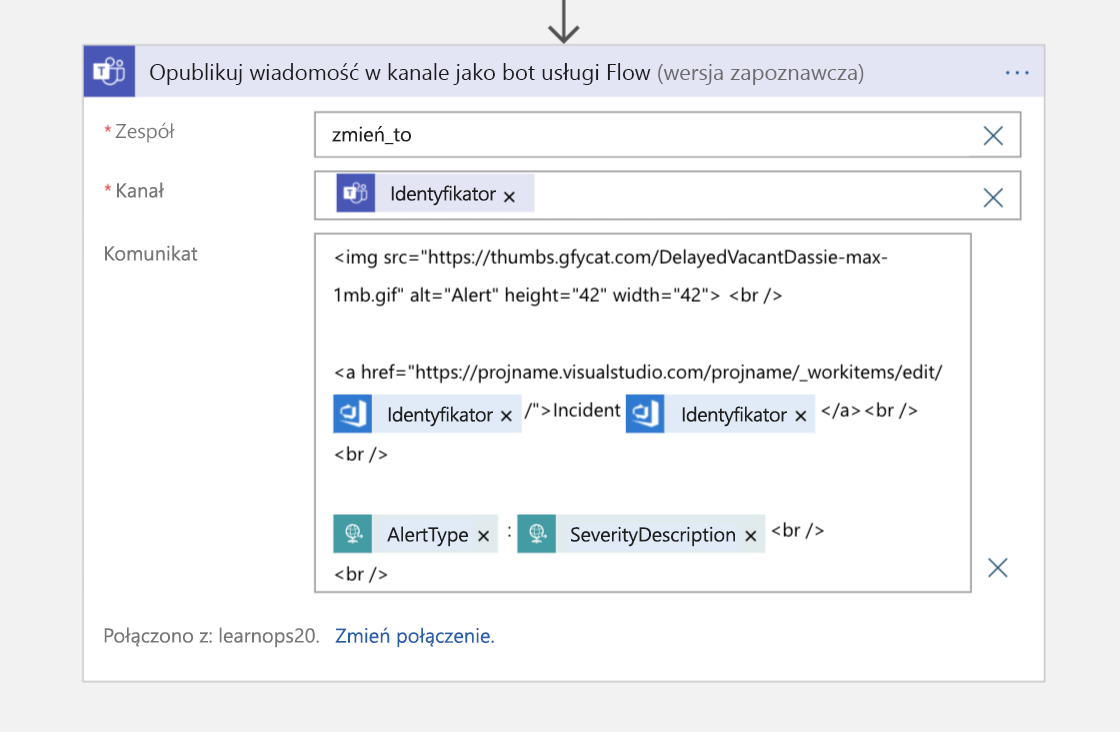
Ostatecznie wysyłamy wiadomość do kanału Teams z odnośnikiem do elementu roboczego dla osób dołączających do kanału, które chcą wiedzieć, gdzie są przechowywane oficjalne informacje o tym zdarzeniu.
Jest to tylko jeden przykład automatyzacji konfigurowania mechanizmów śledzenia i komunikacji zdarzeń. W następnej lekcji przyjrzymy się nieco bliżej aspektom komunikacji wokół incydentu.