Modelowanie małych jednostek odnośników
Nasz model danych obejmuje dwie małe jednostki danych referencyjnych ProductCategory i ProductTag. Te jednostki są używane na potrzeby wartości referencyjnych i są powiązane z innymi jednostkami, choć 1:Many relationship.
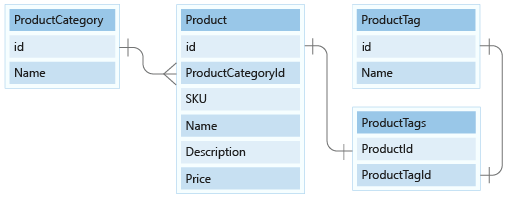
W tej lekcji modelujemy ProductCategory jednostki i ProductTag w naszym modelu dokumentów.
Kategorie produktów modelu
Najpierw w przypadku kategorii modelujemy dane z kolumnami identyfikatora i nazwy jako jedyne właściwości i umieścimy je w nowym kontenerze o nazwie ProductCategory.
Następnie musimy wybrać klucz partycji. Przyjrzyjmy się operacjom, które musimy wykonać na tych danych.
Utworzymy nową kategorię produktów, zmodyfikujemy kategorię produktu, a następnie wyświetlimy listę wszystkich kategorii produktów. Tworzenie i edytowanie kategorii produktów nie jest często wykonywanymi operacjami. Nasza aplikacja do handlu elektronicznego często wyświetla listę wszystkich kategorii produktów, gdy klienci odwiedzają witrynę internetową. Dlatego ostatnia operacja jest operacją, która będzie uruchamiana najwięcej.
Zapytanie dotyczące tej ostatniej operacji będzie wyglądać następująco: SELECT * FROM c.
Przy użyciu identyfikatora jako wybranego klucza partycji to zapytanie będzie teraz podzielone na partycje, mimo że chcemy podjąć próbę zoptymalizowania tych operacji z dużą liczbą operacji odczytu, użyj tylko jednej partycji, jeśli jest to możliwe. Wiemy również, że dane kategorii produktów nigdy nie będą rosnąć w pobliżu 20 GB rozmiaru, więc w jaki sposób te informacje pomogą nam w modelowaniu danych w sposób, który spowoduje utworzenie pojedynczej kwerendy partycji podczas wyświetlania listy wszystkich kategorii produktów.
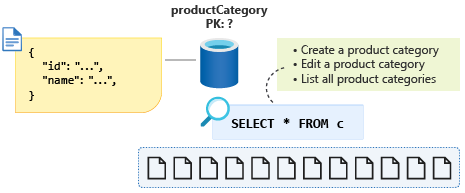
Aby wykorzystać tę niewielką ilość danych z powrotem do pojedynczej partycji, możemy dodać do naszego schematu właściwość dyskryminującą jednostkę i użyć jej jako klucza partycji dla tego kontenera. Przypisując tę właściwość stałą wartość dla wszystkich dokumentów tego typu w kontenerze, zapewniamy, że mamy teraz jedno zapytanie partycji. W tym przypadku wywołamy właściwość type i nadamy stałą wartość category. Nasze zapytanie będzie teraz wyglądać następująco: SELECT * FROM c WHERE c.type = ”category”.

Modelowanie tagów produktów
Następna ProductTag wartość to jednostka. Ta jednostka jest prawie identyczna w funkcji do ProductCategory jednostki omówionej w poprzedniej sekcji. Przyjrzyjmy się temu samemu podejściu i zamodelujmy dokument, aby zawierał właściwości identyfikatora i nazwy oraz utworzyć właściwość dyskryminującą jednostki o nazwie type, w tym przypadku ze stałą wartością tag. Utwórzmy nowy kontener o nazwie ProductTag i utwórzmy type nowy klucz partycji.
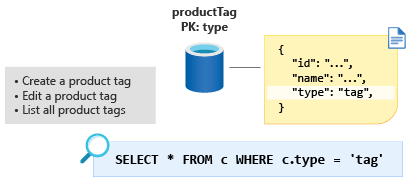
Niektórzy ludzie uważają, że ta technika modelowania małych tabel odnośników jest dziwna. Jednak modelowanie danych w ten sposób daje nam możliwość dalszej optymalizacji w następnym module.