Opcje konfiguracji usługi HDInsight
Usługa HDInsight oferuje szeroką gamę technologii systemu operacyjnego osadzonych w niej, które mogą służyć do obsługi scenariuszy przesyłania strumieniowego i danych wsadowych, które są terminami zdefiniowanymi w architekturach lambda. W tym modelu architektury istnieje gorąca ścieżka danych i zimna ścieżka danych. Gorąca ścieżka danych jest generowana w czasie rzeczywistym przez urządzenia, czujniki lub aplikacje, a analiza danych jest wykonywana niemal w czasie rzeczywistym. Jest to często nazywane danymi przesyłanymi strumieniowo. Zimna ścieżka danych polega na tym, że dane są przenoszone w partiach, zazwyczaj z innych magazynów danych i są często określane jako dane wsadowe.
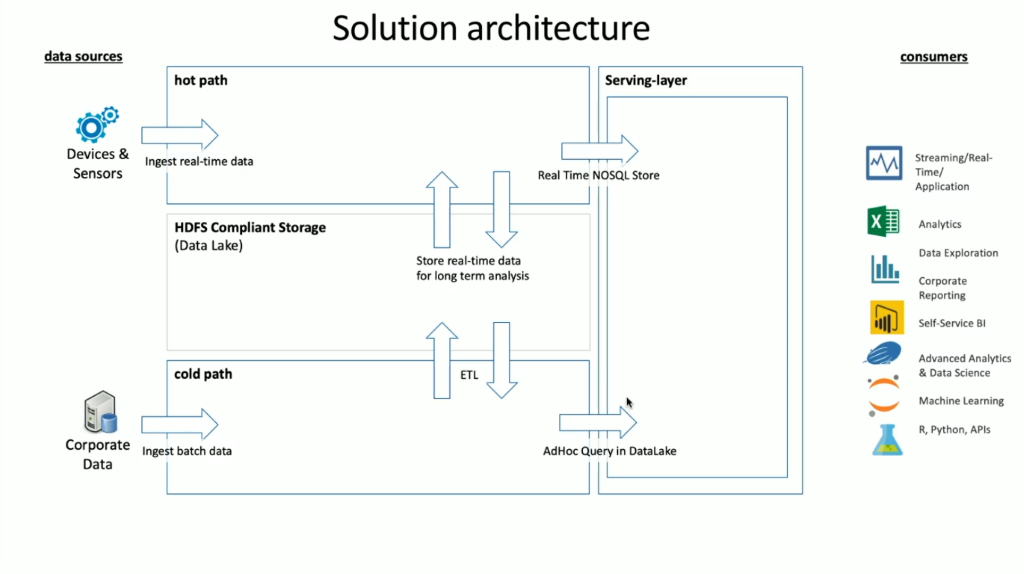
Podczas implementowania usługi HDInsight przechowywanie danych odbywa się w ramach zgodnego rozproszonego systemu plików Hadoop (HDFS). Na platformie Azure usługa Data Lake Gen2 jest zwykle używana jako magazyn danych zgodny ze standardem HDFS. Dane ze ścieżki gorącej i ścieżki zimnej po przetworzeniu są przechowywane w scentralizowanym magazynie danych o nazwie Data Lake. Magazyn Data Lake może być oddzielony do przechowywania danych w różnych przedziałach, które mogą być definiowane przez stan danych (strefa docelowa, strefa transformacji itp.), wymagania dostępu (gorące, ciepłe i zimne) oraz grupy biznesowe. Warstwa Obsługa jest ostatnim przedziałem w usłudze Data Lake, który przechowuje dane w formacie gotowym do użycia przez różne typy odbiorców.
Krytycznie aspekt obliczeniowy usługi HDInsight dotyczy przetwarzania danych przesyłanych strumieniowo lub wsadowych i może się różnić w zależności od typu klastra wybranego podczas aprowizacji klastra usługi HDInsight. Usługa HDInsight oferuje usługi w poszczególnych opcjach klastra, jak pokazano w poniższej tabeli.
| Typ klastra | Opis |
|---|---|
| Apache Hadoop | Struktura korzystająca z systemu plików HDFS i prostego modelu programowania MapReduce do przetwarzania i analizowania danych wsadowych. |
| Apache Spark | platforma przetwarzania równoległego typu „open source”, która obsługuje przetwarzanie w pamięci umożliwiające zwiększenie wydajności aplikacji do analizy danych big data. |
| HBase | baza danych NoSQL oparta na platformie Hadoop, która zapewnia dostęp losowy i wysoki poziom spójności w przypadku dużych ilości nieustrukturyzowanych i częściowo ustrukturyzowanych danych — potencjalnie miliardów wierszy pomnożonych przez miliony kolumn. |
| Zapytanie interakcyjne Apache | pamięć podręczna w pamięci do interaktywnego i szybszego wykonywania zapytań programu Hive. |
| Apache Kafka | platforma typu „open source”, która służy do tworzenia potoków danych przesyłanych strumieniowo i aplikacji do obsługi tych danych. Platforma Kafka obejmuje również funkcję kolejki komunikatów, która umożliwia publikowanie i subskrybowanie strumieni danych. |
Dlatego ważne jest, aby wybrać prawidłowy typ klastra, aby spełnić przypadek biznesowy, który próbujesz rozwiązać. Niezależnie od wybranego typu klastra dodatkowe składniki typu open source są również dodawane wewnątrz klastra w celu zapewnienia dodatkowych możliwości, takich jak:
Zarządzanie usługą Hadoop
HCatalog — warstwa zarządzania tabelami i magazynami dla usługi Hadoop
Apache Ambari — ułatwia zarządzanie klastrem Apache Hadoop i monitorowanie go
Apache Oozie — system harmonogramu przepływu pracy do zarządzania zadaniami platformy Apache Hadoop
Apache Hadoop YARN — zarządza zarządzaniem zasobami i planowaniem zadań/monitorowaniem
Apache ZooKeeper — scentralizowana usługa do obsługi informacji o konfiguracji, nazewnictwa, zapewniania synchronizacji rozproszonej i świadczenia usług grupowych.
Przetwarzanie danych
Apache Hadoop MapReduce — struktura umożliwiająca łatwe pisanie aplikacji, które przetwarzają ogromne ilości danych
Apache Tez — struktura aplikacji do przetwarzania danych
Apache Hive — ułatwia zarządzanie dużymi zestawami danych przechowywanymi w magazynie rozproszonym przy użyciu języka SQL
Analiza danych
Apache Pig — udostępnia warstwę abstrakcji w usłudze MapReduce do analizowania dużych zestawów danych
Apache Phoenix — umożliwia olTP i analizę operacyjną w usłudze Hadoop
Apache Mahout — struktura Algebra do tworzenia własnych algorytmów
Uwaga
W momencie pisania tekstu usługi Azure Data Lake Gen1 i Azure Blob Storage są obsługiwane warstwy magazynu danych dla usługi HDInsight. Należy przyjrzeć się migracji tych danych do usługi Azure Data Lake Gen2, ponieważ jest to zalecana platforma magazynu dla platform Spark i Hadoop, a także wybór domyślny dla bazy danych HBase.