Testowanie modeli na placu zabaw usługi Azure AI Studio
Place zabaw to przydatne interfejsy w usłudze Azure AI Studio, których można używać do eksperymentowania z wdrożonym modelem bez konieczności tworzenia własnej aplikacji klienckiej. Usługa Azure AI Studio oferuje wiele placów zabaw z różnymi opcjami dostrajania parametrów.
Ukończenie placu zabaw
Plac zabaw Uzupełnianie umożliwia wykonywanie wywołań do wdrożonych modeli za pośrednictwem interfejsu tekstowego, tekstu i dostosowywania parametrów. Musisz wybrać nazwę wdrożenia modelu w obszarze Wdrożenia. Opcjonalnie możesz użyć podanych przykładów, aby rozpocząć pracę, a następnie wprowadzić własne monity.
Parametry placu zabaw uzupełniania
Istnieje wiele parametrów, które można dostosować, aby zmienić wydajność modelu:
- Temperatura: Kontroluje losowość. Obniżenie temperatury oznacza, że model generuje bardziej powtarzające się i deterministyczne odpowiedzi. Zwiększenie temperatury powoduje zwiększenie liczby nieoczekiwanych lub kreatywnych odpowiedzi. Spróbuj dostosować temperaturę lub górną wartość P, ale nie obie.
- Maksymalna długość (tokeny): ustaw limit liczby tokenów na odpowiedź modelu. Interfejs API obsługuje maksymalnie 4000 tokenów udostępnianych między monitem (w tym komunikatem systemowym, przykładami, historią komunikatów i zapytaniem użytkownika) oraz odpowiedzią modelu. Jeden token ma mniej więcej cztery znaki dla typowego tekstu w języku angielskim.
- Sekwencje zatrzymania: ustaw, aby odpowiedzi zatrzymywały się w żądanym punkcie, na przykład na końcu zdania lub listy. Określ maksymalnie cztery sekwencje, w których model przestanie generować kolejne tokeny w odpowiedzi. Zwrócony tekst nie będzie zawierać sekwencji zatrzymania.
- Najwyższe prawdopodobieństwa (Top P): Podobnie jak temperatura, ta steruje losowością, ale używa innej metody. Obniżenie górnej litery P zawęża wybór tokenu modelu do porównań tokenów. Zwiększenie górnej liczby punktów umożliwia modelowi wybór spośród tokenów z wysokim i niskim prawdopodobieństwem. Spróbuj dostosować temperaturę lub górną wartość P, ale nie obie.
- Kara częstotliwości: zmniejsz prawdopodobieństwo proporcjonalnego powtórzenia tokenu w oparciu o częstotliwość występowania go w tekście do tej pory. Zmniejsza to prawdopodobieństwo powtórzenia dokładnie tego samego tekstu w odpowiedzi.
- Kara za obecność: Zmniejsz prawdopodobieństwo powtórzenia wszelkich tokenów, które pojawiły się w tekście do tej pory. Zwiększa to prawdopodobieństwo wprowadzenia nowych tematów w odpowiedzi.
- Tekst przed odpowiedzią: wstaw tekst po danych wejściowych użytkownika i przed odpowiedzią modelu. Może to pomóc w przygotowaniu modelu do odpowiedzi.
- Tekst po odpowiedzi: wstaw tekst po wygenerowanej odpowiedzi modelu, aby zachęcić do dalszego wprowadzania danych przez użytkownika, tak jak podczas modelowania konwersacji.
Czat — plac zabaw
Plac zabaw czatu jest oparty na interfejsie konwersacji i komunikatów. Możesz zainicjować sesję z komunikatem systemowym, aby skonfigurować kontekst czatu.
Na placu zabaw czatu możesz dodać kilka przykładów. Termin "few-shot" odnosi się do udostępniania kilku przykładów, aby pomóc modelowi dowiedzieć się, co musi zrobić. Można o tym myśleć w przeciwieństwie do zero-shot, który odnosi się do dostarczania żadnych przykładów.
W ustawieniach Asystenta można podać kilka przykładów danych wejściowych użytkownika i odpowiedzi asystenta. Asystent próbuje naśladować odpowiedzi uwzględnione w tym miejscu w tonu, regułach i formacie zdefiniowanym w komunikacie systemowym.
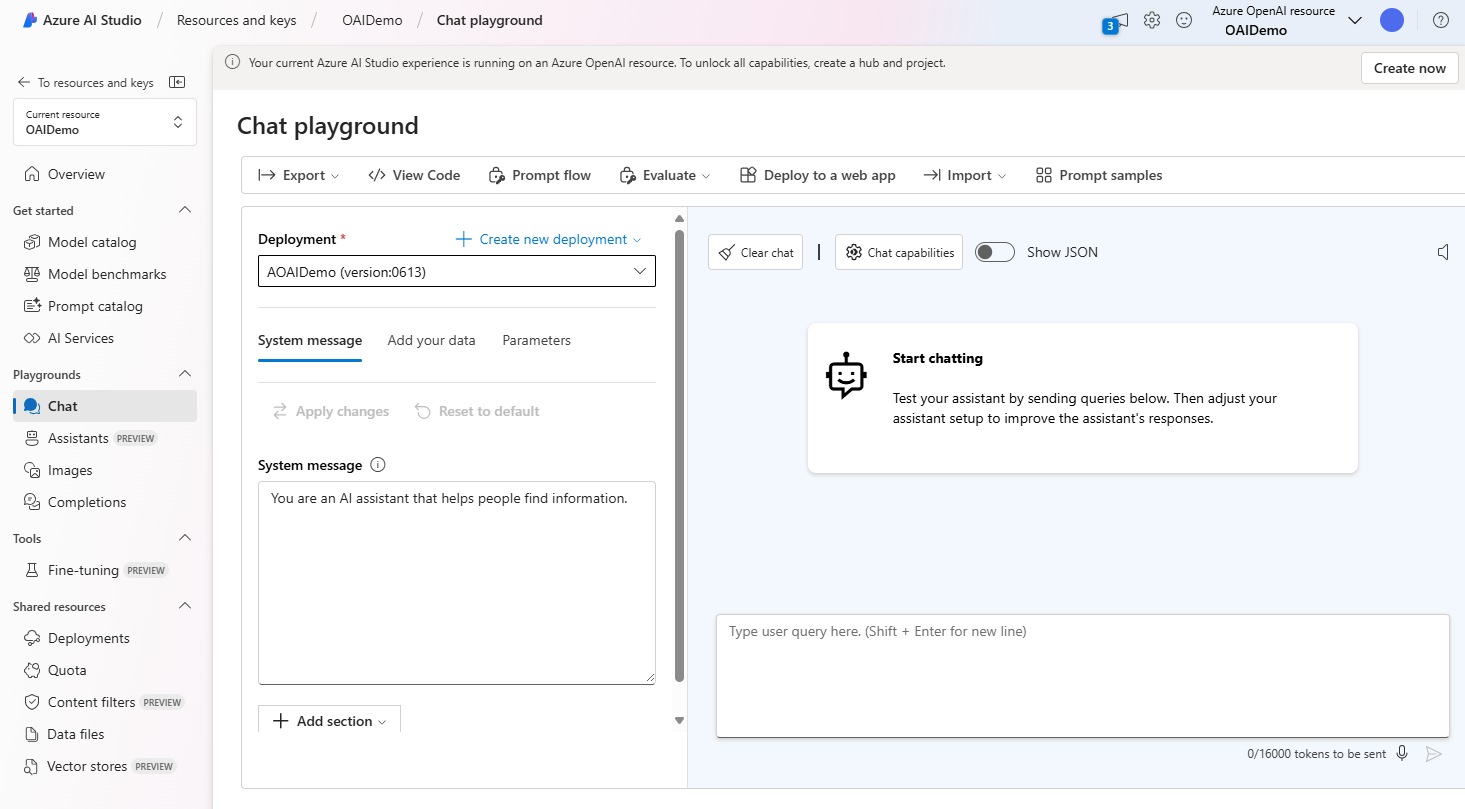
Parametry placu zabaw czatu
Plac zabaw czatu, taki jak plac zabaw ukończenia, zawiera również parametry dostosowywania zachowania modelu. Plac zabaw czatu obsługuje również inne parametry niedostępne na placu zabaw Ukończenie. Są to:
- Maksymalna odpowiedź: ustaw limit liczby tokenów na odpowiedź modelu. Interfejs API obsługuje maksymalnie 4000 tokenów udostępnianych między monitem (w tym komunikatem systemowym, przykładami, historią komunikatów i zapytaniem użytkownika) oraz odpowiedzią modelu. Jeden token ma mniej więcej cztery znaki dla typowego tekstu w języku angielskim.
- Poprzednie komunikaty zawarte: wybierz liczbę wcześniejszych komunikatów do uwzględnienia w każdym nowym żądaniu interfejsu API. Uwzględnienie poprzednich komunikatów pomaga nadać kontekstowi modelu dla nowych zapytań użytkowników. Ustawienie tej liczby na 10 będzie obejmować pięć zapytań użytkownika i pięć odpowiedzi systemowych.
Bieżąca liczba tokenów jest widoczna na placu zabaw czatu. Ponieważ wywołania interfejsu API są wyceniane według tokenu i można ustawić maksymalny limit tokenu odpowiedzi, należy zwrócić uwagę na bieżącą liczbę tokenów, aby upewnić się, że konwersacja nie przekracza maksymalnej liczby tokenów odpowiedzi.