Eksplorowanie i przetwarzanie danych za pomocą usługi Microsoft Fabric
Dane są podstawą nauki o danych, szczególnie w przypadku trenowania modelu uczenia maszynowego w celu osiągnięcia sztucznej inteligencji. Zazwyczaj modele wykazują zwiększoną wydajność w miarę wzrostu rozmiaru zestawu danych treningowych. Oprócz ilości danych jakość danych jest równie kluczowa.
Aby zagwarantować jakość i ilość danych, warto skorzystać z niezawodnych aparatów pozyskiwania danych i przetwarzania danych w usłudze Microsoft Fabric. Masz elastyczność, aby wybrać podejście typu "low-code" lub "code-first" podczas ustanawiania podstawowych potoków pozyskiwania, eksploracji i przekształcania danych.
Pozyskiwanie danych do usługi Microsoft Fabric
Aby pracować z danymi w usłudze Microsoft Fabric, należy najpierw pozyskiwać dane. Dane można pozyskiwać z wielu źródeł, zarówno lokalnych, jak i w chmurze. Można na przykład pozyskiwać dane z pliku CSV przechowywanego na komputerze lokalnym lub w usłudze Azure Data Lake Storage (Gen2).
Napiwek
Dowiedz się więcej na temat pozyskiwania i organizowania danych z różnych źródeł za pomocą usługi Microsoft Fabric.
Po nawiązaniu połączenia ze źródłem danych możesz zapisać dane w usłudze Microsoft Fabric Lakehouse. Możesz użyć lakehouse jako centralnej lokalizacji do przechowywania dowolnych plików ustrukturyzowanych, częściowo ustrukturyzowanych i nieustrukturyzowanych. Następnie możesz łatwo nawiązać połączenie z usługą Lakehouse za każdym razem, gdy chcesz uzyskać dostęp do danych w celu eksploracji lub transformacji.
Eksplorowanie i przekształcanie danych
Jako analityk danych możesz być najbardziej zaznajomiony z pisaniem i wykonywaniem kodu w notesach. Usługa Microsoft Fabric oferuje znane środowisko notesu obsługiwane przez środowisko obliczeniowe platformy Spark.
Apache Spark to platforma przetwarzania równoległego typu open source na potrzeby przetwarzania i analizy danych na dużą skalę.
Notesy są automatycznie dołączane do obliczeń platformy Spark. Po pierwszym uruchomieniu komórki w notesie zostanie uruchomiona nowa sesja platformy Spark. Sesja będzie się powtarzać po uruchomieniu kolejnych komórek. Sesja platformy Spark zostanie automatycznie zatrzymana po pewnym czasie braku aktywności, aby zaoszczędzić koszty. Możesz również ręcznie zatrzymać sesję.
Podczas pracy w notesie możesz wybrać język, którego chcesz użyć. W przypadku obciążeń nauki o danych prawdopodobnie będziesz pracować z rozwiązaniem PySpark (Python) lub SparkR (R).
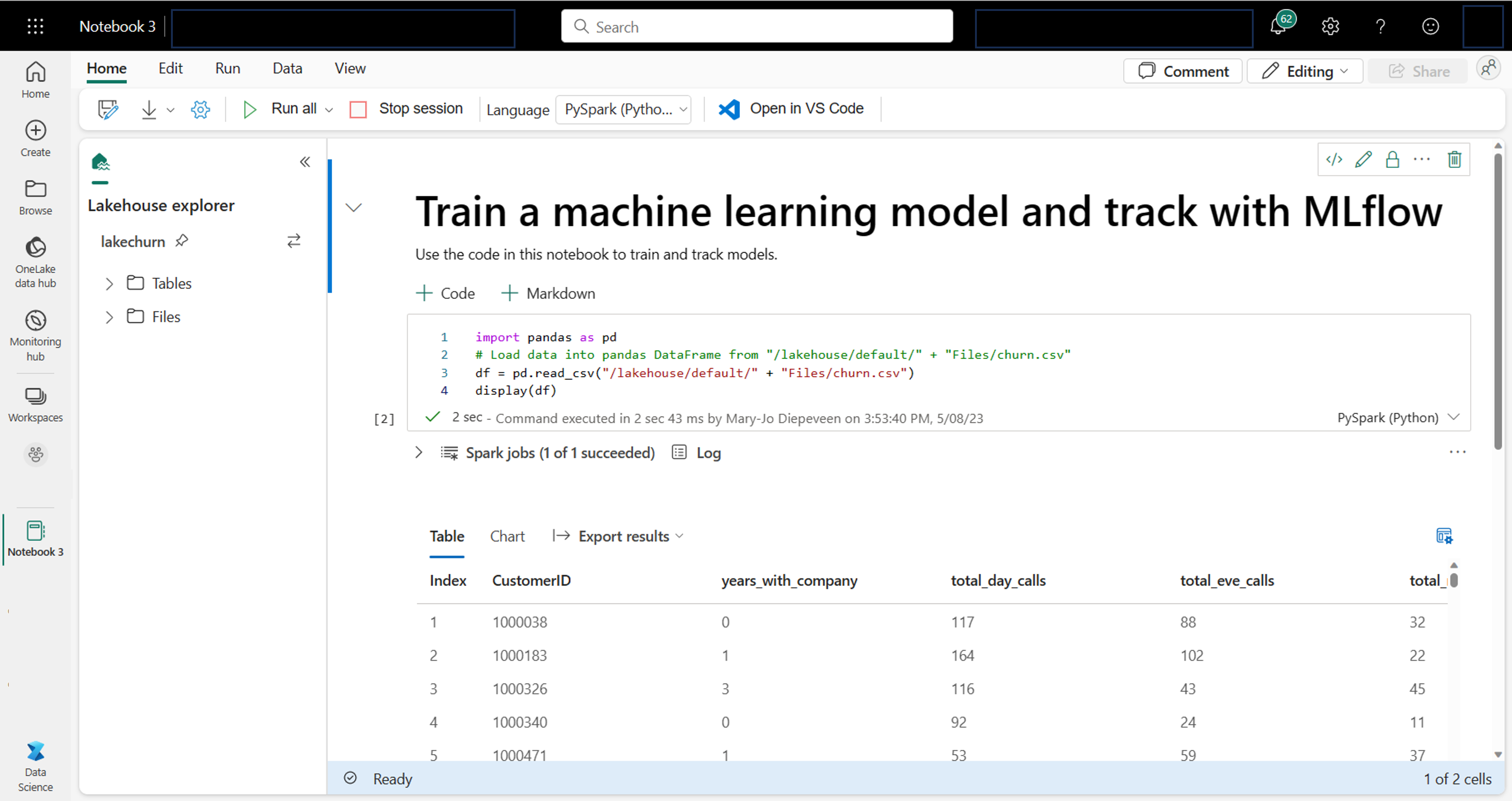
W notesie możesz eksplorować dane przy użyciu preferowanej biblioteki lub dowolnej z wbudowanych opcji wizualizacji. W razie potrzeby możesz przekształcić dane i zapisać przetworzone dane, zapisując je z powrotem do magazynu lakehouse.
Przygotowywanie danych za pomocą narzędzia Data Wrangler
Aby ułatwić szybsze eksplorowanie i przekształcanie danych, usługa Microsoft Fabric oferuje łatwą w użyciu usługę Data Wrangler.
Po uruchomieniu narzędzia Data Wrangler uzyskasz opisowe omówienie danych, z którymi pracujesz. Możesz wyświetlić podsumowanie statystyk danych, aby znaleźć wszelkie problemy, takie jak brakujące wartości.
Aby wyczyścić dane, możesz wybrać dowolną wbudowaną operację czyszczenia danych. Po wybraniu operacji zostanie automatycznie wygenerowany podgląd wyniku i skojarzony kod. Po wybraniu wszystkich niezbędnych operacji można wyeksportować przekształcenia do kodu i wykonać je na danych.