Ćwiczenie — wizualizowanie danych za pomocą operatora renderowania
Użyliśmy zestawu danych meteorologicznych do agregowania i porównywania liczby niektórych rodzajów zdarzeń burzowych w różnych stanach USA w roku 2007. W tym miejscu zwizualizujesz te wyniki przy użyciu wykresów przedziału czasu.
render Korzystanie z operatora
Pamiętaj, że operator został użyty summarize do grupowania zdarzeń według typowego pola, takiego jak Stan. W poprzedniej lekcji użyto różnych wersji count operatora, aby porównać liczbę i typy zdarzeń według stanu. Wizualizowanie tych wyników może być pomocną pomocą w porównywaniu aktywności między stanami.
Aby wizualizować wyniki, użyjesz render operatora . Ten operator znajduje się na końcu zapytania.
render W ramach operatora określisz typ wizualizacji do użycia, taki jak columnchart, barchart, piechart, scatterchart, , pivotcharti inne. Opcjonalnie można również zdefiniować różne właściwości wizualizacji, takie jak oś x lub oś y.
W tym przykładzie zwizualizujesz poprzednie zapytanie przy użyciu wykresu słupkowego.
Uruchom poniższe zapytanie.
StormEvents | summarize count(), EventsWithDamageToCrops = countif(DamageCrops > 0), dcount(EventType) by State | sort by count_ | render barchartPowinny zostać wyświetlone wyniki, które wyglądają jak na poniższej ilustracji:

Zwróć uwagę na legendę po prawej stronie wykresu słupkowego. Każda wartość w legendzie reprezentuje inną kolumnę danych, które zostały podsumowane przez element State w zapytaniu. Spróbuj wybrać jedną z wartości, takich jak count_, aby przełączyć wyświetlanie tych danych na wykresie słupkowym. Przełączając się poza count_, usuwasz łączną liczbę i pozostawiono liczbę zdarzeń, które spowodowały uszkodzenie i wyraźną liczbę zdarzeń. Powinien zostać wyświetlony wykres podobny do poniższego:
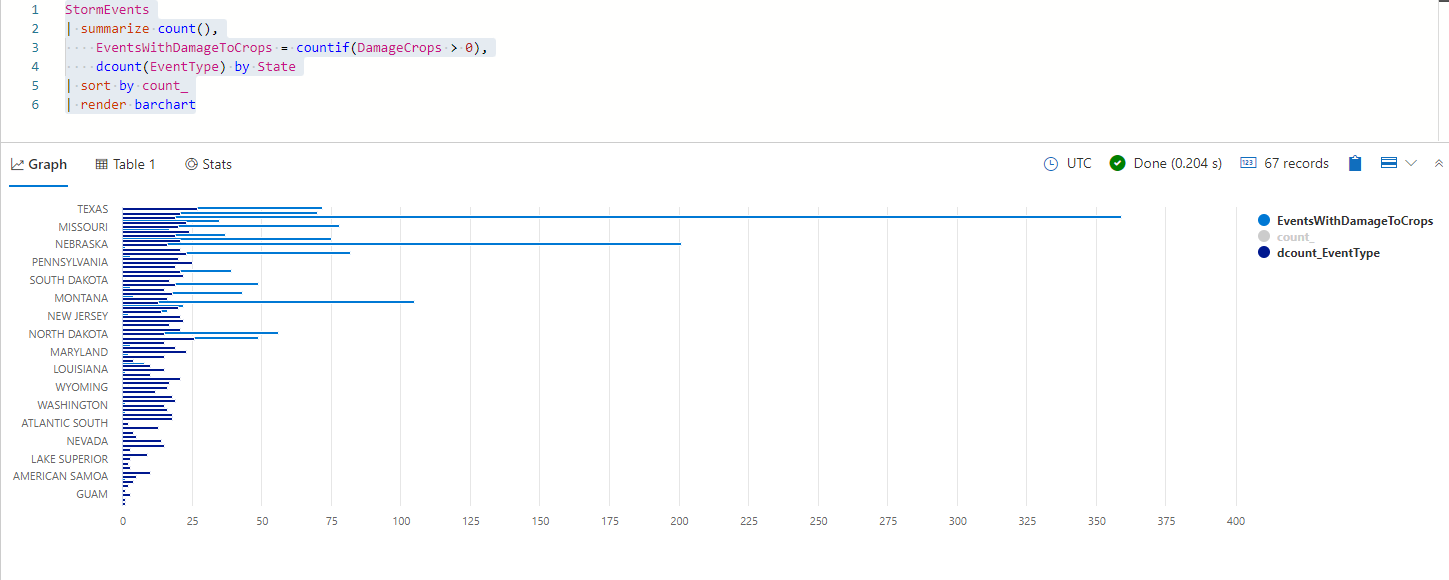
Spójrz na wynikowy wykres słupkowy. Jakie szczegółowe informacje można uzyskać z tego? Możesz na przykład zauważyć, że Texas miał najwięcej indywidualnych zdarzeń burzy, ale Iowa miała największą częstość występowania szkodliwych zdarzeń burzy.


Grupowanie wartości przy użyciu bin() funkcji
Do tej pory użyto funkcji agregacji do grupowania zdarzeń według stanu. Teraz przyjrzyjmy się rozkładowi burz przez cały rok, grupując dane według czasu. Wartości czasu, które mamy w każdym rekordzie, to czas rozpoczęcia i godzina zakończenia. Pogrupujmy czasy rozpoczęcia wydarzenia według tygodnia, aby zobaczyć, ile burz wydarzyło się każdego tygodnia w roku 2007.
Użyjesz bin() funkcji , która grupuje wartości w ustawione interwały. Na przykład możesz mieć dane z każdego dnia roku i chcesz zgrupować te daty według tygodnia. Możesz też pogrupować dane dotyczące populacji według przedziałów wieku. Składnia tego operatora to:
bin(wartość,roundTo)
Wartość pojemnika może być liczbą, datą lub przedziałem czasu. Zagregujesz liczbę przy użyciu bin() funkcji , aby nadać liczbę zdarzeń tygodniowo.
Wartość, którą chcesz zgrupować, to Godzina rozpoczęcia zdarzenia burzy z rozmiarem roundTo bin 7 dni lub 7d na krótko. Na koniec renderuj dane jako wykres kolumnowy, aby utworzyć histogram.
Uruchom poniższe zapytanie:
StormEvents | summarize count() by bin(StartTime, 7d) | render columnchartPowinny zostać wyświetlone wyniki, które wyglądają jak na poniższej ilustracji:
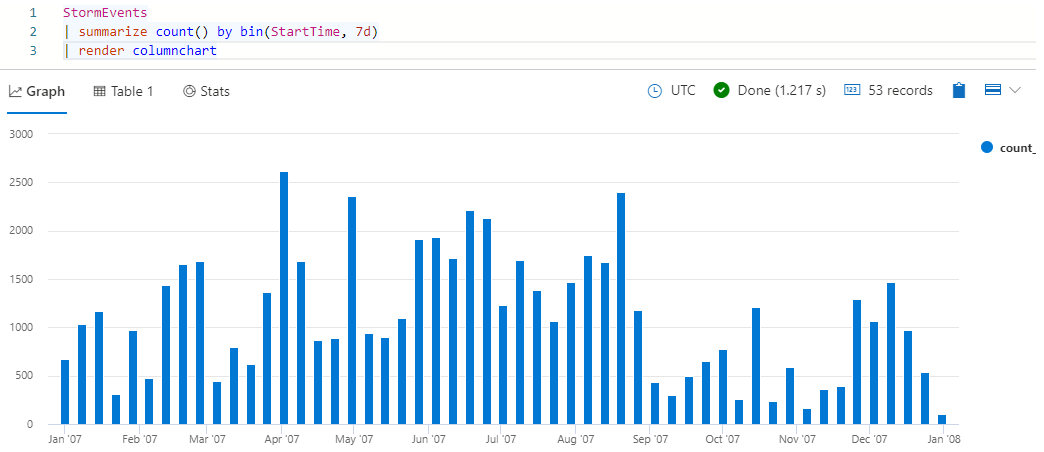
Przyjrzyj się wynikowem histogramowi. Umieść kursor na jednym z pasków, aby zobaczyć czas rozpoczęcia pojemnika (x-wartość) i liczbę zdarzeń (y-value).
sum Korzystanie z operatora
W poprzednim zapytaniu przyjrzeliśmy się liczbie zdarzeń burzy w czasie. Teraz przyjrzyjmy się szkodom spowodowanym przez te burze. W tym celu użyjesz sum funkcji agregacji, ponieważ chcesz zobaczyć łączną ilość szkód spowodowanych w każdym interwale czasu. Zestaw danych, z którym pracujesz, ma dwie kolumny związane z uszkodzeniem: DamageProperty i DamageCrops.
W poniższym zapytaniu najpierw utworzysz kolumnę obliczeniową, która dodaje te dwa źródła uszkodzeń. Następnie utworzysz agregację całkowitego uszkodzenia pojemnika na tydzień. Na koniec renderujesz wykres kolumnowy reprezentujący cotygodniowe szkody spowodowane przez wszystkie burze.
Uruchom poniższe zapytanie:
StormEvents | extend damage = DamageProperty + DamageCrops | summarize sum(damage) by bin(StartTime, 7d) | render columnchartPowinny zostać wyświetlone wyniki, które wyglądają jak na poniższej ilustracji:
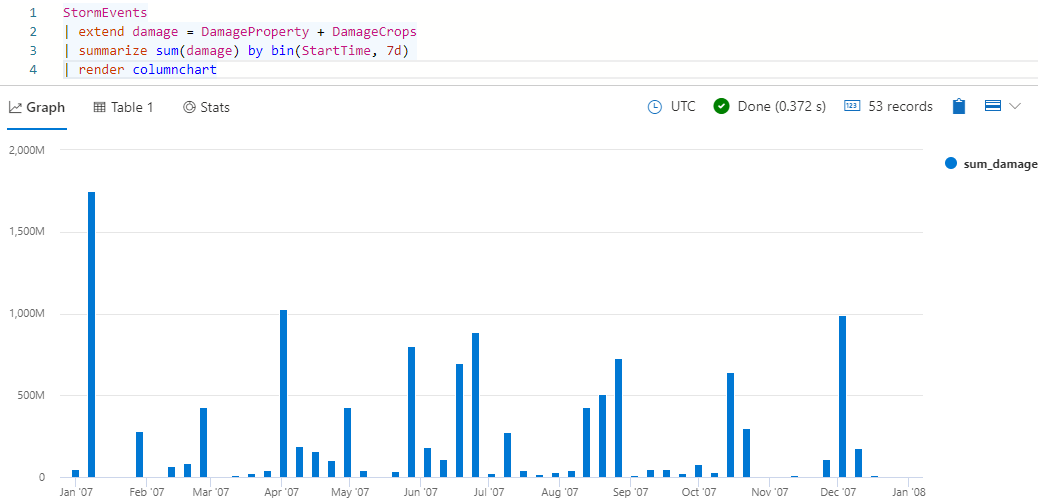
Poprzednie zapytanie pokazuje, że uszkodzenie jest funkcją czasu. Innym sposobem porównania szkód jest typ zdarzenia. Uruchom następujące zapytanie, aby użyć wykresu kołowego, aby porównać szkody spowodowane przez różne typy zdarzeń.
StormEvents | extend damage = DamageProperty + DamageCrops | summarize sum(damage) by EventType | render piechartPowinny zostać wyświetlone wyniki, które wyglądają jak na poniższej ilustracji:
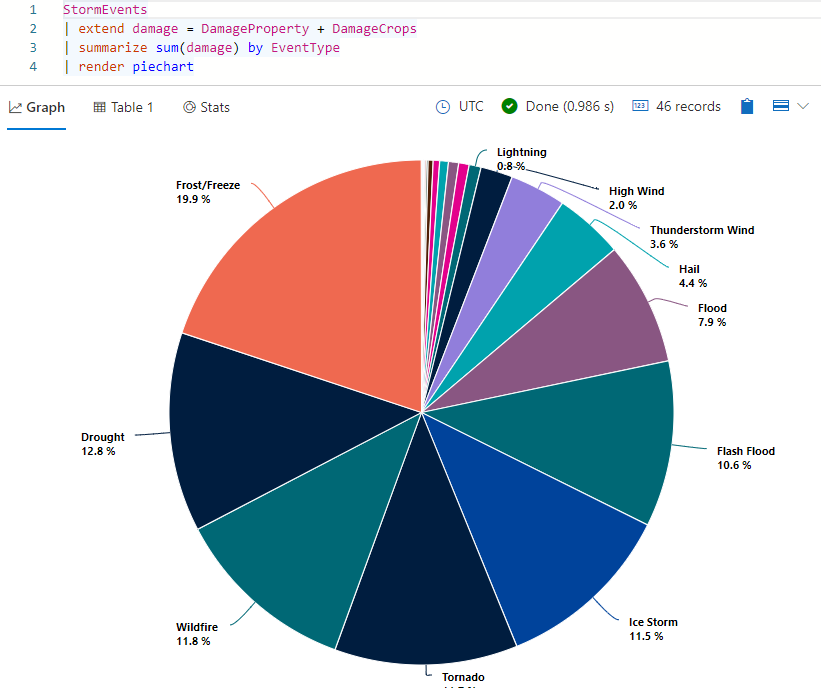
Umieść kursor na jednym z wycinków wykresu kołowego. Powinna zostać wyświetlona wartość bezwzględna (łączna szkoda spowodowana tym typem zdarzenia) oraz odpowiedni procent całkowitego uszkodzenia.