Regresja
Modele regresji są trenowane w celu przewidywania wartości etykiet liczbowych na podstawie danych treningowych, które obejmują zarówno funkcje, jak i znane etykiety. Proces trenowania modelu regresji (lub nawet dowolnego nadzorowanego modelu uczenia maszynowego) obejmuje wiele iteracji, w których używasz odpowiedniego algorytmu (zwykle z pewnymi ustawieniami sparametryzowanymi) do trenowania modelu, oceny wydajności predykcyjnej modelu i uściślić model, powtarzając proces trenowania przy użyciu różnych algorytmów i parametrów do momentu osiągnięcia akceptowalnego poziomu dokładności predykcyjnej.
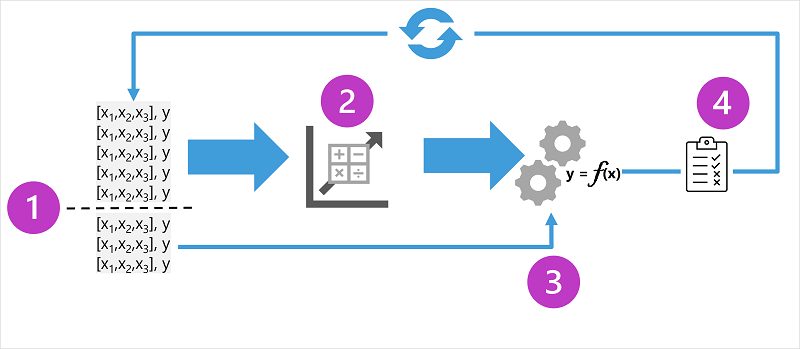
Diagram przedstawia cztery kluczowe elementy procesu trenowania dla nadzorowanych modeli uczenia maszynowego:
- Podziel dane treningowe (losowo), aby utworzyć zestaw danych, za pomocą którego należy wytrenować model przy jednoczesnym zachowaniu podzbioru danych, których użyjesz do zweryfikowania wytrenowanego modelu.
- Użyj algorytmu, aby dopasować dane treningowe do modelu. W przypadku modelu regresji użyj algorytmu regresji, takiego jak regresja liniowa.
- Użyj danych weryfikacji, które zostały wstrzymane, aby przetestować model, przewidując etykiety dla funkcji.
- Porównaj znane rzeczywiste etykiety w zestawie danych weryfikacji z etykietami przewidywanymi przez model. Następnie zagreguj różnice między przewidywanymi i rzeczywistymi wartościami etykiet, aby obliczyć metrykę wskazującą, jak dokładnie model przewiduje dane walidacji.
Po każdym trenowaniu, weryfikowaniu i ocenianiu iteracji można powtórzyć proces przy użyciu różnych algorytmów i parametrów, dopóki nie zostanie osiągnięta akceptowalna metryka oceny.
Przykład — regresja
Przyjrzyjmy się regresji z uproszczonym przykładem, w którym wytrenujemy model w celu przewidywania etykiety liczbowej (y) na podstawie pojedynczej wartości funkcji (x). Większość rzeczywistych scenariuszy obejmuje wiele wartości funkcji, co zwiększa złożoność; ale zasada jest taka sama.
W naszym przykładzie będziemy trzymać się scenariusza sprzedaży lodów omówionych wcześniej. W przypadku naszej funkcji rozważymy temperaturę (załóżmy, że wartość jest maksymalną temperaturą w danym dniu), a etykieta, którą chcemy wytrenować model, aby przewidzieć, to liczba sprzedanych lodów tego dnia. Zaczniemy od niektórych historycznych danych, które obejmują rekordy dziennych temperatur (x) i sprzedaż lodów (y):
 |
 |
|---|---|
| Temperatura (x) | Sprzedaż lodów (y) |
| 51 | 1 |
| 52 | 0 |
| 67 | 14 |
| 65 | 14 |
| 70 | 23 |
| 69 | 20 |
| 72 | 23 |
| 75 | 26 |
| 73 | 22 |
| 81 | 30 |
| 78 | 26 |
| 83 | 36 |
Trenowanie modelu regresji
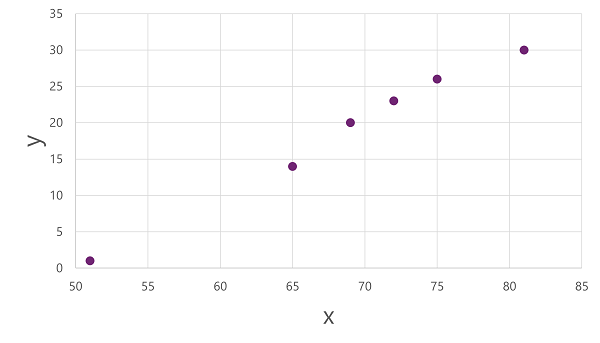
Zaczniemy od podzielenia danych i użycia podzbioru danych w celu wytrenowania modelu. Oto zestaw danych treningowych:
| Temperatura (x) | Sprzedaż lodów (y) |
|---|---|
| 51 | 1 |
| 65 | 14 |
| 69 | 20 |
| 72 | 23 |
| 75 | 26 |
| 81 | 30 |
Aby uzyskać szczegółowe informacje o tym, jak te wartości x i y mogą odnosić się do siebie nawzajem, możemy wykreślić je jako współrzędne wzdłuż dwóch osi, w następujący sposób:
Teraz możemy zastosować algorytm do naszych danych treningowych i dopasować go do funkcji, która stosuje operację x do obliczenia y. Jednym z takich algorytmów jest regresja liniowa, która działa poprzez wyprowadzenie funkcji, która tworzy linię prostą przez przecięcia wartości x i y, jednocześnie minimalizując średnią odległość między linią a wykreślowanymi punktami, w następujący sposób:
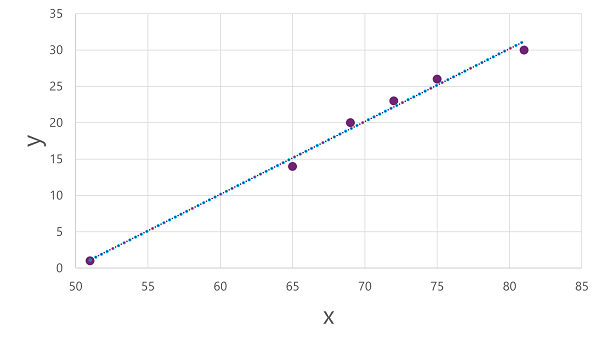
Linia jest wizualną reprezentacją funkcji, w której nachylenie linii opisuje sposób obliczania wartości y dla danej wartości x. Linia przechwytuje oś x na 50, więc gdy x wynosi 50, y wynosi 0. Jak widać ze znaczników osi na wykresie, nachylenie linii tak, aby każdy wzrost o 5 wzdłuż osi x zwiększał się o 5 w górę osi y, więc gdy x wynosi 55, y wynosi 5; gdy x wynosi 60, y wynosi 10 itd. Aby obliczyć wartość y dla danej wartości x, funkcja po prostu odejmuje 50; innymi słowy, funkcja może być wyrażona w następujący sposób:
f(x) = x-50
Za pomocą tej funkcji można przewidzieć liczbę lodów sprzedawanych w ciągu dnia z daną temperaturą. Załóżmy na przykład, że prognoza pogody informuje nas, że jutro będzie to 77 stopni. Możemy zastosować nasz model, aby obliczyć 77-50 i przewidzieć, że będziemy sprzedawać 27 lodów jutro.
Ale jak dokładny jest nasz model?
Ocenianie modelu regresji
Aby zweryfikować model i ocenić, jak dobrze przewiduje, wstrzymaliśmy pewne dane, dla których znamy wartość etykiety (y). Oto dane, które wstrzymaliśmy:
| Temperatura (x) | Sprzedaż lodów (y) |
|---|---|
| 52 | 0 |
| 67 | 14 |
| 70 | 23 |
| 73 | 22 |
| 78 | 26 |
| 83 | 36 |
Za pomocą modelu możemy przewidzieć etykietę dla każdego z obserwacji w tym zestawie danych na podstawie wartości funkcji (x), a następnie porównać przewidywaną etykietę (ŷ) ze znaną rzeczywistą wartością etykiety (y).
Przy użyciu modelu, który trenowaliśmy wcześniej, który hermetyzuje funkcję f(x) = x-50, powoduje następujące przewidywania:
| Temperatura (x) | Rzeczywista sprzedaż (y) | Przewidywana sprzedaż (ŷ) |
|---|---|---|
| 52 | 0 | 2 |
| 67 | 14 | 17 |
| 70 | 23 | 20 |
| 73 | 22 | 23 |
| 78 | 26 | 28 |
| 83 | 36 | 33 |
Możemy wykreślić zarówno przewidywane, jak i rzeczywiste etykiety względem wartości funkcji w następujący sposób:
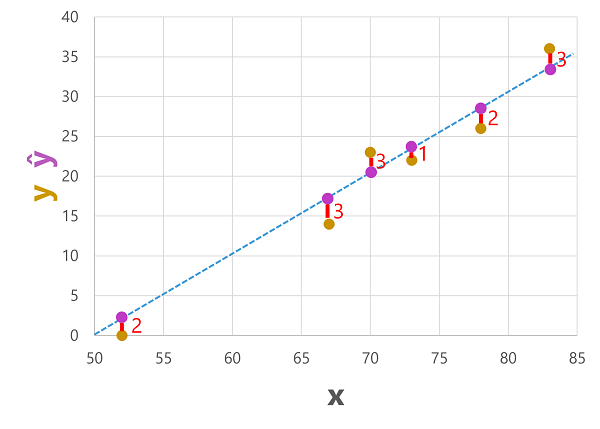
Przewidywane etykiety są obliczane przez model, więc znajdują się one w wierszu funkcji, ale istnieje pewna wariancja między wartościami ŷ obliczanymi przez funkcję i rzeczywistymi wartościami y z zestawu danych walidacji, co jest wskazywane na wykresie jako linia między wartościami ŷ i y, które pokazują, jak daleko przewidywano od rzeczywistej wartości.
Metryki oceny regresji
Na podstawie różnic między przewidywanymi i rzeczywistymi wartościami można obliczyć niektóre typowe metryki używane do oceny modelu regresji.
Średni błąd bezwzględny (MAE)
Wariancja w tym przykładzie wskazuje, ile lodów każde przewidywanie było błędne. Nie ma znaczenia, czy przewidywanie było powyżej lub w wartości rzeczywistej (więc na przykład -3 i +3 wskazują wariancję 3). Ta metryka jest znana jako błąd bezwzględny dla każdego przewidywania i może zostać podsumowana dla całego zestawu weryfikacji jako błąd bezwzględny średniej (MAE).
W przykładzie lodów średnia (średnia) błędów bezwzględnych (2, 3, 3, 1, 2 i 3) wynosi 2,33.
Błąd średniokwadratowy (MSE)
Metryka błędu bezwzględnego średniej bierze pod uwagę wszystkie rozbieżności między przewidywanymi i rzeczywistymi etykietami. Jednak bardziej pożądane może być posiadanie modelu, który jest stale mylące przez niewielką ilość niż taki, który sprawia, że mniej, ale większe błędy. Jednym ze sposobów utworzenia metryki, która "wzmacnia" większe błędy poprzez kwadrat poszczególnych błędów i obliczenie średniej wartości kwadratowych. Ta metryka jest znana jako błąd średniokwadratowy (MSE).
W naszym przykładzie lodów średnia wartości bezwzględnych kwadratu (czyli 4, 9, 9, 1, 4 i 9) wynosi 6.
Błąd średniokwadratowy (RMSE)
Błąd średniokwadratowy pomaga wziąć pod uwagę wielkość błędów, ale ponieważ kwadraty wartości błędów, wynikowa metryka nie reprezentuje już ilości mierzonej przez etykietę. Innymi słowy, możemy powiedzieć, że MSE naszego modelu wynosi 6, ale nie mierzy jego dokładności pod względem liczby lodów, które zostały nieprawidłowo sformułowane; 6 to tylko wynik liczbowy, który wskazuje poziom błędu w przewidywaniach walidacji.
Jeśli chcemy zmierzyć błąd pod względem liczby lodów, musimy obliczyć pierwiastek kwadratowy MSE, który generuje metrykę o nazwie, nic dziwnego, głównego błędu średniokwadratowego. W tym przypadku √6, czyli 2,45 (lody).
Współczynnik determinacji (R2)
Wszystkie metryki do tej pory porównują rozbieżność między przewidywanymi i rzeczywistymi wartościami w celu oceny modelu. Jednak w rzeczywistości istnieje pewna naturalna losowa wariancja w dziennej sprzedaży lodów, którą model uwzględnia. W modelu regresji liniowej algorytm trenowania pasuje do linii prostej, która minimalizuje średnią wariancję między funkcją a znanymi wartościami etykiet. Współczynnik determinacji (najczęściej określany jako R2 lub R-Squared) to metryka, która mierzy proporcję wariancji w wynikach walidacji, które można wyjaśnić przez model, w przeciwieństwie do niektórych nietypowych aspektów danych walidacji (na przykład dzień z bardzo nietypową liczbą sprzedaży lodów z powodu festiwalu lokalnego).
Obliczanie dla języka R2 jest bardziej złożone niż w przypadku poprzednich metryk. Porównuje sumę różnic kwadratowych między przewidywanymi i rzeczywistymi etykietami z sumą kwadratowych różnic między rzeczywistymi wartościami etykiety a średnią rzeczywistych wartości etykiet, w następujący sposób:
R2 = 1- ∑(y-ŷ)2 ÷ ∑(y-ȳ)2
Nie martw się zbytnio, jeśli wygląda to skomplikowane; większość narzędzi uczenia maszynowego może obliczyć metryki. Ważnym punktem jest to, że wynik jest wartością z zakresu od 0 do 1, która opisuje proporcję wariancji wyjaśnionej przez model. Mówiąc prosto, im bliżej 1 jest ta wartość, tym lepiej model pasuje do danych walidacji. W przypadku modelu regresji lodów R2 obliczonego na podstawie danych walidacji wynosi 0,95.
Szkolenie iteracyjne
Opisane powyżej metryki są często używane do oceny modelu regresji. W większości rzeczywistych scenariuszy analityk danych będzie używać procesu iteracyjnego do wielokrotnego trenowania i oceniania modelu, różniąc się:
- Wybór i przygotowanie funkcji (wybór funkcji do uwzględnienia w modelu i zastosowanych do nich obliczeń w celu zapewnienia lepszego dopasowania).
- Wybór algorytmu (omówiliśmy regresję liniową w poprzednim przykładzie, ale istnieje wiele innych algorytmów regresji)
- Parametry algorytmu (ustawienia liczbowe służące do kontrolowania zachowania algorytmu, dokładniej nazywane hiperparametrami w celu odróżnienia ich od parametrów x i y).
Po wielu iteracji model, który powoduje wybranie najlepszej metryki oceny akceptowalnej dla konkretnego scenariusza.