Zwiększanie wydajności modelu językowego
Po wdrożeniu modelu w punkcie końcowym możesz wchodzić w interakcje z modelem, aby dowiedzieć się, jak działa. Jeśli chcesz dostosować model do swojego przypadku użycia, istnieje kilka strategii optymalizacji, które można zastosować w celu zwiększenia wydajności modelu. Przyjrzyjmy się różnym strategiom.
Rozmowa z modelem na placu zabaw
Możesz użyć preferowanego języka kodowania, aby wywołać interfejs API do punktu końcowego modelu lub porozmawiać z modelem bezpośrednio na placu zabaw portalu Azure AI Foundry. Plac zabaw dla czatów to szybki i łatwy sposób eksperymentowania i poprawiania wydajności modelu.
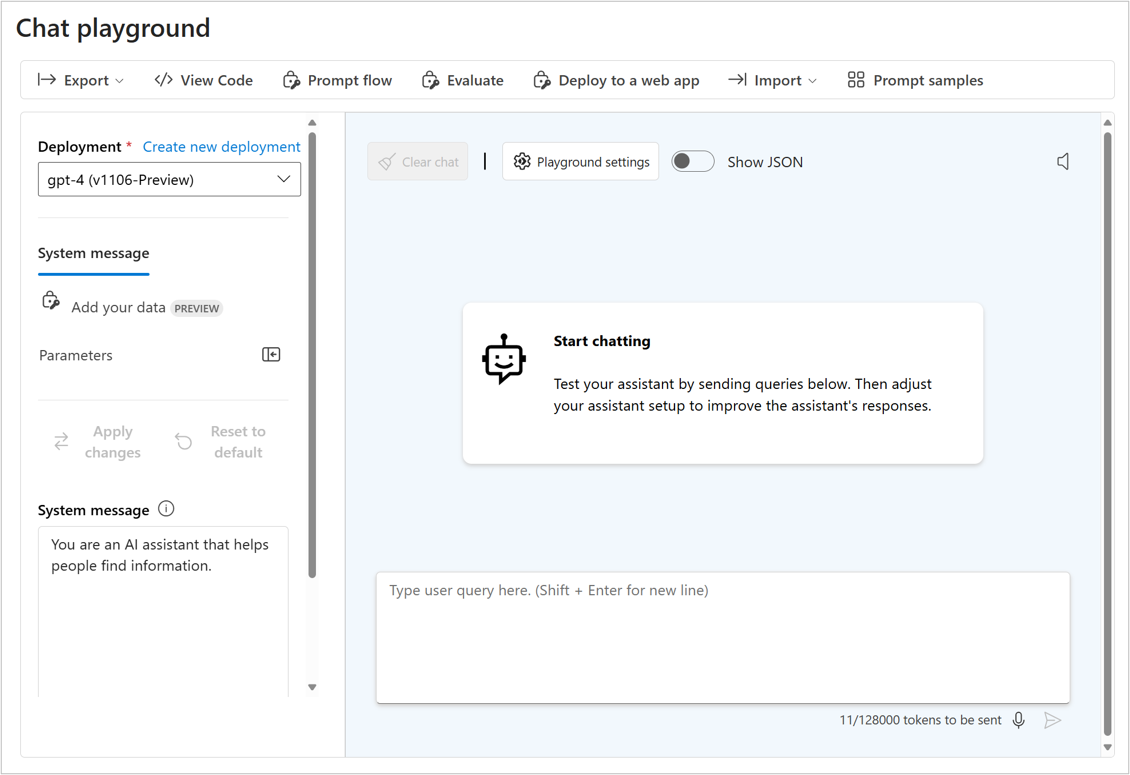
Jakość pytań wysyłanych do modelu językowego ma bezpośredni wpływ na jakość odpowiedzi, które otrzymujesz. Możesz dokładnie skonstruować swoje pytanie lub monitować, aby otrzymywać lepsze i bardziej interesujące odpowiedzi. Proces projektowania i optymalizowania monitów o poprawę wydajności modelu jest również nazywany inżynierią monitu. Gdy użytkownik końcowy udostępnia odpowiednie, specyficzne, jednoznaczne i dobrze ustrukturyzowane monity, model może lepiej zrozumieć kontekst i wygenerować dokładniejsze odpowiedzi.
Stosowanie inżynierii monitu
Podczas rozmowy z modelem na placu zabaw możesz zastosować kilka technik inżynierii monitów, aby sprawdzić, czy poprawia dane wyjściowe modelu.
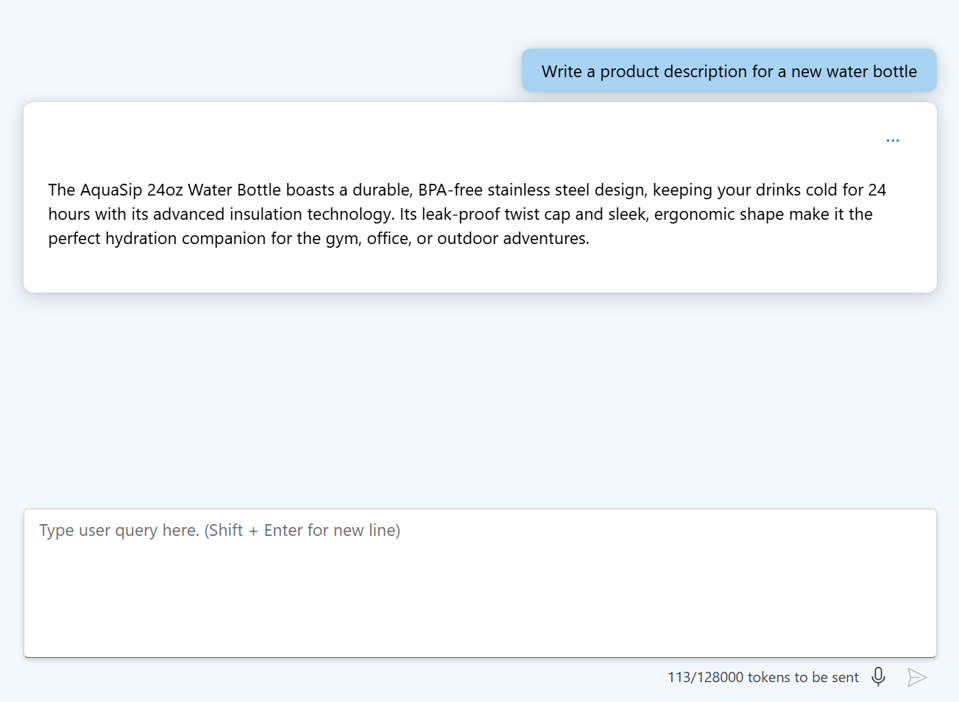
Przyjrzyjmy się niektórym technikom, których użytkownik końcowy może użyć do zastosowania inżynierii monitu:
- Podaj jasne instrukcje: podaj szczegółowe informacje o żądanych danych wyjściowych.
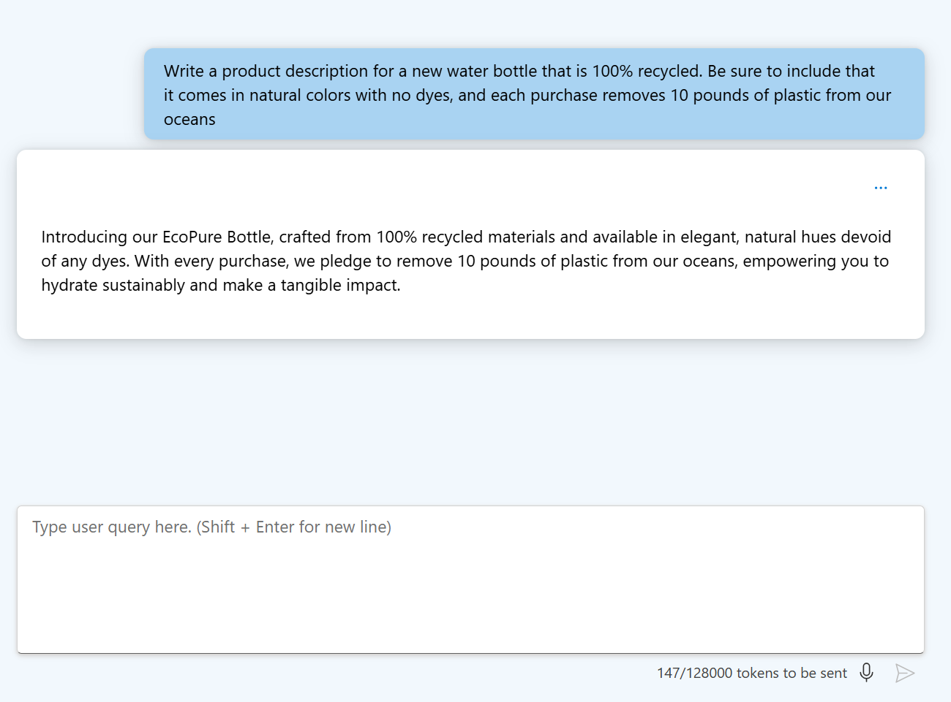
- Sformatuj instrukcje: użyj nagłówków i delineatorów, aby ułatwić odczytywanie pytania.
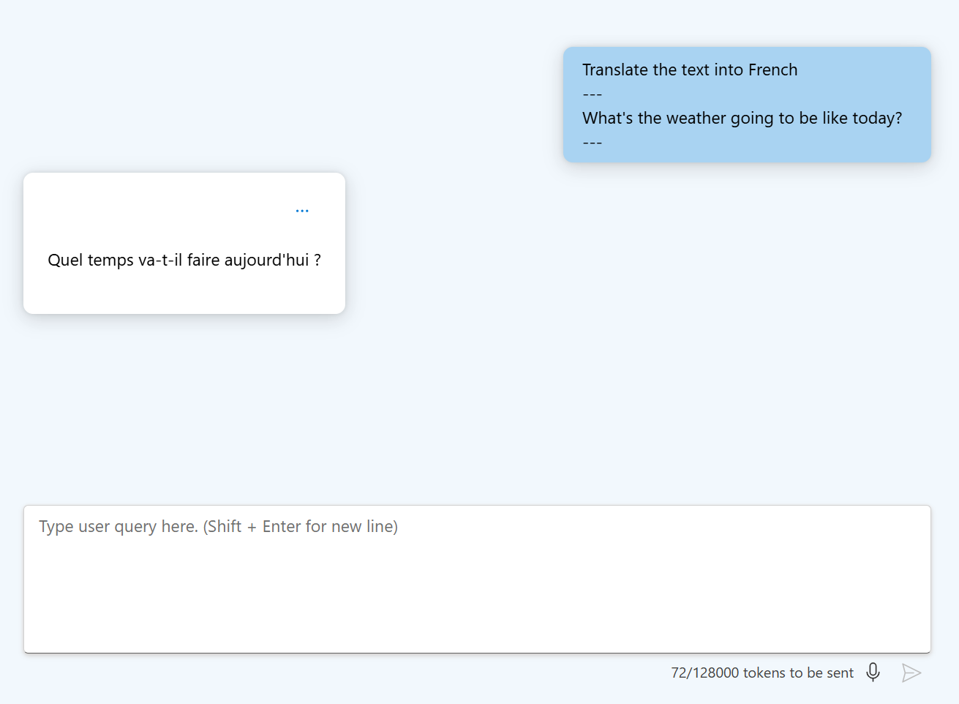
- Użyj wskazówek: podaj kluczowe słowa lub wskaźniki dotyczące sposobu, w jaki model powinien uruchomić odpowiedź, na przykład określony język kodowania.
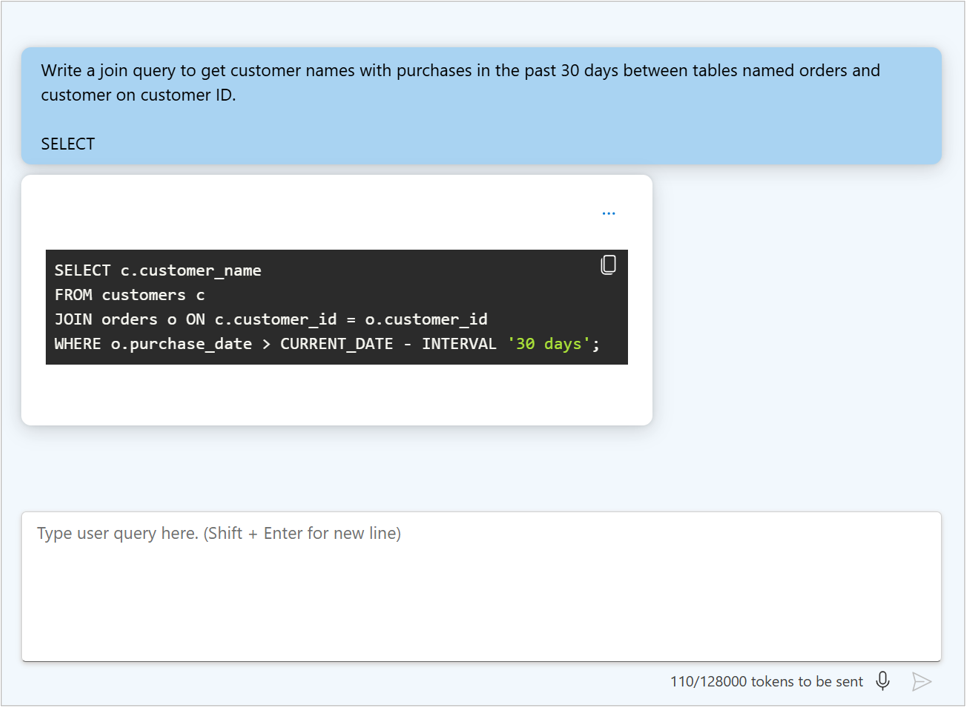
Aktualizowanie komunikatu systemowego
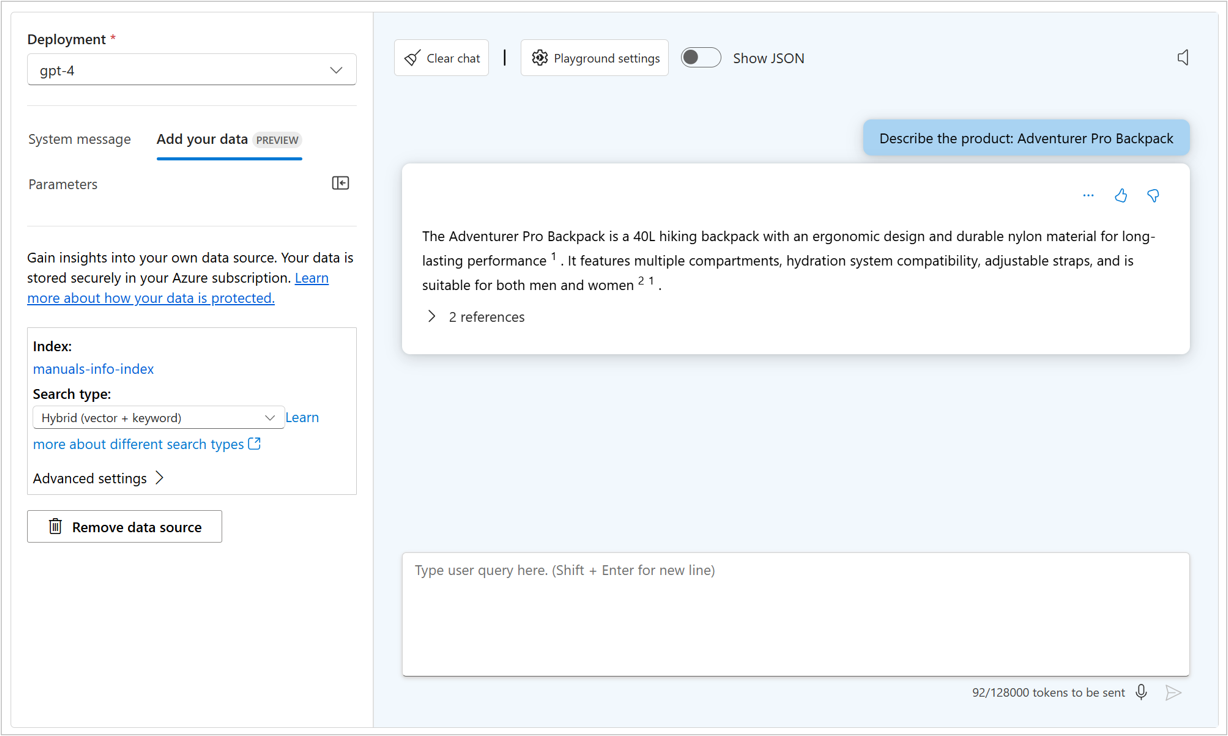
Na placu zabaw czatu możesz wyświetlić kod JSON bieżącej konwersacji, wybierając pozycję Pokaż kod JSON:
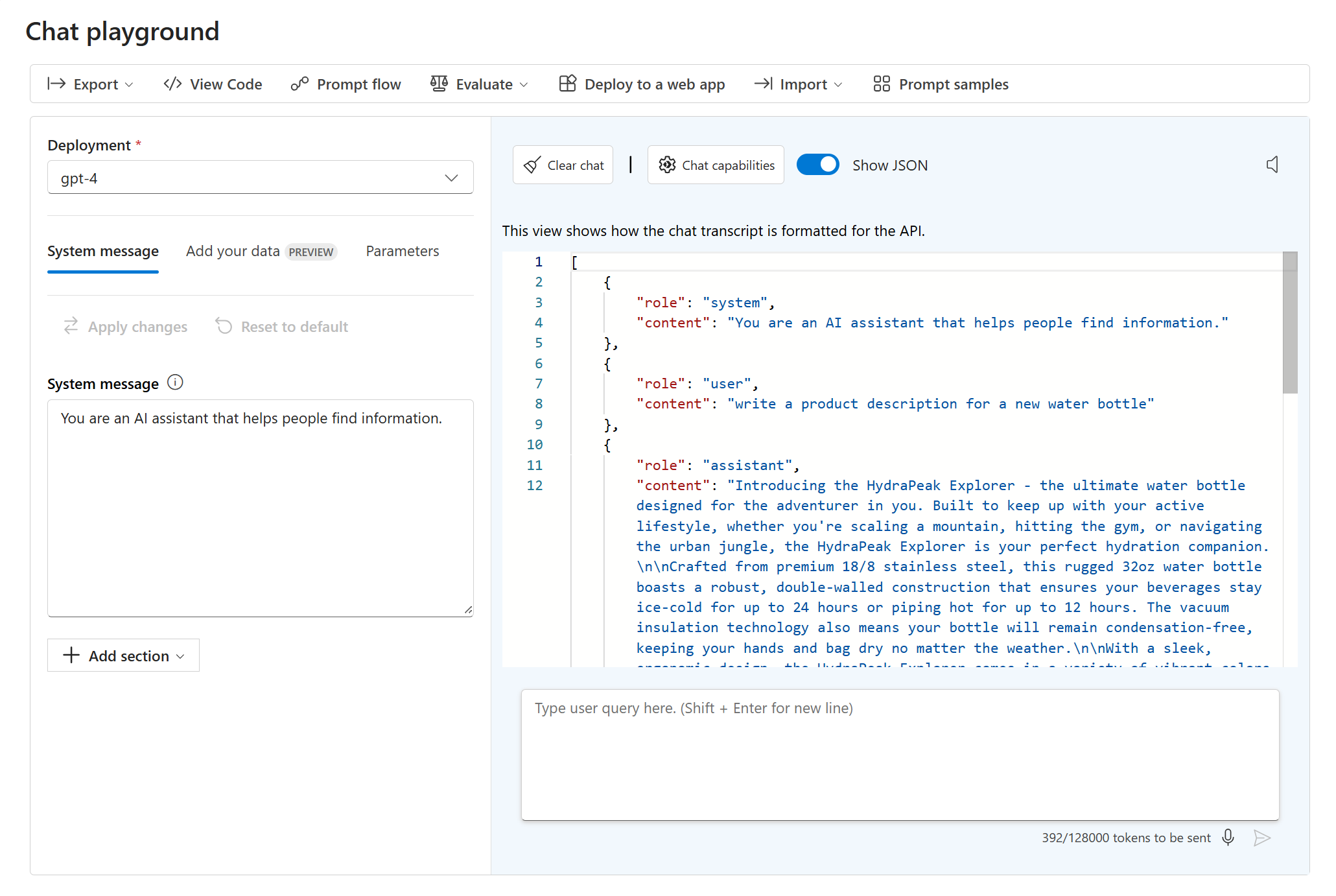
Pokazany kod JSON to dane wejściowe do punktu końcowego modelu za każdym razem, gdy wysyłasz nowy komunikat. Komunikat systemowy jest zawsze częścią danych wejściowych. Chociaż nie jest widoczny dla użytkowników końcowych, komunikat systemowy umożliwia deweloperowi dostosowanie zachowania modelu przez podanie instrukcji dotyczących jego zachowania.
Oto niektóre typowe techniki inżynieryjne monitów, które mają być stosowane jako deweloper, aktualizując komunikat systemowy:
- Użyj jednego strzału lub kilku strzałów: podaj co najmniej jeden przykład, aby ułatwić modelowi zidentyfikowanie żądanego wzorca. Możesz dodać sekcję do komunikatu systemowego, aby dodać co najmniej jeden przykład.
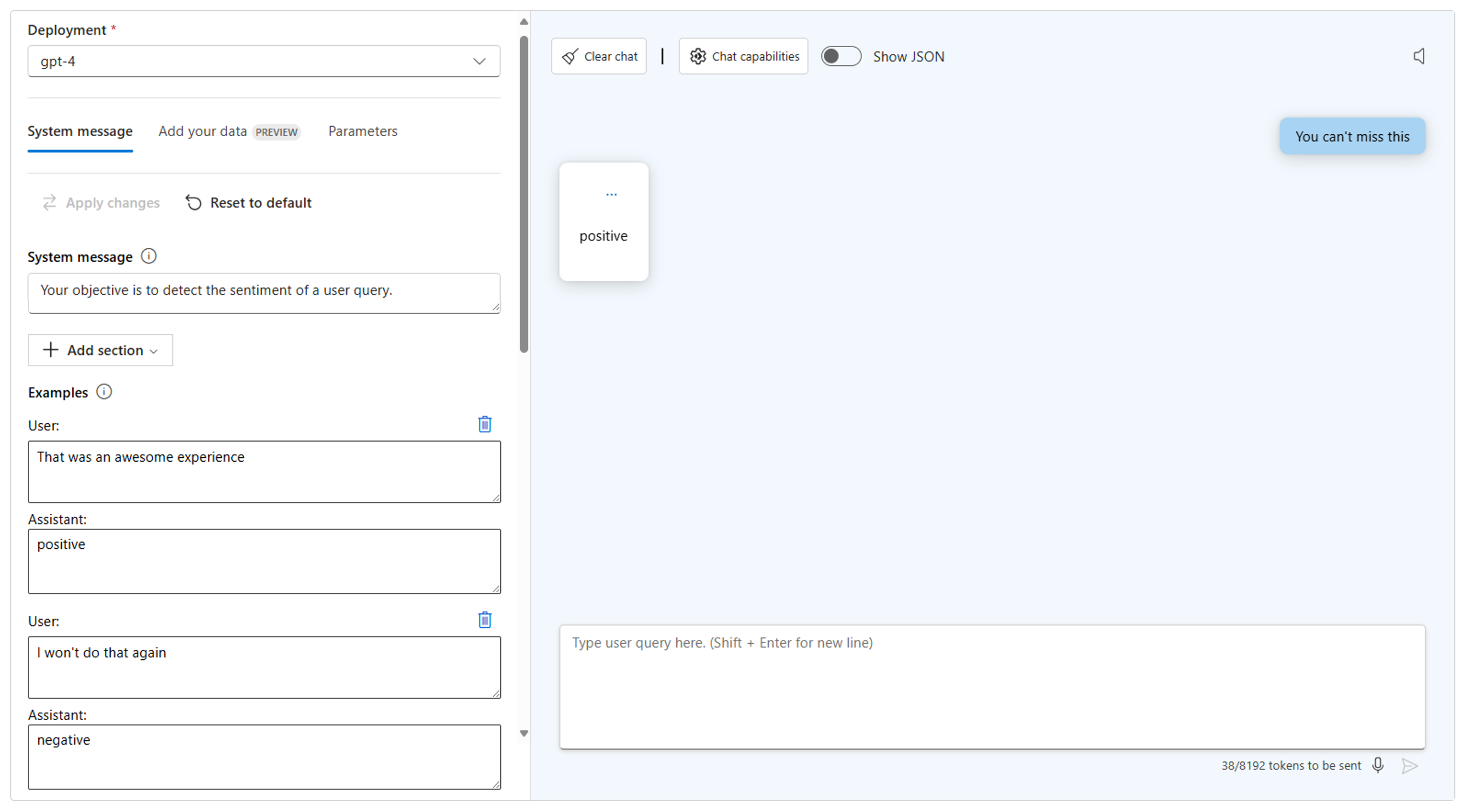
- Użyj łańcucha myśli: poinstruuj model, aby uzasadnić krok po kroku, poinstruując go, aby zastanowić się nad zadaniem.
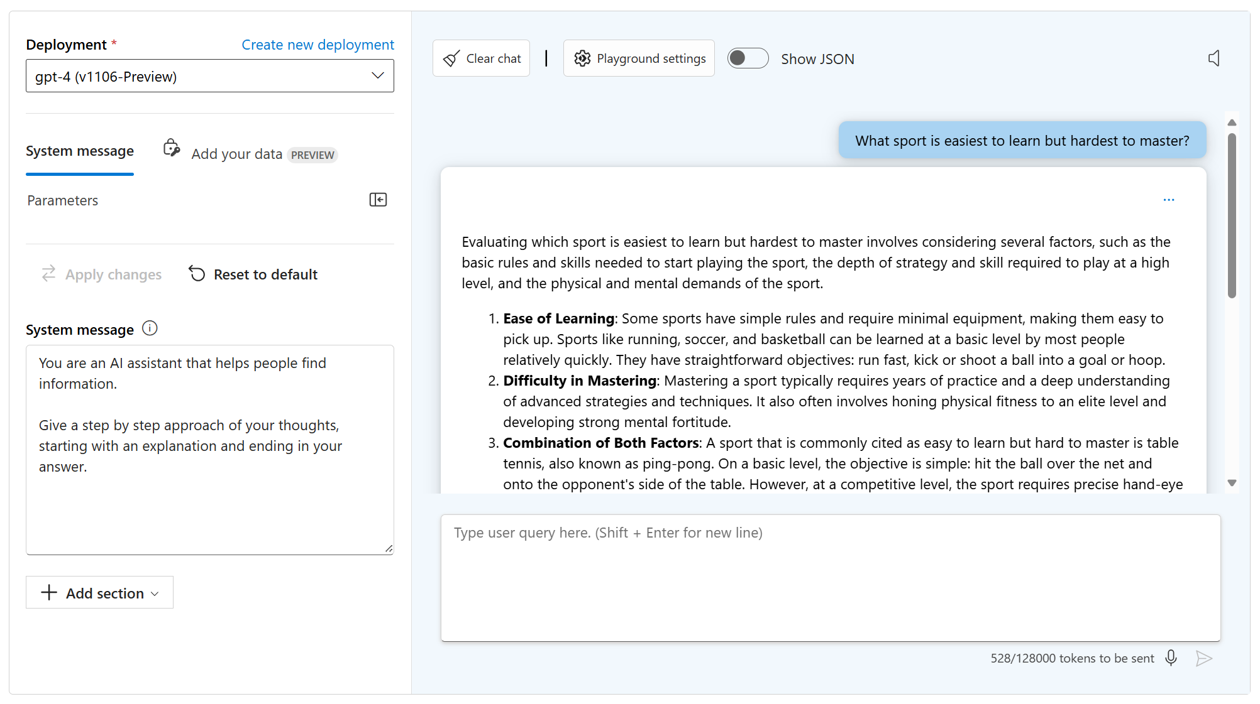
- Dodaj kontekst: Zwiększ dokładność modelu, podając kontekst lub informacje podstawowe istotne dla zadania. Kontekst można podać za pomocą danych uziemienia dostarczonych w wierszu polecenia użytkownika lub przez połączenie własnego źródła danych.
Stosowanie strategii optymalizacji modelu
Jako deweloper możesz również zastosować inne strategie optymalizacji, aby poprawić wydajność modelu bez konieczności pisania określonych monitów przez użytkownika końcowego. Obok monitu inżynieryjnego wybrana strategia zależy od wymagań:
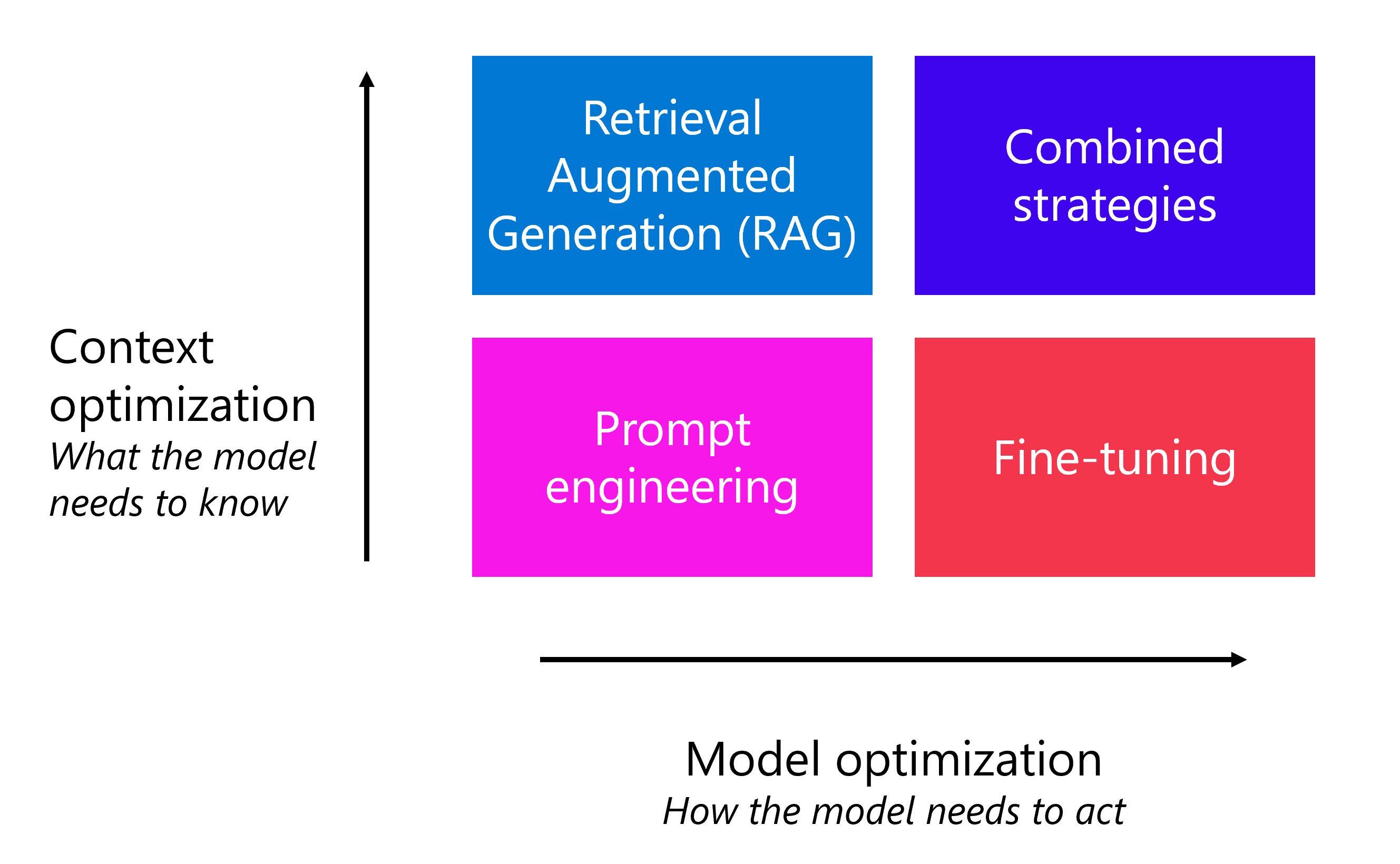
- Optymalizacja pod kątem kontekstu: gdy model nie ma kontekstowej wiedzy i chcesz zmaksymalizować dokładność odpowiedzi.
- Zoptymalizuj model: Jeśli chcesz ulepszyć format odpowiedzi, styl lub mowę, maksymalizując spójność zachowania.
Aby zoptymalizować kontekst, można zastosować wzorzec generacji rozszerzonej (RAG). Za pomocą programu RAG uziemisz dane, najpierw pobierając kontekst ze źródła danych przed wygenerowaniem odpowiedzi. Na przykład chcesz, aby klienci zadawali pytania dotyczące hoteli oferowanych w katalogu rezerwacji podróży.
Jeśli chcesz, aby model odpowiadał w określonym stylu lub formacie, możesz poinstruować model, aby to zrobił, dodając wytyczne w komunikacie systemowym. Gdy zauważysz, że zachowanie modelu nie jest spójne, można dodatkowo wymusić spójność zachowania, dostrajając model. Dzięki dostrajaniu można wytrenować podstawowy model językowy na zestawie danych przed zintegrowaniem go z aplikacją.
Możesz również użyć kombinacji strategii optymalizacji, takich jak RAG i dostosowany model, aby ulepszyć aplikację językową.