Eksplorowanie operacji ciągłych
Operacje ciągłe to jedna z ośmiu funkcji taksonomii DevOps.
Dowiedz się, dlaczego operacje ciągłe są niezbędne
Złożone systemy kończą się niepowodzeniem i mogą powodować kosztowne awarie i przerwy w działaniu. Przyjrzyjmy się kilku przykładom.
| Firmy | Wydarzenie |
|---|---|
Linie powietrza różnicowego |
W sierpniu 2016 r. Delta została zmuszona do anulowania 2300 lotów, gdy jeden kawałek nieprawidłowego sprzętu spowodował awarię zasilania w centrum operacyjnym w Atlancie. Zgłoszony koszt dla firmy wyniósł 150 milionów dolarów. |
Usługa kondycji FedEx i Uk National |
W maju 2017 r. oprogramowanie ransomware WannaCry spowodowało zakłócenia operacyjne w programie FedEx. Jedna spółka zależna FedEx odnotowała straty w wysokości 300 milionów dolarów. Brytyjski National Usługa kondycji był kolejną ofiarą ransomware, który zablokował dostęp do swoich komputerów, zablokował ważny sprzęt medyczny i zmusił niektóre szpitale do przekierowania karetek pogotowia do innych miejsc. |
Amazon S3 |
W lutym 2017 r. błąd operatora spowodował czterogodzinne zakłócenia w podstawowych usługach magazynu firmy Amazon, które miały wiele wpływu na znaczące właściwości internetowe, takie jak Alexa, IFTTT, Quora i Trello. |
| LinkedIn napotkał problem, który uniemożliwił wykonanie pracy dev przez dwa miesiące. | |
Equifax |
Equifax doznał naruszenia w 2017 roku, co spowodowało ujawnienie danych osobowych ponad 160 milionów konsumentów. Omówiliśmy to bardziej szczegółowo w temacie Ciągłe zabezpieczenia. |
Wpływ na działalność biznesową i koszt naruszenia
Koszty naruszenia często wykraczają daleko poza utratę sprzedaży i zaufania w firmie. Te koszty mogą obejmować:
- Odpowiedź i powiadomienie
- Istnieją koszty operacyjne i usługowe powiadamiania dotkniętych stron zgodnie z wymogami prawa. Te koszty często obejmują również dodatkowe koszty dla centrów obsługi telefonicznej, obsługi żądań ściągnięcia i usług monitorowania środków.
- Utrata produktywności pracowników i obrotów
- Radca generalny Yahoo zrezygnował, a dyrektor generalny nie otrzymał rocznej premii za rok 2016.
- Pozwy i rozliczenia
- Target zapłacił 18,5 miliona dolarów do 47 stanów USA.
- Grzywny i odpowiedzi regulacyjne
- Wraz z nową polityką ochrony danych obowiązującą w Unii Europejskiej od 2018 r. grzywna wynosi 4% rocznych dochodów lub 20 milionów euro, w zależności od tego, co jest większe.
- Koszty odzyskiwania marki
- Firma technologiczna górnicza Codan odnotowała spadek przychodów z 45 milionów dolarów do 9,2 miliona dolarów w ciągu roku.
- Inne zobowiązania
- Verizon zapłacił 350 milionów dolarów mniej za Yahoo po dwóch ogromnych hacków.
Mogą być również konieczne dodatkowe wymagania dotyczące zabezpieczeń i inspekcji.
Dostępność i odzyskiwanie w operacjach ciągłych
Według ankiety firmy Gartner liderzy biznesowi i IT oczekują, że do 2020 r. około 47% aplikacji produkcyjnych będzie działać w lokalizacjach chmury publicznej.
Gdy całe centra danych mogą zostać zniszczone jednym wierszem kodu, liderzy we&wy koncentrują się na dostępności i odzyskiwaniu środowisk produkcyjnych. Nowe wzorce wdrażania zmieniają sposób zapewniania dostępności aplikacji i infrastruktury oraz możliwości odzyskiwania.
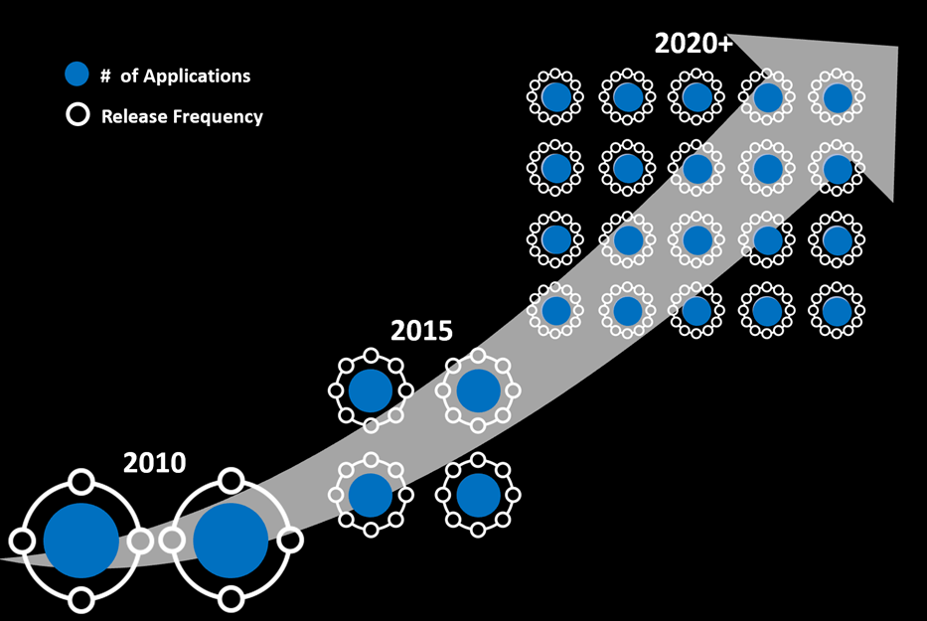
Rosnąca liczba aplikacji i wydań w środowisku produkcyjnym
Kluczowe wskaźniki wydajności wydajności dostarczania oprogramowania to:
- Czas realizacji zmiany
- Częstotliwość wdrażania
- Średni czas przywracania
- Zmiana współczynnika awarii
Zespoły, które pracują nad zwiększeniem szybkości, ale nie inwestują wystarczająco dużo w budowanie jakości procesu, będą doświadczać większych awarii i więcej czasu na przywrócenie usługi. Zespoły, które tworzą jakość w procesie, osiągną zarówno szybkość, jak i stabilność.
Liczba aplikacji internetowych i mobilnych oraz częstotliwość wydań aplikacji znacznie wzrosła. Kod stał się również coraz bardziej złożony.
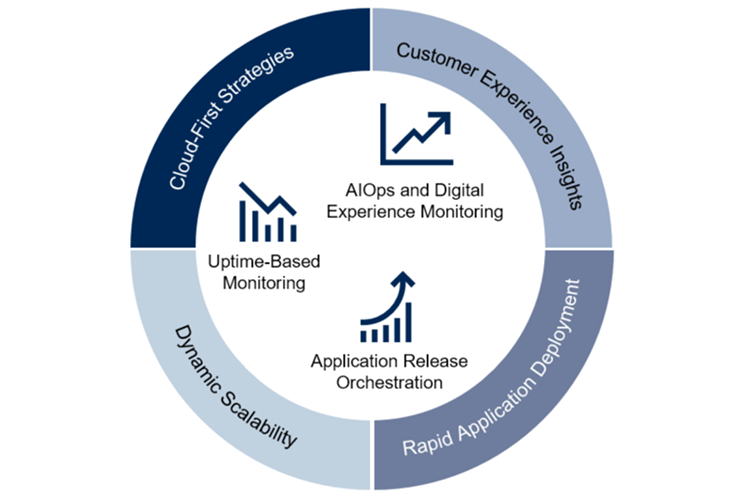
Uwaga
Duża część wartości metodyki DevOps w ogóle polega na znalezieniu właściwej równowagi między innowacjami (szybkością) i ciągłością działania (kontrola).
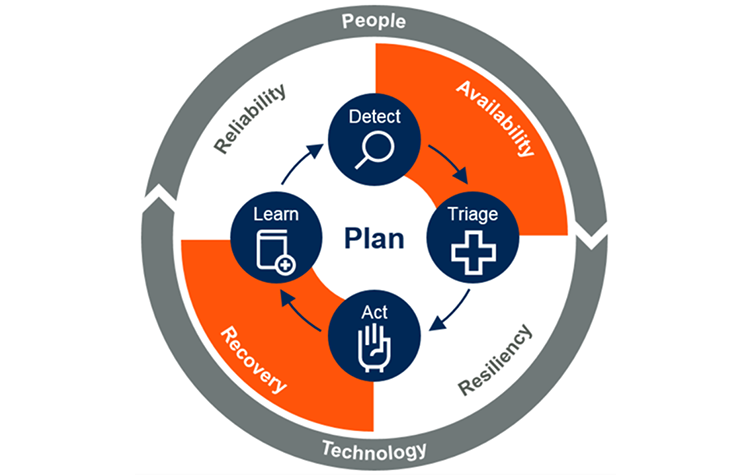
Co to są operacje ciągłe?
Ważne
Operacje ciągłe zmniejsza lub eliminuje potrzebę planowanych przestojów lub przerw, takich jak zaplanowana konserwacja. Ciągłe monitorowanie infrastruktury, aplikacji i usług powinno być powiązane z automatycznym korygowaniem, jeśli to możliwe. Użytkownik nigdy nie powinien wiedzieć, kiedy wystąpi aktualizacja lub wydanie przyrostowe.
Porównanie tradycyjnych i ciągłych praktyk operacyjnych
W tradycyjnym modelu przedsiębiorstwa it wymusza, co jest wydawane, i kontroluje wszystkie osoby ze sztywnymi procesami i procedurami.
Takie podejście powoduje niezgodność między zespołami deweloperów i ładem IT. Zespoły programistyczne są w większości zwinne, koncentrują się na szybkości i oczekują, że będą wydawane tak często, jak chcą. Dla nich ład IT wydaje się być wąskim gardłem, który nie jest zgodny z oczekiwanymi celami czasu do rynku dzisiejszych potrzeb biznesowych.
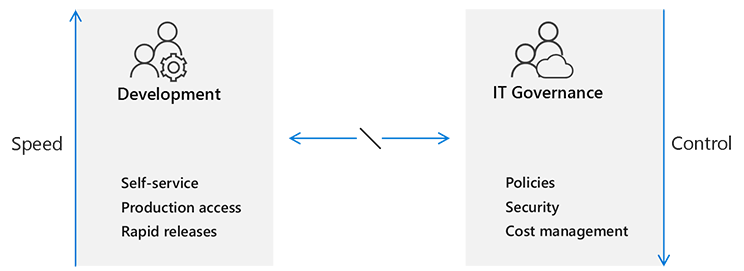
Ważne
W przypadku prawidłowego wdrożenia metodyka DevOps może dostarczać zarówno innowacje (szybkość) jak i ciągłość działania (kontrola).
W tradycyjnym cyklu życia programowania:
- Testowanie odbywa się tuż przed rozpoczęciem pracy.
- Monitorowanie jest często przekazywane.
- Zabezpieczenia są często konsultowane na etapach testowania.
- Podczas przekazywania należy przeprowadzić kontrole zabezpieczeń kodu i wszystkie mechanizmy kontroli zarządzania usługami.
- Zgodność nie jest często częścią przekazywania, ale coś, co "pojawia się" podczas działania usługi.
- Planowanie odporności/ciągłości odbywa się w ramach fazy projektowania, ale rzeczywiste testowanie powiązanych scenariuszy jest często wykonywane tylko podczas operacji lub fazy testowania, co może prowadzić do zmian konfiguracji, przepracowania i marnowania nakładu pracy.
- Współpraca między operacjami, zabezpieczeniami i zgodnością oraz deweloperami jest często wykonywana reaktywnie za pośrednictwem procesów zarządzania zdarzeniami i zarządzania problemami.
- Pozostawienie automatyzacji do ostatnich etapów często pozostawia niewiele zasobów, aby to zrobić.
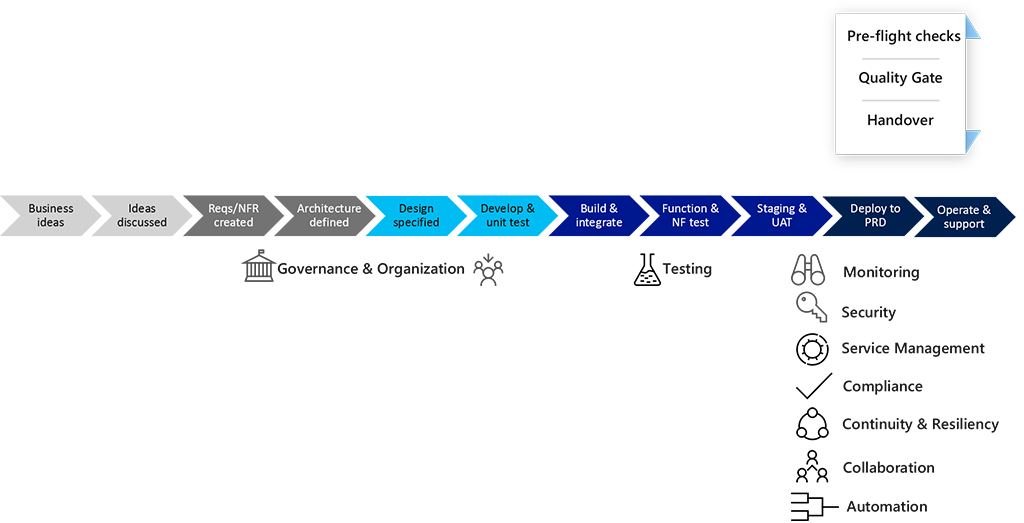
Nowe metody, technologie i sposoby pracy wymagają nowego podejścia do operacji ciągłych. Pojawiły się następujące osiem głównych praktyk związanych z ciągłymi operacjami i nadal ewoluują:
- Zabezpieczeń i zgodności zgodnie z projektem potwierdza, że niektóre standardy, przepisy, ale także wymagania biznesowe, takie jak możliwość śledzenia i inspekcja, muszą być brane pod uwagę w czasie projektowania w przypadku wysoce zautomatyzowanych środowisk w chmurze.
- Ciągłość i odporność wymaga ścisłej współpracy z organizacją, aby zapewnić, że potrzeby biznesowe są odzwierciedlane w projekcie i implementacji.
- Dane telemetryczne i monitorowanie mogą służyć do odnajdywania wzorców użycia klientów, potencjalnych nowych potrzeb i szczegółowych informacji o tym, gdzie użytkownicy napotykają błędy. Te narzędzia mogą również pomóc w zapewnieniu, że wartość jest dostarczana.
- Zarządzanie usługami to inna konwersacja w kulturze metodyki DevOps:
- Przesunięcie w kierunku oznacza, że jesteś jego właścicielem. Skompilujesz go, uruchomisz go, a gdy go naprawisz.
- Skoncentruj się na tym, co jest wymagane.
- Zwiększanie ładu.
- Ułatwianie przejrzystości.
- Kultura i współpraca są niezbędne w przypadku operacji ciągłych. Organizacje często wymagają zmiany sposobu, w jaki pracują, aby ułatwić transformację zespołom DevOps. Współpraca jest również niezbędna podczas projektowania pod kątem bezpieczeństwa i odporności.
- Operacje automatyzacji i sztucznej inteligencji/uczenia maszynowego są ważnymi aspektami tego, co sprawia, że metodyka DevOps (i chmura) różni się w porównaniu z tradycyjnymi zespołami operacyjnymi. Należy skupić się na całym systemie, który jest zautomatyzowany (automatyzacja systemowa), a nie tylko na jednym obszarze.
- Ciągłe wdrażanie używa nowoczesnych potoków wydania, aby umożliwić zespołom deweloperów szybkie i bezpieczne wdrażanie nowych funkcji, co pozwala na ciągły strumień wartości klienta i skraca czas rozwiązywania problemów.
- Testowanie shift-right używa rozwiązań, takich jak ciemne uruchamianie, flagi funkcji, monitorowanie i testowanie A/B. Zespoły mogą kontynuować testowanie, aby upewnić się, że aplikacja spełnia oczekiwania dotyczące zachowania, wydajności i dostępności podczas korzystania na żywo.
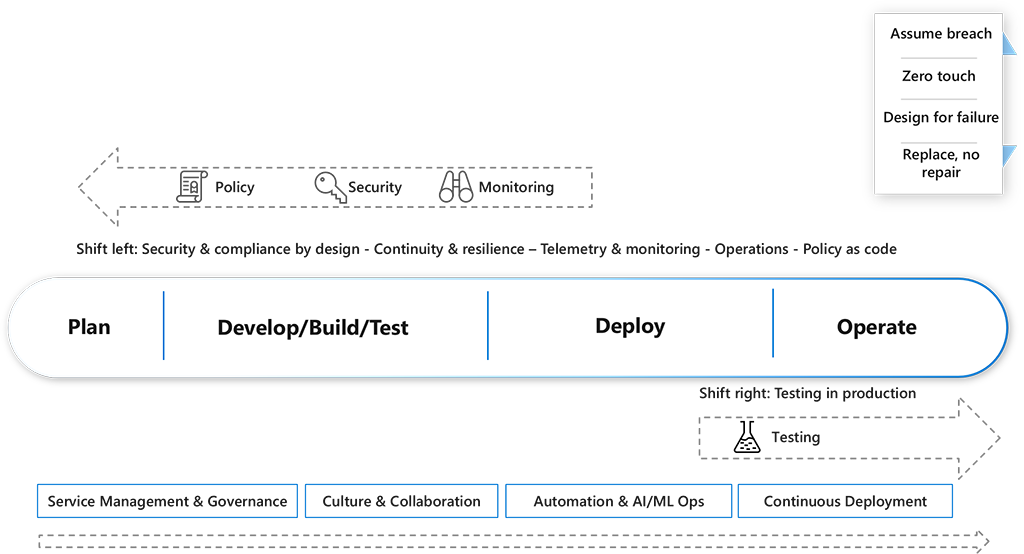
Aby przekształcić się w podejście DevOps, w kulturze musi wystąpić duża zmiana paradygmatu w celu zapewnienia wartości biznesowej przy użyciu nowoczesnego podejścia IT.
| Tradycyjne it | Nowoczesne it | |
|---|---|---|
| DNA | Pośrednictwa | Usuwanie pośrednictwa |
| Dostarczanie usług | Oparte na falach | Ciągła iteracja oparta na iteracji |
| Stabilność usługi | Projektowanie pod kątem powodzenia (HA/Redundant) | Projektowanie pod kątem awarii (odporne) |
| Poziomy delegowania | Silosy IT | Kompleksowe usługi |
| Procesy | W dokumentach zoptymalizowane, przeprojektowane | Samoobsługa, wiedza, niskie tarcie, zautomatyzowane |
| Automatyzacja | Izolowane, inicjowane ręcznie | Systemowe, wyzwalane, automatyczne |
| Monitorowanie | Element, skoncentrowany na błędach | Usługa, kompleksowa funkcja ukierunkowana |
| Pomoc techniczna | Service Desk /Contact Center | Obsługa klienta / Samoobsługa |
| Cykl życia | N-1 lub starszy | N, N+1 |
| Konfiguracja/Zarządzanie zasobami | Odnaleziona/Ręczna konfiguracja | Przepisywane, deklaratywne, zautomatyzowane |
Te zmiany powodują uproszczone i zautomatyzowane procesy, dostosowane zachęty do wyników, zmniejszone ryzyko i podejście skoncentrowane na klientach.