Eksplorowanie przetwarzania danych analitycznych
Przetwarzanie danych analitycznych zwykle używa systemów tylko do odczytu (lub głównie do odczytu), które przechowują ogromne ilości danych historycznych lub metryk biznesowych. Analiza może opierać się na migawce danych z określonego punktu w czasie lub na serii migawek.
Szczegółowe informacje dotyczące systemu przetwarzania analitycznego mogą się różnić między rozwiązaniami, ale typowa architektura analizy w skali przedsiębiorstwa wygląda następująco:
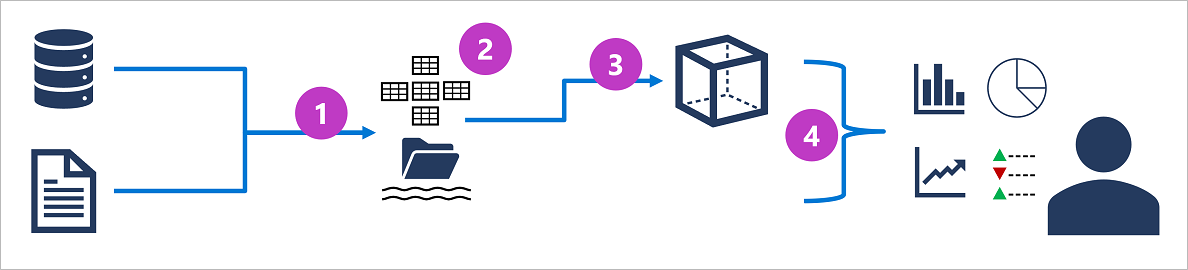
- Dane operacyjne są wyodrębniane, przekształcane i ładowane (ETL) do magazynu data lake na potrzeby analizy.
- Dane są ładowane do schematu tabel — zazwyczaj w usłudze Data Lakehouse opartej na platformie Spark z tabelarycznymi abstrakcjami plików w usłudze Data Lake lub magazynem danych z w pełni relacyjnym aparatem SQL.
- Dane w magazynie danych mogą być agregowane i ładowane do modelu przetwarzania analitycznego online (OLAP) lub modułu. Zagregowane wartości liczbowe (miary) z tabel faktów są obliczane dla przecięcia wymiarów z tabel wymiarów . Na przykład przychody ze sprzedaży mogą być sumowane według daty, klienta i produktu.
- Dane w usłudze Data Lake, magazynie danych i modelu analitycznym mogą być odpytywane w celu tworzenia raportów, wizualizacji i pulpitów nawigacyjnych.
Magazyny data lake są powszechne w scenariuszach przetwarzania analitycznego danych na dużą skalę, w których należy zbierać i analizować dużą ilość danych opartych na plikach.
Magazyny danych to ustalony sposób przechowywania danych w schemacie relacyjnym zoptymalizowanym pod kątem operacji odczytu — przede wszystkim zapytań obsługujących raportowanie i wizualizację danych. Usługa Data Lakehouses to nowsza innowacja łącząca elastyczny i skalowalny magazyn typu data lake z semantykami zapytań relacyjnych magazynu danych. Schemat tabeli może wymagać denormalizacji danych w źródle danych OLTP (wprowadzenie niektórych duplikacji w celu szybszego wykonywania zapytań).
Model OLAP to zagregowany typ magazynu danych zoptymalizowany pod kątem obciążeń analitycznych. Agregacje danych znajdują się między wymiarami na różnych poziomach, umożliwiając przechodzenie do szczegółów/w dół w celu wyświetlania agregacji na wielu poziomach hierarchicznych, na przykład w celu znalezienia całkowitej sprzedaży według regionu, miasta lub pojedynczego adresu. Ponieważ dane OLAP są wstępnie zagregowane, zapytania zwracające zawarte w nim podsumowania mogą być uruchamiane szybko.
Różne typy użytkowników mogą wykonywać prace analityczne danych na różnych etapach ogólnej architektury. Na przykład:
- Analitycy danych mogą pracować bezpośrednio z plikami danych w usłudze Data Lake, aby eksplorować i modelować dane.
- analitycy danych mogą wysyłać zapytania do tabel bezpośrednio w magazynie danych w celu tworzenia złożonych raportów i wizualizacji.
- Użytkownicy biznesowi mogą korzystać ze wstępnie zagregowanych danych w modelu analitycznym w postaci raportów lub pulpitów nawigacyjnych.