Eksplorowanie danych za pomocą bibliotek NumPy i Pandas
Analitycy danych mogą używać różnych narzędzi i technik do eksplorowania, wizualizowania i manipulowania danymi. Jednym z najpopularniejszych sposobów, w jaki analitycy danych pracują z danymi, jest użycie języka Python i niektórych określonych pakietów do przetwarzania danych.
Co to jest biblioteka NumPy?
NumPy to biblioteka języka Python, która zapewnia funkcje porównywalne z narzędziami matematycznymi, takimi jak MATLAB i R. Chociaż biblioteka NumPy znacznie upraszcza środowisko użytkownika, oferuje również kompleksowe funkcje matematyczne.
Co to jest biblioteka Pandas?
Pandas to niezwykle popularna biblioteka języka Python do analizy danych i manipulowania nimi. Biblioteka Pandas jest jak aplikacja arkusza kalkulacyjnego dla języka Python, zapewniając łatwą w użyciu funkcję tabel danych.
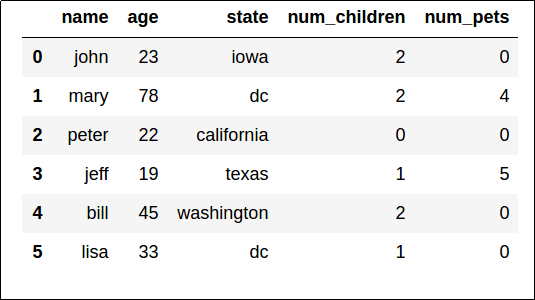
Eksplorowanie danych w notesie Jupyter
Notesy Jupyter to popularny sposób uruchamiania podstawowych skryptów przy użyciu przeglądarki internetowej. Zazwyczaj te notesy są jedną stroną internetową podzieloną na sekcje tekstowe i sekcje kodu, które są wykonywane na serwerze, a nie na komputerze lokalnym. Uruchamiając kod w notesach Jupyter na serwerze, możesz szybko rozpocząć pracę bez konieczności instalowania języka Python lub innych narzędzi na komputerze lokalnym.
Testowanie hipotez
Eksploracja i analiza danych jest zazwyczaj procesem iteracyjnym , w którym analityk danych pobiera próbkę danych i wykonuje następujące rodzaje zadań do analizowania i testowania hipotez:
- Czyszczenie danych w celu obsługi błędów, brakujących wartości i innych problemów.
- Zastosuj techniki statystyczne, aby lepiej zrozumieć dane i sposób, w jaki próbka może być oczekiwana do reprezentowania rzeczywistej populacji danych, co pozwala na losowe zmiany.
- Wizualizuj dane w celu określenia relacji między zmiennymi, a w przypadku projektu uczenia maszynowego zidentyfikuj funkcje , które są potencjalnie predykcyjne etykiety.
- Zrewiduj hipotezę i powtórz ten proces.