Eksplorowanie potoków pozyskiwania danych
Teraz, gdy rozumiesz nieco architekturę rozwiązania do magazynowania danych na dużą skalę i niektóre technologie przetwarzania rozproszonego, które mogą służyć do obsługi dużych ilości danych, nadszedł czas, aby dowiedzieć się, jak dane są pozyskiwane do magazynu danych analitycznych z co najmniej jednego źródła.
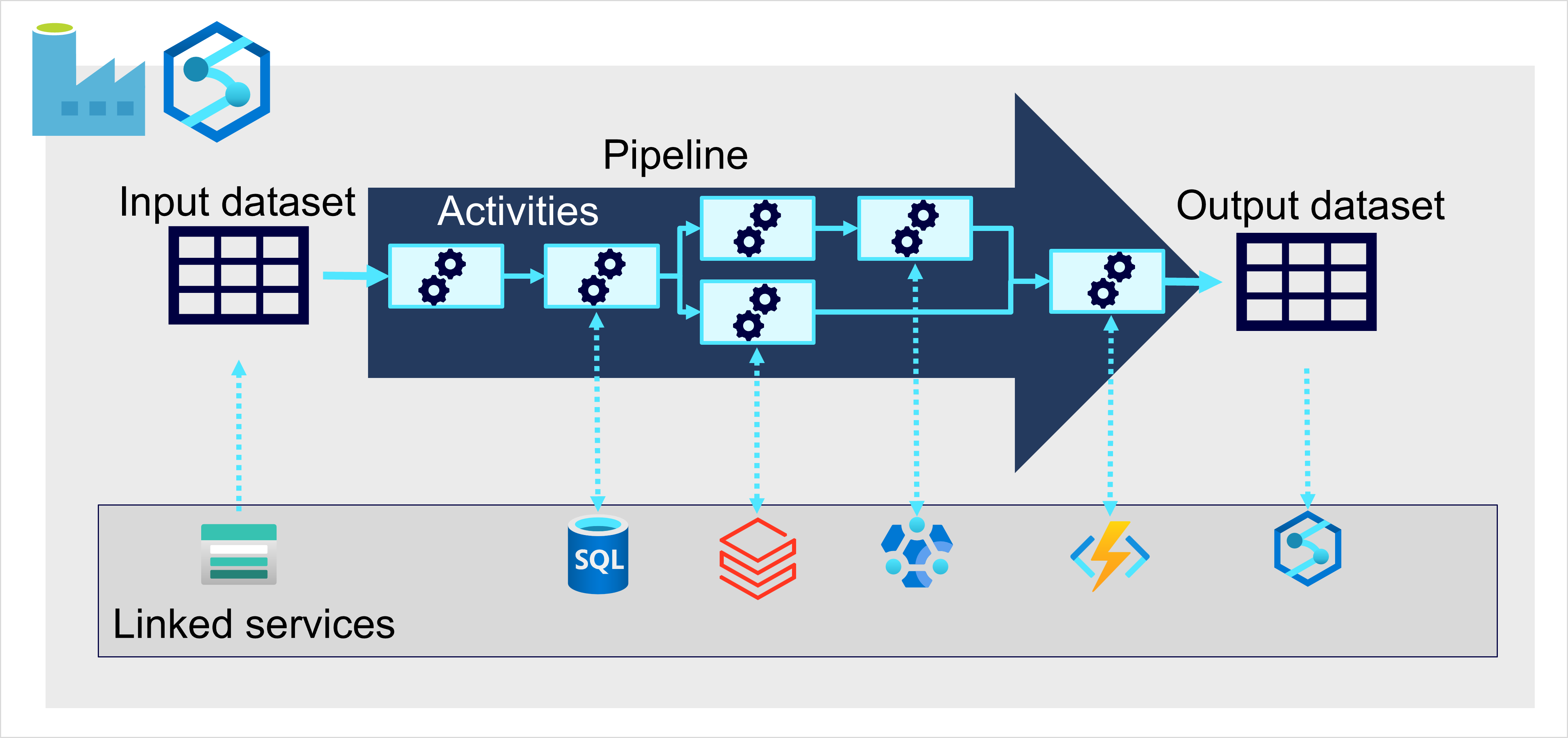
Na platformie Azure pozyskiwanie danych na dużą skalę najlepiej zaimplementować przez tworzenie potoków , które organizuje procesy ETL. Potoki można tworzyć i uruchamiać przy użyciu usługi Azure Data Factory lub użyć funkcji potoku w usłudze Microsoft Fabric , jeśli chcesz zarządzać wszystkimi składnikami rozwiązania do magazynowania danych w ujednoliconym obszarze roboczym.
W obu przypadkach potoki składają się z co najmniej jednego działania , które działają na danych. Wejściowy zestaw danych udostępnia dane źródłowe, a działania można zdefiniować jako przepływ danych, który przyrostowo manipuluje danymi do momentu utworzenia wyjściowego zestawu danych. Potoki używają połączonych usług do ładowania i przetwarzania danych — umożliwiają korzystanie z odpowiedniej technologii dla każdego kroku przepływu pracy. Na przykład możesz użyć połączonej usługi Azure Blob Store do pozyskiwania wejściowego zestawu danych, a następnie użyć usług, takich jak usługa Azure SQL Database, aby uruchomić procedurę składowaną, która wyszukuje powiązane wartości danych, przed uruchomieniem zadania przetwarzania danych w usłudze Azure Databricks lub zastosuj logikę niestandardową przy użyciu funkcji platformy Azure. Na koniec możesz zapisać wyjściowy zestaw danych w połączonej usłudze, takiej jak Microsoft Fabric. Potoki mogą również obejmować niektóre wbudowane działania, które nie wymagają połączonej usługi.