Tworzenie osadzania za pomocą rozszerzenia azure AI
Aby uruchomić wyszukiwanie semantyczne, należy porównać osadzanie zapytania z osadzeniem wyszukiwanych elementów. azure_ai Rozszerzenie usługi Azure Database for PostgreSQL — serwer elastyczny integruje się z usługą Azure OpenAI w celu wygenerowania wektorów osadzania.
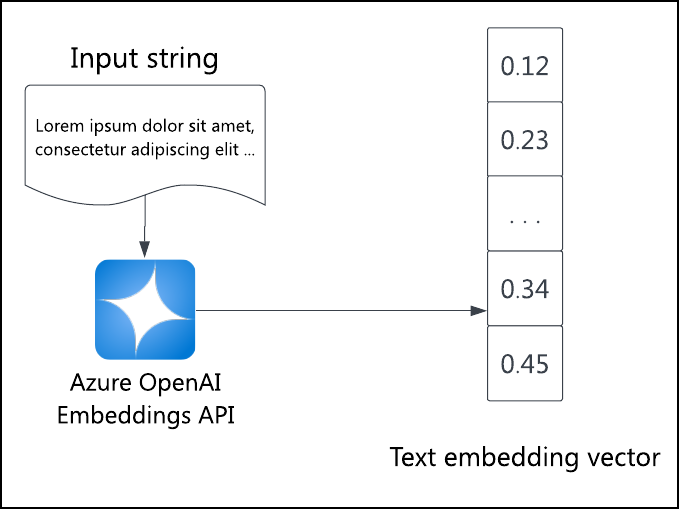
Wprowadzenie do azure_ai usługi Azure OpenAI
Elastyczne rozszerzenie usługi Azure Database for PostgreSQL dla usługi Azure AI udostępnia funkcje zdefiniowane przez użytkownika w celu integracji z usługami azure AI, w tym Azure OpenAI i Azure Cognitive Services.
Interfejs API osadzania w usłudze Azure OpenAI generuje wektor osadzania tekstu wejściowego. Użyj tego interfejsu API, aby ustawić osadzanie dla wszystkich wyszukiwanych elementów. azure_ai Schemat rozszerzenia azure_openai ułatwia wywoływanie interfejsu API z bazy danych SQL w celu wygenerowania osadzonych elementów, niezależnie od tego, czy należy zainicjować osadzanie elementów, czy utworzyć zapytanie osadzone na bieżąco. Te osadzania mogą następnie służyć do wykonywania wyszukiwania podobieństwa wektorowego lub innymi słowy wyszukiwania semantycznego.
azure_ai Używanie rozszerzenia z usługą Azure OpenAI
Aby wywołać interfejs API osadzania usługi Azure OpenAI z bazy danych PostgreSQL, musisz włączyć i skonfigurować azure_ai rozszerzenie, udzielić dostępu do usługi Azure OpenAI i wdrożyć model usługi Azure OpenAI. Aby uzyskać więcej informacji, zobacz dokumentację usługi Azure OpenAI w usłudze Azure Database for PostgreSQL — serwer elastyczny.
Gdy środowisko będzie gotowe i rozszerzenie ma wartość allow-listed, uruchom następujące polecenie SQL:
/* Enable the extension. */
CREATE EXTENSION azure_ai;
Należy również skonfigurować punkt końcowy i klucz dostępu zasobu usługi OpenAI:
SELECT azure_ai.set_setting('azure_openai.endpoint', '{your-endpoint-url}');
SELECT azure_ai.set_setting('azure_openai.subscription_key', '{your-api-key}}');
Po azure_ai skonfigurowaniu interfejsu Azure OpenAI pobieranie i przechowywanie osadzania jest prostą kwestią wywoływania funkcji w zapytaniu SQL. Przy założeniu, że tabela listings z kolumną description i kolumną listing_vector , możesz wygenerować i zapisać osadzanie dla wszystkich list przy użyciu następującego zapytania. Zastąp {your-deployment-name} ciąg nazwą wdrożenia z usługi Azure OpenAI Studio dla utworzonego modelu.
UPDATE listings
SET listing_vector = azure_openai.create_embeddings('{your-deployment-name}', description, max_attempts => 5, retry_delay_ms => 500)
WHERE listing_vector IS NULL;
Kolumna listing_vector wektorowa musi mieć taką samą liczbę wymiarów, jakie generuje model językowy.
Aby wyświetlić osadzanie dokumentu, uruchom następujące zapytanie:
SELECT listing_vector FROM listings LIMIT 1;
Wynik jest wektorem liczb zmiennoprzecinkowych. Najpierw możesz uruchomić \x polecenie , aby dane wyjściowe mogły być bardziej czytelne.
Dynamiczne generowanie osadzania zapytania
Po osadzeniu dokumentów, które chcesz wyszukać, możesz uruchomić semantyczne zapytanie wyszukiwania. W tym celu należy również wygenerować osadzanie dla tekstu zapytania.
Schemat azure_openai azure_ai rozszerzenia umożliwia generowanie osadzeń w programie SQL. Aby na przykład znaleźć trzy pierwsze listy, których tekst jest najbardziej semantycznie podobny do zapytania "Znajdź mnie miejsca w okolicy z możliwością przejścia", uruchom następujący kod SQL:
SELECT id, description FROM listings
ORDER BY listing_vector <=> azure_openai.create_embeddings('{your-deployment-name}', 'Find me places in a walkable neighborhood.')::vector
LIMIT 3;
Operator <=> oblicza odległość cosinusu między dwoma wektorami — metryką podobieństwa semantycznego. Im bliżej wektorów, tym bardziej semantycznie podobne; tym bardziej semantycznie różnią się wektory.
Operator ::vector konwertuje wygenerowane osadzanie na tablice wektorowe PostgreSQL.
Zapytanie zwraca trzy najważniejsze identyfikatory i opisy listy, sklasyfikowane z mniejszej do bardziej innej (więcej do mniej podobnych).