Przechowywanie wektorów w usłudze Azure Database for PostgreSQL
Pamiętaj, że do uruchamiania wyszukiwania semantycznego wymagane jest osadzanie wektorów przechowywanych w bazie danych wektorów. Serwer elastyczny usługi Azure Database for PostgreSQL może służyć jako wektorowa baza danych z vector rozszerzeniem .
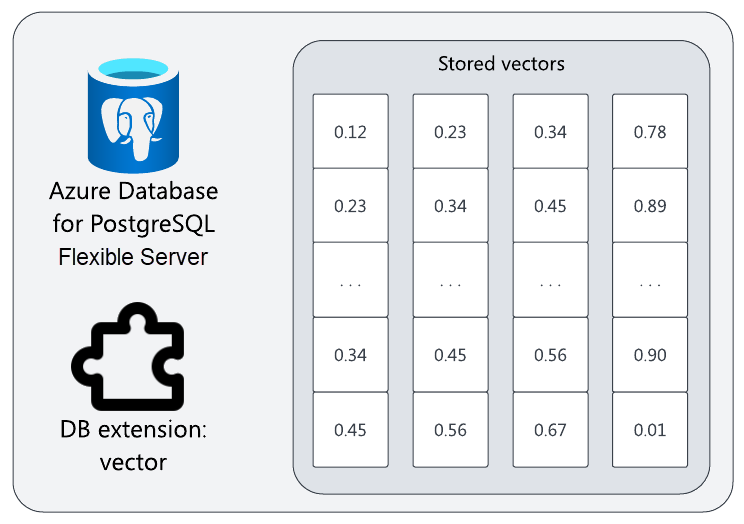
Wprowadzenie do vector
Rozszerzenie typu open source vector zapewnia magazyn wektorowy, zapytania dotyczące podobieństwa i inne operacje wektorów dla bazy danych PostgreSQL. Po włączeniu można tworzyć vector kolumny do przechowywania osadzania (lub innych wektorów) obok innych kolumn.
/* Enable the extension. */
CREATE EXTENSION vector;
/* Create a table containing a 3d vector. */
CREATE TABLE documents (id bigserial PRIMARY KEY, embedding vector(3));
/* Create some sample data. */
INSERT INTO documents (embedding) VALUES
('[1,2,3]'),
('[2,1,3]'),
('[4,5,6]');
Możesz dodać kolumny wektorowe do istniejących tabel:
ALTER TABLE documents ADD COLUMN embedding vector(3);
Po utworzeniu pewnych danych wektorowych można je zobaczyć obok normalnych danych tabeli:
# SELECT * FROM documents;
id | embedding
----+-----------
1 | [1,2,3]
2 | [2,1,3]
3 | [4,5,6]
Rozszerzenie vector obsługuje kilka języków, takich jak .NET, Python, Java i wiele innych. Aby uzyskać więcej informacji, zobacz ich repozytoria GitHub.
Aby wstawić dokument z wektorem [1, 2, 3] przy użyciu narzędzia Npgsql w języku C#, uruchom kod podobny do następującego:
var sql = "INSERT INTO documents (embedding) VALUES ($1)";
await using (var cmd = new NpgsqlCommand(sql, conn))
{
var embedding = new Vector(new float[] { 1, 2, 3 });
cmd.Parameters.AddWithValue(embedding);
await cmd.ExecuteNonQueryAsync();
}
Wstawianie i aktualizowanie wektorów
Gdy tabela zawiera kolumnę wektorową, wiersze można dodawać z wartościami wektorów, jak wspomniano wcześniej.
INSERT INTO documents (embedding) VALUES ('[1,2,3]');
Można również ładować wektory zbiorcze przy użyciu instrukcji COPY (zobacz kompletny przykład w języku Python):
COPY documents (embedding) FROM STDIN WITH (FORMAT BINARY);
Kolumny wektorowe można aktualizować tak jak kolumny standardowe:
UPDATE documents SET embedding = '[1,1,1]' where id = 1;
Przeprowadzanie wyszukiwania odległości cosinus
Rozszerzenie vector udostępnia v1 <=> v2 operatorowi obliczenie odległości cosinusu między wektorami v1 i v2. Wynik jest liczbą z zakresu od 0 do 2, gdzie 0 oznacza "semantycznie identyczne" (bez odległości) i dwa oznacza "semantycznie przeciwne" (maksymalna odległość).
Można zobaczyć terminy odległość cosinus i podobieństwo. Pamiętaj, że podobieństwo cosinus jest z zakresu od -1 do 1, gdzie -1 oznacza "semantycznie przeciwne" i 1 oznacza "semantycznie identyczne". Należy pamiętać, że similarity = 1 - distance.
Ten błąd polega na tym, że zapytanie uporządkowane według odległości rosnącej zwraca najpierw najmniej odległe (najbardziej podobne) wyniki, podczas gdy zapytanie uporządkowane według podobieństwa malejąco zwraca najbardziej podobne (najmniej odległe) wyniki najpierw.
Poniżej przedstawiono niektóre wektory i ich odległości i podobieństwa, aby zilustrować koncepcje. Możesz samodzielnie obliczyć to obliczenie, uruchamiając coś takiego jak:
SELECT '[1,1]' <=> '[-1,-1]';
Rozważ następujące wektory:
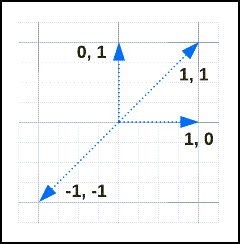
Ich podobieństwa i odległości są następujące:
| v1 | Wersja 2 | odległość | podobieństwo |
|---|---|---|---|
[1, 1] |
[1, 1] |
0 | 1 |
[1, 1] |
[-1, -1] |
2 | -1 |
[1, 0] |
[0, 1] |
1 | 0 |
Aby uzyskać dokumenty w kolejności zbliżenia do wektora [2, 3, 4], uruchom następujące zapytanie:
SELECT
*,
embedding <=> '[2,3,4]' AS distance
FROM documents
ORDER BY distance;
Wyniki:
id | embedding | distance
----+-----------+-----------------------
3 | [4,5,6] | 0.0053884541273605535
1 | [1,2,3] | 0.007416666029069763
2 | [2,1,3] | 0.05704583272761632
Dokument z elementem id=3 jest najbardziej podobny do zapytania, a następnie wkrótce przez id=1element , a na koniec przez id=2.
Dodaj klauzulę LIMIT N do SELECT zapytania, aby zwrócić najbardziej N podobne dokumenty. Aby na przykład uzyskać najbardziej podobny dokument:
SELECT
*,
embedding <=> '[2,3,4]' AS distance
FROM documents
ORDER BY distance
LIMIT 1;
Wyniki:
id | embedding | distance
----+-----------+-----------------------
3 | [4,5,6] | 0.0053884541273605535