Zbieranie, wykonywanie zapytań i wizualizowanie stanów kondycji
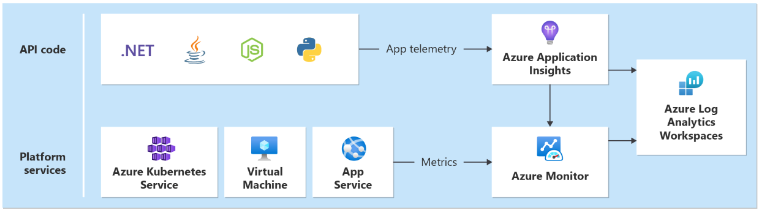
Aby dokładnie reprezentować model kondycji, należy zebrać różne zestawy danych z systemu. Zestawy danych obejmują dzienniki i metryki wydajności ze składników aplikacji i podstawowych zasobów platformy Azure. Ważne jest, aby skorelować dane między zestawami danych, aby utworzyć warstwową reprezentację kondycji systemu.
Instrumentacja kodu i infrastruktury
Wymagany jest ujednolicony ujście danych w celu zapewnienia, że wszystkie dane operacyjne są przechowywane i dostępne w jednej lokalizacji, w której są zbierane wszystkie dane telemetryczne. Na przykład gdy pracownik utworzy komentarz w przeglądarce internetowej, możesz śledzić tę operację i zobaczyć, że żądanie przechodzi przez interfejs API wykazu do usługi Azure Event Hubs. Stamtąd procesor w tle odebrał komentarz i zapisze go w usłudze Azure Cosmos DB.
Usługa Azure Monitor Log Analytics służy jako podstawowy ujednolicony ujście danych na platformie Azure do przechowywania i analizowania danych operacyjnych:
Usługa Application Insights jest zalecanym narzędziem application monitor wydajności ing (APM) we wszystkich składnikach aplikacji w celu zbierania dzienników aplikacji, metryk i śladów. Usługa Application Insights jest wdrażana w konfiguracji opartej na obszarze roboczym w każdym regionie.
W przykładowej aplikacji usługa Azure Functions jest używana na platformie Microsoft .NET 6 na potrzeby usług zaplecza na potrzeby integracji natywnej. Ponieważ aplikacje zaplecza już istnieją, firma Contoso Shoes tworzy tylko nowy zasób usługi Application Insights na platformie Azure i konfiguruje
APPLICATIONINSIGHTS_CONNECTION_STRINGustawienie dla obu aplikacji funkcji. Środowisko uruchomieniowe usługi Azure Functions automatycznie rejestruje dostawcę rejestrowania usługi Application Insights, więc dane telemetryczne są wyświetlane na platformie Azure bez dodatkowych wysiłków. Aby uzyskać bardziej dostosowane rejestrowanie, możesz użyć interfejsuILogger.Scentralizowany zestaw danych to antywzorzec dla obciążeń o znaczeniu krytycznym. Każdy region musi mieć dedykowany obszar roboczy usługi Log Analytics i wystąpienie usługi Application Insights. W przypadku zasobów globalnych zalecane są oddzielne wystąpienia. Aby zobaczyć wzorzec architektury podstawowej, zobacz Wzorzec architektury dla obciążeń o znaczeniu krytycznym na platformie Azure.
Każda warstwa powinna wysyłać dane do tego samego obszaru roboczego usługi Log Analytics, aby ułatwić analizę i obliczenia kondycji.
Zapytania monitorowania kondycji
Usługi Log Analytics, Application Insights i Azure Data Explorer używają język zapytań Kusto (KQL) dla zapytań. Język KQL umożliwia tworzenie zapytań i używanie funkcji do pobierania metryk i obliczania wyników kondycji.
W przypadku poszczególnych usług, które obliczają stan kondycji, zobacz następujące przykładowe zapytania.
Interfejs API wykazu
W poniższym przykładzie pokazano zapytanie interfejsu API wykazu:
let _maxAge = 2d; // Include data only from the last two days
let _timespanStart = ago(_maxAge); // Start time for the time span
let _timespanEnd = now(-2m); // Account for ingestion lag by stripping the last 2m
// For time frame, compare the averages to the following threshold values
let Thresholds=datatable(MetricName: string, YellowThreshold: double, RedThreshold: double) [
"failureCount", 10, 50, // Failed requests, anything non-200, allow a few more than 0 for user-caused errors like 404s
"avgProcessingTime", 150, 500 // Average duration of the request, in ms
];
// Calculate average processing time for each request
let avgProcessingTime = AppRequests
| where AppRoleName startswith "CatalogService"
| where OperationName != "GET /health/liveness" // Liveness requests don't do any processing, including them would skew the results
| make-series Value = avg(DurationMs) default=0 on TimeGenerated from _timespanStart to _timespanEnd step 1m
| mv-expand TimeGenerated, Value
| extend TimeGenerated = todatetime(TimeGenerated), Value=toreal(Value), MetricName= 'avgProcessingTime';
// Calculate failed requests
let failureCount = AppRequests
| where AppRoleName startswith "CatalogService" // Liveness requests don't do any processing, including them would skew the results
| where OperationName != "GET /health/liveness"
| make-series Value=countif(Success != true) default=0 on TimeGenerated from _timespanStart to _timespanEnd step 1m
| mv-expand TimeGenerated, Value
| extend TimeGenerated = todatetime(TimeGenerated), Value=toreal(Value), MetricName= 'failureCount';
// Union all together and join with the thresholds
avgProcessingTime
| union failureCount
| lookup kind = inner Thresholds on MetricName
| extend IsYellow = iff(todouble(Value) > YellowThreshold and todouble(Value) < RedThreshold, 1, 0)
| extend IsRed = iff(todouble(Value) > RedThreshold, 1, 0)
| project-reorder TimeGenerated, MetricName, Value, IsYellow, IsRed, YellowThreshold, RedThreshold
| extend ComponentName="CatalogService"
Azure Key Vault
W poniższym przykładzie pokazano zapytanie usługi Azure Key Vault:
let _maxAge = 2d; // Include data only from the last two days
let _timespanStart = ago(_maxAge); // Start time for the time span
let _timespanEnd = now(-2m); // Account for ingestion lag by stripping the last 2m
// For time frame, compare the averages to the following threshold values
let Thresholds = datatable(MetricName: string, YellowThreshold: double, RedThreshold: double) [
"failureCount", 3, 10 // Failure count on key vault requests
];
let failureStats = AzureDiagnostics
| where TimeGenerated > _timespanStart
| where ResourceProvider == "MICROSOFT.KEYVAULT"
// Ignore authentication operations that have a 401. This is normal when using Key Vault SDK. First an unauthenticated request is made, then the response is used for authentication
| where Category=="AuditEvent" and not (OperationName == "Authentication" and httpStatusCode_d == 401)
| where OperationName in ('SecretGet','SecretList','VaultGet') or '*' in ('SecretGet','SecretList','VaultGet')
// Exclude Not Found responses because these happen regularly during 'Terraform plan' operations, when Terraform checks for the existence of secrets
| where ResultSignature != "Not Found"
// Create ResultStatus with all the 'success' results bucketed as 'Success'
// Certain operations like StorageAccountAutoSyncKey have no ResultSignature; for now, also set to 'Success'
| extend ResultStatus = case ( ResultSignature == "", "Success",
ResultSignature == "OK", "Success",
ResultSignature == "Accepted", "Success",
ResultSignature);
failureStats
| make-series Value=countif(ResultStatus != "Success") default=0 on TimeGenerated from _timespanStart to _timespanEnd step 1m
| mv-expand TimeGenerated, Value
| extend TimeGenerated = todatetime(TimeGenerated), Value=toreal(Value), MetricName="failureCount", ComponentName="Keyvault"
| lookup kind = inner Thresholds on MetricName
| extend IsYellow = iff(todouble(Value) > YellowThreshold and todouble(Value) < RedThreshold, 1, 0)
| extend IsRed = iff(todouble(Value) > RedThreshold, 1, 0)
Wynik Kondycja usługi katalogu
W końcu można powiązać różne zapytania o stan kondycji, aby obliczyć wynik kondycji składnika. Następujące przykładowe zapytanie pokazuje, jak obliczyć ocenę Kondycja usługi katalogu:
CatalogServiceHealthStatus()
| union AksClusterHealthStatus()
| union KeyvaultHealthStatus()
| union EventHubHealthStatus()
| where TimeGenerated < ago(2m)
| summarize YellowScore = max(IsYellow), RedScore = max(IsRed) by bin(TimeGenerated, 2m)
| extend HealthScore = 1 - (YellowScore * 0.25) - (RedScore * 0.5)
| extend ComponentName = "CatalogService", Dependencies="AKSCluster,Keyvault,EventHub" // These values are added to build the dependency visualization
| order by TimeGenerated desc
Napiwek
Zobacz więcej przykładów zapytań w repozytorium GitHub usługi Azure Mission-Critical Online .
Konfigurowanie alertów opartych na zapytaniach
Alerty zwracają natychmiastową uwagę na problemy odzwierciedlające lub wpływające na stan kondycji. Za każdym razem, gdy wystąpi zmiana stanu kondycji na stan obniżonej wydajności (żółty) lub stan złej kondycji (czerwony), powiadomienia powinny być wysyłane do zespołu odpowiedzialnych. Ustaw alerty w węźle głównym modelu kondycji, aby natychmiast znać wszelkie zmiany na poziomie biznesowym w stanie kondycji rozwiązania. Następnie możesz przyjrzeć się wizualizacjom modelu kondycji, aby uzyskać więcej informacji i rozwiązać problemy.
W tym przykładzie użyto alertów usługi Azure Monitor do kierowania automatycznymi akcjami w odpowiedzi na zmiany stanu kondycji aplikacji.
Używanie pulpitów nawigacyjnych do wizualizacji
Ważne jest, aby zwizualizować model kondycji, aby szybko zrozumieć wpływ awarii składnika na cały system. Ostatecznym celem modelu zdrowia jest ułatwienie szybkiej diagnozy poprzez zapewnienie świadomego wglądu w odchylenia od stanu stałego.
Typowym sposobem wizualizacji informacji o kondycji systemu jest połączenie widoku modelu kondycji warstwowej z funkcjami przechodzenia do szczegółów telemetrii na pulpicie nawigacyjnym.
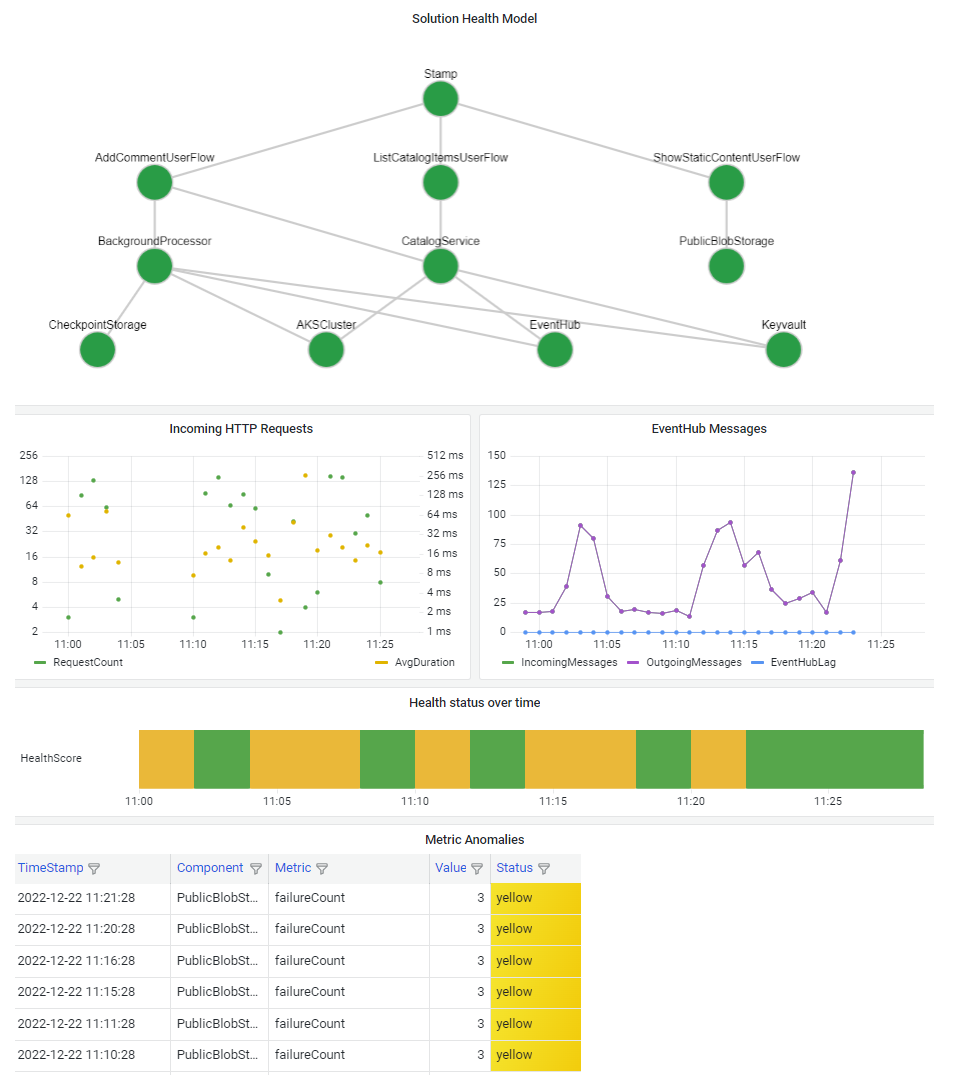
Technologia pulpitu nawigacyjnego powinna być w stanie reprezentować model kondycji. Popularne opcje obejmują pulpity nawigacyjne platformy Azure, usługę Power BI i aplikację Azure Managed Grafana.