Eksplorowanie rozwiązania IaaS o wysokiej dostępności i odzyskiwaniu po awarii
Istnieje wiele różnych kombinacji funkcji, które można wdrożyć na platformie Azure dla IaaS. Ta sekcja zawiera pięć typowych przykładów architektur wysokiej dostępności i odzyskiwania po awarii (HADR) programu SQL Server na platformie Azure.
Przykład wysokiej dostępności w jednym regionie 1 — zawsze włączone grupy dostępności
Jeśli potrzebujesz tylko wysokiej dostępności, a nie odzyskiwania po awarii, skonfigurowanie grupy dostępności (grupy dostępności) jest jedną z najbardziej wszechobecnych metod niezależnie od tego, gdzie używasz programu SQL Server. Na poniższej ilustracji przedstawiono przykładową możliwą grupę dostępności w jednym regionie.
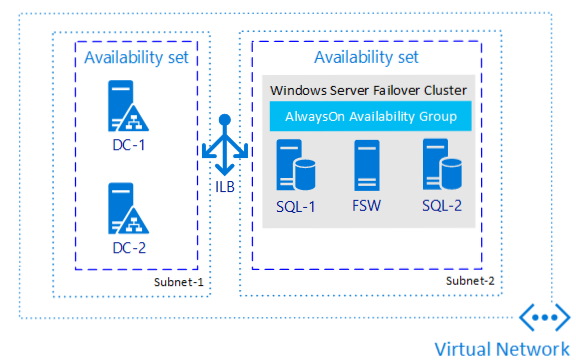
Dlaczego warto rozważyć tę architekturę?
Ta architektura chroni dane przez posiadanie więcej niż jednej kopii na różnych maszynach wirtualnych.
Ta architektura umożliwia spełnienie celu czasu odzyskiwania (RTO) i celu punktu odzyskiwania (RPO) z minimalną do braku utraty danych w przypadku prawidłowego zaimplementowania.
Ta architektura zapewnia łatwą, ustandaryzowaną metodę dostępu aplikacji zarówno do replik podstawowych, jak i pomocniczych (jeśli będą używane repliki tylko do odczytu).
Ta architektura zapewnia zwiększoną dostępność podczas scenariuszy stosowania poprawek.
Ta architektura nie wymaga magazynu udostępnionego, dlatego w przypadku korzystania z wystąpienia klastra trybu failover jest mniej komplikacji.
Przykład wysokiej dostępności pojedynczego regionu 2 — zawsze włączone wystąpienie klastra trybu failover
Do momentu wprowadzenia grup dostępności wystąpienia klastra trybu failover były najpopularniejszym sposobem implementowania wysokiej dostępności programu SQL Server. Klastry trybu failover zostały jednak zaprojektowane, gdy wdrożenia fizyczne były dominujące. W zwirtualizowanym świecie wystąpienia klastrów trybu failover nie zapewniają wielu tych samych zabezpieczeń w sposób, w jaki byłyby na sprzęcie fizycznym, ponieważ rzadko zdarza się, aby maszyna wirtualna miała problem. Interfejsy FCI zostały zaprojektowane w celu ochrony przed takimi elementami jak awaria karty sieciowej lub awaria dysku, które prawdopodobnie nie wystąpią na platformie Azure.
Mówiąc, że wystąpienia klastrów trybu failover mają miejsce na platformie Azure. Działają one i tak długo, jak masz odpowiednie oczekiwania dotyczące tego, co jest i nie jest zapewniane, wystąpienie klastra trybu failover jest całkowicie akceptowalnym rozwiązaniem. Na poniższej ilustracji z dokumentacji firmy Microsoft przedstawiono ogólny widok tego, jak wygląda wdrożenie wystąpienia klastra trybu failover podczas korzystania z usługi Miejsca do magazynowania Direct.
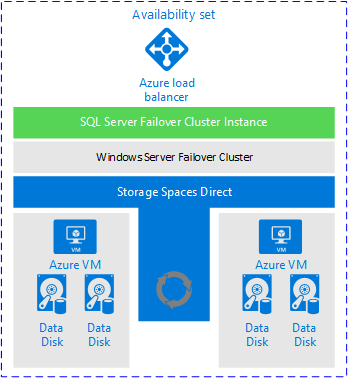
Dlaczego warto rozważyć tę architekturę?
Wystąpienia klastrów trybu failover są nadal popularnym rozwiązaniem dostępności.
Scenariusz magazynu udostępnionego jest ulepszany za pomocą funkcji, takiej jak dysk udostępniony platformy Azure.
Ta architektura spełnia większość czasu odzyskiwania i celu punktu odzyskiwania dla wysokiej dostępności (chociaż odzyskiwanie po awarii nie jest obsługiwane).
Ta architektura zapewnia łatwą, ustandaryzowaną metodę dla aplikacji w celu uzyskania dostępu do klastrowanego wystąpienia programu SQL Server.
Ta architektura zapewnia zwiększoną dostępność podczas scenariuszy stosowania poprawek.
Przykład odzyskiwania po awarii 1 — wieloregionowa lub hybrydowa zawsze włączona grupa dostępności
Jeśli używasz grup AG, jedną z opcji jest skonfigurowanie grupy dostępności w wielu regionach platformy Azure lub potencjalnie jako architektura hybrydowa. Oznacza to, że wszystkie węzły, które zawierają repliki, uczestniczą w tym samym WSFC. Zakłada to dobrą łączność sieciową, zwłaszcza jeśli jest to konfiguracja hybrydowa. Jednym z największych zagadnień byłoby zasób monitora dla WSFC. Ta architektura wymaga, aby usługi AD DS i DNS mogły być dostępne w każdym regionie i potencjalnie lokalnie, jeśli jest to rozwiązanie hybrydowe. Na poniższej ilustracji przedstawiono, jak wygląda jedna grupa dostępności skonfigurowana w dwóch lokalizacjach przy użyciu systemu Windows Server.

Dlaczego warto rozważyć tę architekturę?
Ta architektura jest sprawdzonym rozwiązaniem; nie różni się ona od posiadania dwóch centrów danych w topologii grupy dostępności.
Ta architektura współpracuje z wersjami Programu SQL Server w warstwie Standard i Enterprise.
Grupy Zabezpieczeń naturalnie zapewniają nadmiarowość z dodatkowymi kopiami danych.
Ta architektura korzysta z jednej funkcji, która zapewnia zarówno wysoką dostępność, jak i funkcję odzyskiwania po awarii
Przykład odzyskiwania po awarii 2 — rozproszona grupa dostępności
Rozproszona grupa dostępności to funkcja dostępna tylko w wersji Enterprise Edition wprowadzona w programie SQL Server 2016. Różni się ona od tradycyjnej grupy dostępności. Zamiast mieć jedną podstawową usługę WSFC, w której wszystkie węzły zawierają repliki uczestniczące w jednej grupy dostępności zgodnie z opisem w poprzednim przykładzie, rozproszona grupa dostępności składa się z wielu grup dostępności. Replika podstawowa zawierająca bazę danych zapisu odczytu jest znana jako globalna podstawowa. Podstawowa druga grupa dostępności jest znana jako usługa przesyłania dalej i przechowuje repliki pomocnicze tej grupy dostępności w synchronizacji. W istocie jest to grupa dostępności grup zabezpieczeń.
Ta architektura ułatwia radzenie sobie z rzeczami takimi jak kworum, ponieważ każdy klaster zachowa własny kworum, co oznacza, że ma również własny monitor. Rozproszona grupa dostępności będzie działać niezależnie od tego, czy używasz platformy Azure dla wszystkich zasobów, czy też korzystasz z architektury hybrydowej.
Na poniższej ilustracji przedstawiono przykładową konfigurację rozproszonej grupy dostępności. Istnieją dwa narzędzia WSFCs. Wyobraź sobie, że każda z nich znajduje się w innym regionie świadczenia usługi Azure lub znajduje się lokalnie, a druga znajduje się na platformie Azure. Każda usługa WSFC ma grupę dostępności z dwiema replikami. Globalna podstawowa grupa dostępności 1 utrzymuje pomocniczą replikę grupy dostępności 1 zsynchronizowane, a także usługę przesyłania dalej, która jest również podstawowym elementem grupy dostępności 2. Ta replika przechowuje replikę pomocniczą grupy dostępności 2 zsynchronizowane.
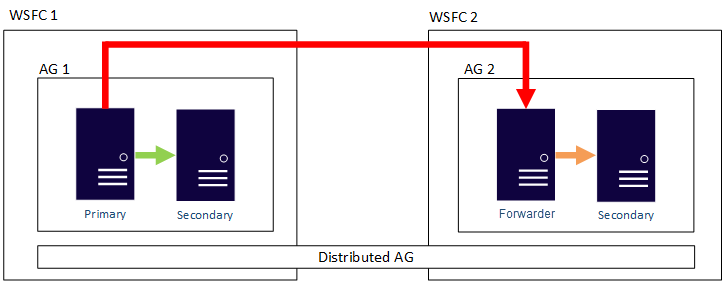
Dlaczego warto rozważyć tę architekturę?
Ta architektura oddziela usługę WSFC jako pojedynczy punkt awarii, jeśli wszystkie węzły utracą komunikację
W tej architekturze jedna podstawowa nie synchronizuje wszystkich replik pomocniczych.
Ta architektura może zapewnić powrót po awarii z jednej lokalizacji do innej.
Przykład odzyskiwania po awarii 3 — wysyłanie dziennika
Wysyłanie dziennika jest jedną z najstarszych metod HADR do konfigurowania odzyskiwania po awarii dla programu SQL Server. Jak opisano powyżej, jednostką miary jest kopia zapasowa dziennika transakcji. Jeśli nie planowane jest przełączenie do ciepłej rezerwy w celu zapewnienia braku utraty danych, najprawdopodobniej nastąpi utrata danych. Jeśli chodzi o odzyskiwanie po awarii, zawsze najlepiej zakładać utratę danych, nawet jeśli jest to minimalne. Na poniższej ilustracji z dokumentacji firmy Microsoft przedstawiono przykładową topologię wysyłki dziennika.
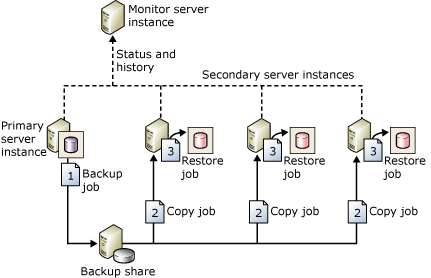
Dlaczego warto rozważyć tę architekturę?
Wysyłanie dziennika to funkcja wypróbowana i prawdziwa, która istnieje od ponad 20 lat
Wysyłanie dzienników jest łatwe do wdrożenia i administrowania, ponieważ jest ono oparte na kopii zapasowej i przywracania.
Wysyłanie dzienników jest odporne na sieci, które nie są niezawodne.
Wysyłanie dziennika spełnia większość celów celu czasu odzyskiwania i celu punktu odzyskiwania dla odzyskiwania po awarii.
Wysyłanie dzienników to dobry sposób ochrony wystąpień klastra trybu failover.
Przykład odzyskiwania po awarii 4 — Azure Site Recovery
Dla tych, którzy nie chcą implementować rozwiązania po awarii opartego na programie SQL Server, usługa Azure Site Recovery jest potencjalną opcją. Jednak większość specjalistów ds. danych preferuje podejście skoncentrowane na bazie danych, ponieważ zazwyczaj będzie miało niższy cel punktu odzyskiwania.
Poniższy obraz z dokumentacji firmy Microsoft. pokazuje, gdzie w witrynie Azure Portal można skonfigurować replikację dla usługi Azure Site Recovery.
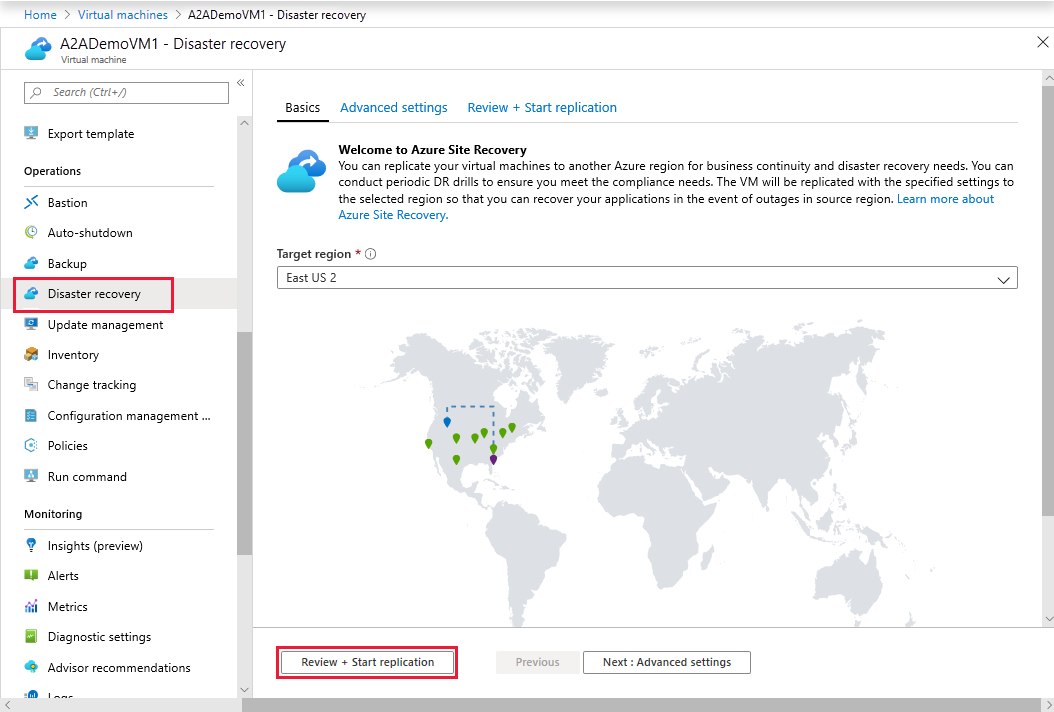
Dlaczego warto rozważyć tę architekturę?
Usługa Azure Site Recovery będzie działać z więcej niż tylko programem SQL Server.
Usługa Azure Site Recovery może spełniać cel czasu odzyskiwania i prawdopodobnie cel punktu odzyskiwania.
Usługa Azure Site Recovery jest udostępniana jako część platformy Azure.