Omówienie hiperskala bazy danych SQL
Usługa Azure SQL Database jest ograniczona do 4 TB magazynu na bazę danych od wielu lat. To ograniczenie jest spowodowane fizycznym ograniczeniem infrastruktury platformy Azure. Warstwa Hiperskala usługi Azure SQL Database zmienia model i umożliwia bazom danych co najmniej 100 TB. Hiperskala wprowadza nowe techniki skalowania w poziomie w celu dodawania węzłów obliczeniowych w miarę wzrostu rozmiarów danych. Koszt hiperskala jest taki sam jak koszt usługi Azure SQL Database; jednak istnieje koszt za terabajt dla magazynu. Należy pamiętać, że po przekonwertowaniu bazy danych Azure SQL Database na hiperskala nie można przekonwertować jej z powrotem na "zwykłą" bazę danych Azure SQL Database. Hiperskala to możliwość odpowiedniego skalowania architektury zgodnie z wymaganiami.
Hiperskala usługi Azure SQL Database to świetna opcja dla większości obciążeń biznesowych, ponieważ zapewnia dużą elastyczność i wysoką wydajność z niezależnie skalowalnymi zasobami obliczeniowymi i magazynowymi.
Hiperskala oddziela aparat przetwarzania zapytań, w którym semantyka różnych aparatów danych różni się od składników zapewniających długoterminowe przechowywanie i trwałość danych. W ten sposób pojemność magazynu może być bezproblemowo skalowana w poziomie w miarę potrzeb.
Warstwa usługi Hiperskala w usłudze Azure SQL Database to najnowsza warstwa usługi w modelu zakupów opartym na rdzeniach wirtualnych. Ta warstwa usługi to wysoce skalowalna warstwa wydajności magazynu i zasobów obliczeniowych, która używa platformy Azure do skalowania w poziomie zasobów magazynu i zasobów obliczeniowych dla usługi Azure SQL Database znacznie poza limity dostępne dla warstw ogólnego przeznaczenia i Krytyczne dla działania firmy warstw usług.
Świadczenia
Warstwa usługi Hiperskala usuwa wiele praktycznych limitów tradycyjnie spotykanych w bazach danych w chmurze. Jeśli większość innych baz danych jest ograniczona przez zasoby dostępne w jednym węźle, bazy danych w warstwie usługi Hiperskala nie mają takich limitów. Dzięki elastycznej architekturze magazynu magazyn rośnie w miarę potrzeb. W rzeczywistości bazy danych w warstwie Hiperskala nie są tworzone przy użyciu zdefiniowanego maksymalnego rozmiaru. Baza danych w warstwie Hiperskala rośnie zgodnie z potrzebami — a opłaty są naliczane tylko za używaną pojemność. W przypadku obciążeń intensywnie korzystających z odczytu warstwa usługi Hiperskala zapewnia szybkie skalowanie w poziomie, aprowizując dodatkowe repliki zgodnie z potrzebami na potrzeby odciążania obciążeń odczytu.
Ponadto czas wymagany do utworzenia kopii zapasowych bazy danych lub skalowania w górę lub w dół nie jest już powiązany z ilością danych w bazie danych. Bazy danych w warstwie Hiperskala mogą być tworzone natychmiast. Bazę danych można również skalować w dziesiątkach terabajtów w górę lub w dół w ciągu kilku minut. Ta funkcja pozwala uwolnić Cię od obaw dotyczących bycia w pudełku przez początkowe opcje konfiguracji. Hiperskala zapewnia również szybkie przywracanie bazy danych, które działa w minutach, a nie godzinach lub dniach.
Hiperskala zapewnia szybką skalowalność na podstawie zapotrzebowania na obciążenie.
Skalowanie w górę/w dół — można skalować w górę podstawowy rozmiar obliczeniowy pod względem zasobów, takich jak procesor CPU i pamięć, a następnie skalować w dół w stałym czasie. Ponieważ magazyn jest współużytkowany, skalowanie w górę i skalowanie w dół nie jest połączone z ilością danych w bazie danych.
Skalowanie w/wy — możesz również aprowizować co najmniej jedną replikę obliczeniową, której można użyć do obsługi żądań odczytu. Oznacza to, że można użyć dodatkowych replik obliczeniowych jako replik tylko do odczytu, aby odciążyć obciążenie odczytu z podstawowych obliczeń. Oprócz tylko do odczytu te repliki służą również jako rezerwy dynamiczne do pracy w trybie failover z serwera podstawowego.
Aprowizacja każdej z tych dodatkowych replik obliczeniowych może odbywać się w stałym czasie i jest operacją online. Możesz nawiązać połączenie z replikami obliczeniowymi tylko do odczytu, ustawiając argument ApplicationIntent na parametry połączenia na ReadOnly. Wszystkie połączenia z intencją aplikacji ReadOnly są automatycznie kierowane do jednej z replik obliczeniowych tylko do odczytu.
Hiperskala oddziela aparat przetwarzania zapytań od składników, które zapewniają długoterminowe przechowywanie i trwałość danych. Ta architektura umożliwia bezproblemowe skalowanie pojemności magazynu w razie potrzeby (początkowy cel to 100 TB) oraz możliwość szybkiego skalowania zasobów obliczeniowych.
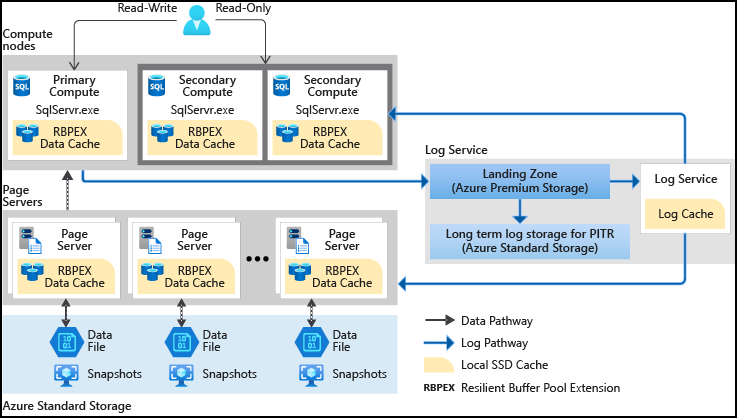
Zagadnienia dotyczące zabezpieczeń
Zabezpieczenia dla warstwy usługi Hiperskala mają takie same doskonałe możliwości jak inne warstwy usługi Azure SQL Database. Są one chronione przez warstwowe podejście do ochrony w głębi systemu, jak pokazano na poniższej ilustracji, i przenosi się z zewnątrz w:
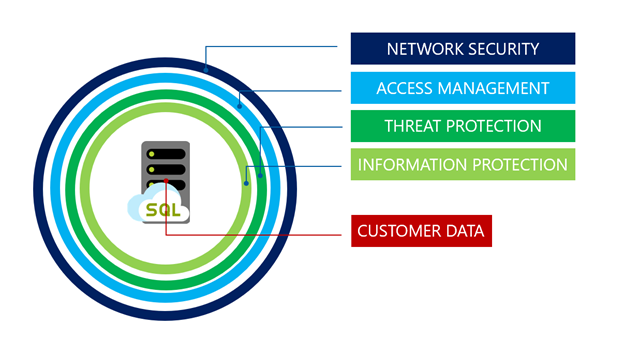
Zabezpieczenia sieci to pierwsza warstwa obrony i używa reguł zapory IP, aby zezwolić na dostęp na podstawie źródłowego adresu IP i reguł zapory sieci wirtualnej, aby umożliwić akceptowanie komunikacji wysyłanej z wybranych podsieci wewnątrz sieci wirtualnej.
Zarządzanie dostępem jest udostępniane za pośrednictwem poniższych metod uwierzytelniania, aby upewnić się, że użytkownik jest tym, którego twierdzi:
- Uwierzytelnianie SQL
- Uwierzytelnianie Microsoft Entra
- Uwierzytelnianie systemu Windows dla podmiotów zabezpieczeń firmy Microsoft (wersja zapoznawcza)
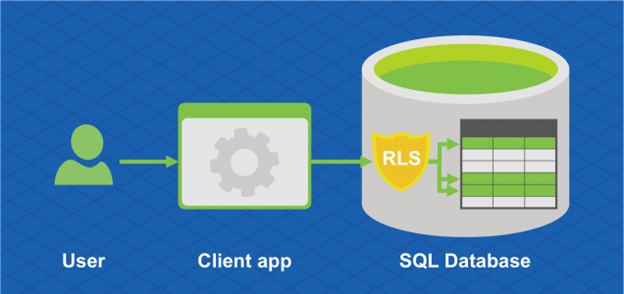
Hiperskala usługi Azure SQL Database obsługuje również zabezpieczenia na poziomie wiersza. Zabezpieczenia na poziomie wiersza umożliwiają klientom kontrolowanie dostępu do wierszy w tabeli bazy danych na podstawie cech użytkownika wykonującego zapytanie (na przykład członkostwa w grupie lub kontekstu wykonywania).
Możliwości ochrony przed zagrożeniami w funkcjach inspekcji i wykrywania zagrożeń. Inspekcja usług SQL Database i SQL Managed Instance śledzi działania bazy danych i pomaga zachować zgodność ze standardami zabezpieczeń przez rejestrowanie zdarzeń bazy danych w dzienniku inspekcji na koncie magazynu platformy Azure należącym do klienta. Zaawansowana ochrona przed zagrożeniami może być włączona na serwer za dodatkową opłatę i analizuje dzienniki w celu wykrycia nietypowego zachowania i potencjalnie szkodliwych prób uzyskania dostępu do baz danych lub wykorzystania ich. Alerty są tworzone dla podejrzanych działań, takich jak wstrzyknięcie kodu SQL, potencjalna infiltracja danych i ataki siłowe lub anomalie we wzorcach dostępu w celu przechwycenia eskalacji uprawnień i użycia poświadczeń z naruszeniem.
Usługa Information Protection jest udostępniana na następujące sposoby:
- Protokół Transport Layer Security (TLS) (Szyfrowanie w trakcie przesyłania)
- Transparent Data Encryption (szyfrowanie magazynowane)
- Zarządzanie kluczami za pomocą usługi Azure Key Vault
- Always Encrypted (szyfrowanie w użyciu)
- Dynamiczne maskowanie danych
Zagadnienia dotyczące wydajności
Warstwa usługi Hiperskala jest przeznaczona dla klientów, którzy mają duże lokalne bazy danych programu SQL Server i chcą zmodernizować swoje aplikacje przez przejście do chmury lub dla klientów, którzy już korzystają z usługi Azure SQL Database i chcą znacznie zwiększyć potencjał wzrostu bazy danych. Hiperskala jest również przeznaczona dla klientów, którzy szukają wysokiej wydajności i wysokiej skalowalności.
Hiperskala zapewnia następujące możliwości wydajności:
- Niemal natychmiastowe kopie zapasowe bazy danych (na podstawie migawek plików przechowywanych w usłudze Azure Blob Storage) niezależnie od rozmiaru bez wpływu operacji we/wy na zasoby obliczeniowe.
- Szybkie przywracanie bazy danych (na podstawie migawek plików) w minutach, a nie godzinach lub dniach (nie rozmiar operacji danych).
- Wyższa ogólna wydajność ze względu na większą przepływność dziennika transakcji i szybsze czasy zatwierdzania transakcji niezależnie od woluminów danych.
- Szybkie skalowanie w poziomie — można aprowizować co najmniej jedną replikę tylko do odczytu na potrzeby odciążania obciążenia odczytu i do użycia jako rezerwowe.
- Szybkie skalowanie w górę — możesz skalować zasoby obliczeniowe w górę w górę, aby w razie potrzeby obsłużyć duże obciążenia, a następnie skalować zasoby obliczeniowe z powrotem w dół, gdy nie są potrzebne.
Uwaga
Hiperskala usługi SQL Database nie obsługuje następujących funkcji:
- Wystąpienie zarządzane SQL
- Pule elastyczne
- Replikacja geograficzna
- Szczegółowe informacje o wydajności zapytań
Wdrażanie bazy danych Azure SQL Database w warstwie Hiperskala
Aby wdrożyć usługę Azure SQL Database z warstwą Hiperskala:
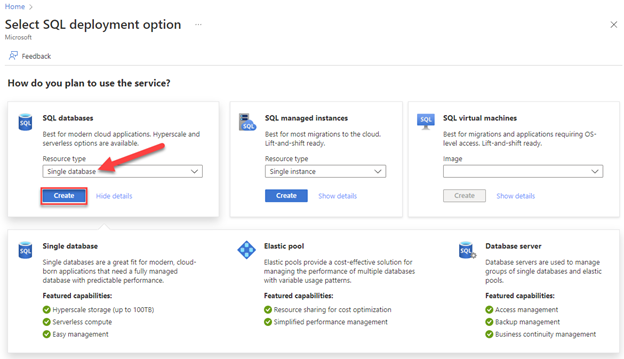
Przejdź do strony Wybierz wdrożenie SQL.
W obszarze Bazy danych SQL pozostaw wartość Typ zasobu ustawioną na Pojedyncza baza danych, a następnie wybierz pozycję Utwórz.
Na karcie Podstawowe na stronie Tworzenie bazy danych SQL Wybierz odpowiednią subskrypcję, grupę zasobów i nazwę bazy danych.
Wybierz link Utwórz nowy dla serwera i wypełnij nowe informacje o serwerze, takie jak nazwa serwera, identyfikator logowania administratora serwera i hasło oraz lokalizacja.
W obszarze Obliczenia i magazyn wybierz link Konfiguruj bazę danych .
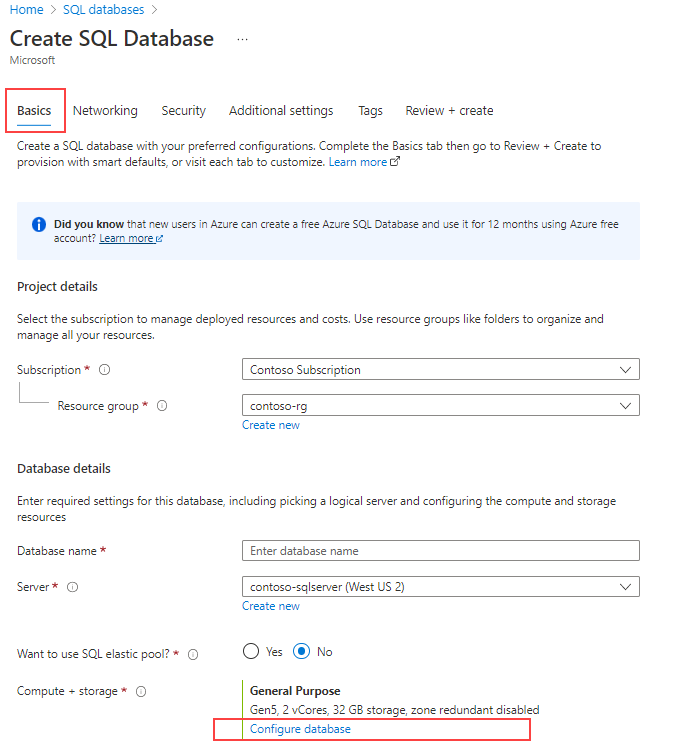
W obszarze Warstwa usługi wybierz pozycję Hiperskala.
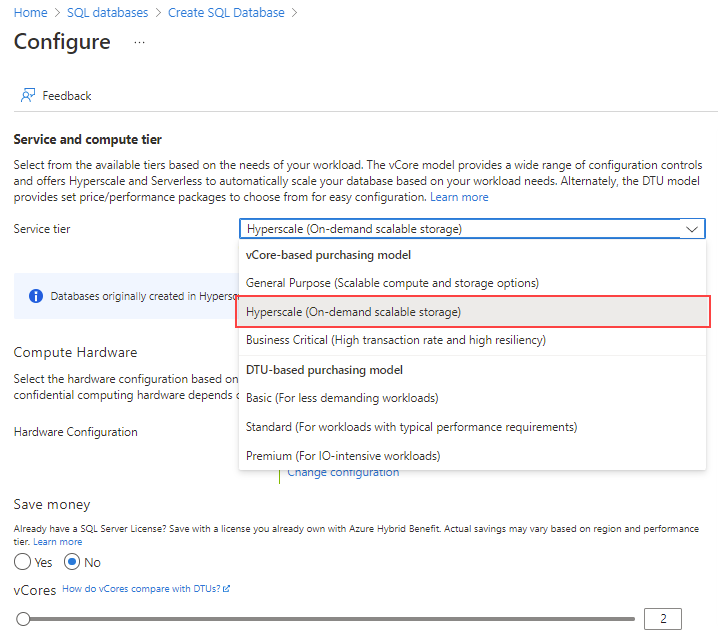
W obszarze Konfiguracja sprzętu wybierz link Zmień konfigurację. Przejrzyj dostępne konfiguracje sprzętu i wybierz najbardziej odpowiednią konfigurację bazy danych. W tym przykładzie wybierzemy konfigurację gen5 .
Wybierz przycisk OK, aby potwierdzić generowanie sprzętu.
Opcjonalnie dostosuj suwak Rdzenie wirtualne, jeśli chcesz zwiększyć liczbę rdzeni wirtualnych dla bazy danych. W tym przykładzie wybierzemy 2 rdzenie wirtualne.
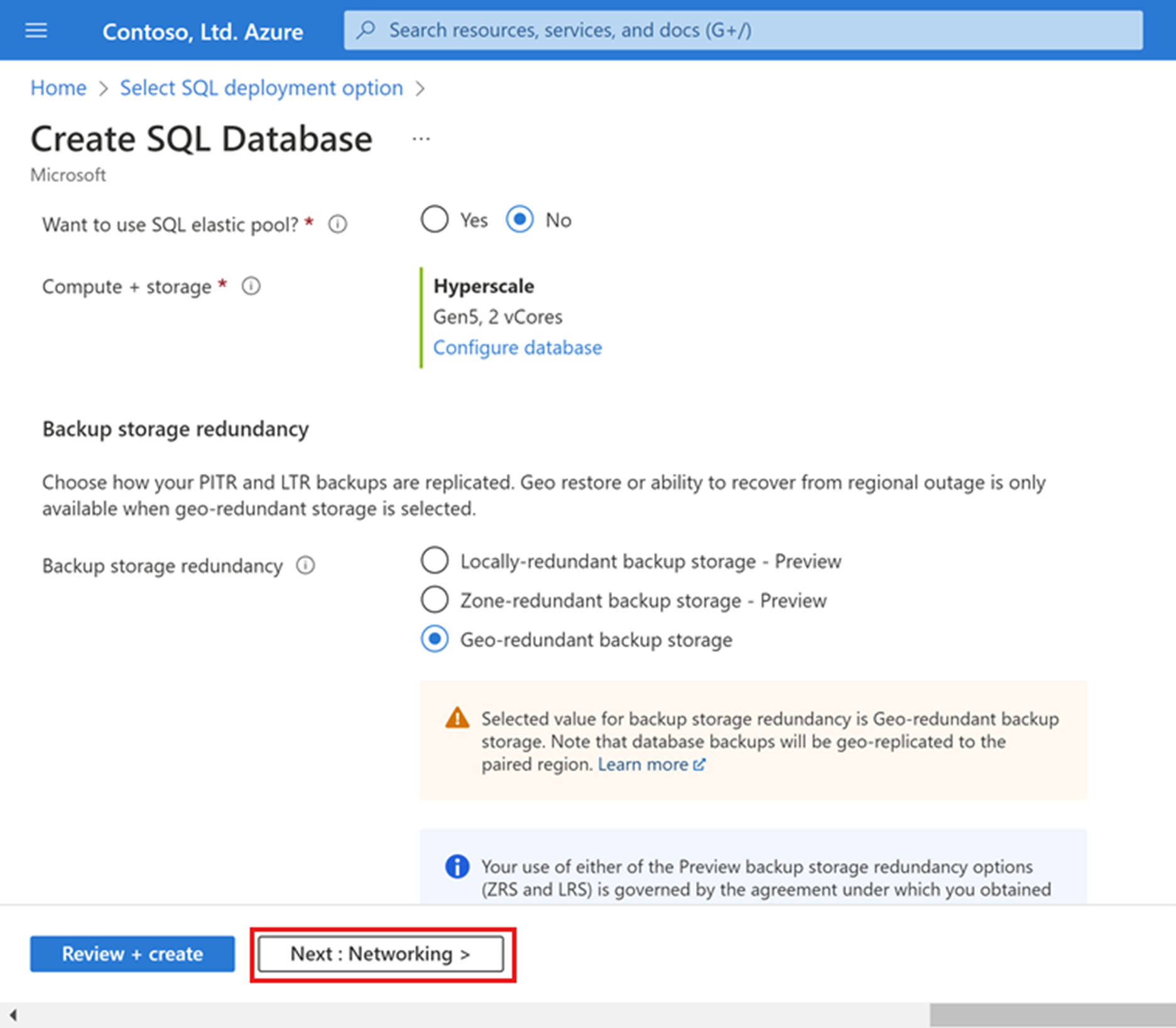
Dostosuj suwak Repliki pomocnicze o wysokiej dostępności, aby utworzyć jedną replikę wysokiej dostępności .. Wybierz Zastosuj.
Wybierz pozycję Dalej: Sieć w dolnej części strony.
W obszarze Reguły zapory na karcie Sieć ustaw wartość Dodaj bieżący adres IP klienta na wartość Tak. Pozostaw opcję Zezwalaj usługom i zasobom platformy Azure na dostęp do tego serwera ustawionego na nie.
Wybierz pozycję Dalej: Zabezpieczenia w dolnej części strony.
Na karcie Przeglądanie i tworzenie wybierz pozycję Utwórz.
