Wyjaśnienie opcji paaS wdrażania programu SQL Server na platformie Azure
Platforma jako usługa (PaaS) udostępnia kompletne środowisko programistyczne i wdrożeniowe w chmurze, które może służyć do prostych aplikacji opartych na chmurze, a także zaawansowanych aplikacji dla przedsiębiorstw.
Usługi Azure SQL Database i Azure SQL Managed Instance są częścią oferty PaaS dla usługi Azure SQL.
Azure SQL Database — część rodziny produktów utworzonych na podstawie aparatu programu SQL Server w chmurze. Zapewnia deweloperom dużą elastyczność tworzenia nowych usług aplikacji i szczegółowych opcji wdrażania na dużą skalę. Usługa SQL Database oferuje rozwiązanie o niskiej konserwacji, które może być doskonałym rozwiązaniem dla niektórych obciążeń.
Azure SQL Managed Instance — najlepiej jest korzystać z większości scenariuszy migracji do chmury, ponieważ zapewnia w pełni zarządzane usługi i możliwości.
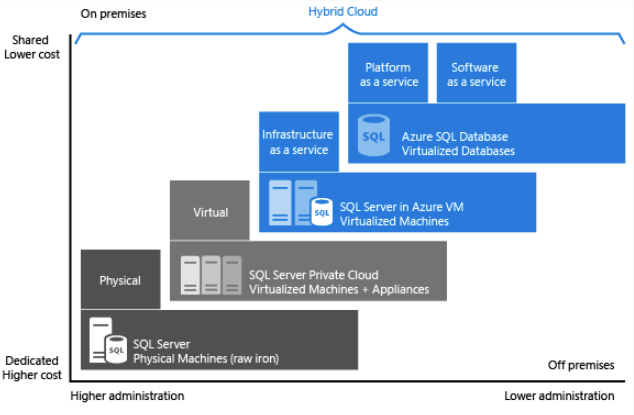
Jak widać na powyższej ilustracji, każda oferta zapewnia pewien poziom administracji w infrastrukturze, o stopień efektywności kosztowej.
Modele wdrażania
Usługa Azure SQL Database jest dostępna w dwóch różnych modelach wdrażania:
Pojedyncza baza danych — pojedyncza baza danych, która jest rozliczana i zarządzana na poziomie bazy danych. Każda z baz danych jest zarządzana indywidualnie z perspektywy skalowania i rozmiaru danych. Każda baza danych wdrożona w tym modelu ma własne dedykowane zasoby, nawet jeśli zostały wdrożone na tym samym serwerze logicznym.
Pule elastyczne — grupa baz danych, które są zarządzane razem i współużytkują wspólny zestaw zasobów. Pule elastyczne zapewniają ekonomiczne rozwiązanie dla modelu aplikacji typu oprogramowanie jako usługa, ponieważ zasoby są współdzielone między wszystkimi bazami danych. Zasoby można skonfigurować na podstawie modelu zakupów opartego na jednostkach DTU lub modelu zakupów opartego na rdzeniach wirtualnych.
Model zakupów
Na platformie Azure wszystkie usługi są wspierane przez sprzęt fizyczny i można wybrać spośród dwóch różnych modeli zakupów:
Jednostka transakcji bazy danych (DTU)
Jednostki DTU są obliczane na podstawie formuły łączącej zasoby obliczeniowe, magazynowe i we/wy. Jest to dobry wybór dla klientów, którzy chcą prostych, wstępnie skonfigurowanych opcji zasobów.
Model zakupów jednostek DTU jest dostępny w kilku różnych warstwach usług, takich jak Podstawowa, Standardowa i Premium. Każda warstwa ma różne możliwości, które zapewniają szeroką gamę opcji podczas wybierania tej platformy.
Pod względem wydajności warstwa Podstawowa jest używana dla mniej wymagających obciążeń, podczas gdy warstwa Premium jest używana do intensywnych wymagań dotyczących obciążeń.
Zasoby obliczeniowe i magazynowe są zależne od poziomu jednostek DTU i zapewniają szereg możliwości wydajności przy stałym limicie magazynu, przechowywaniu kopii zapasowych i kosztach.
Uwaga
Model zakupów jednostek DTU jest obsługiwany tylko przez usługę Azure SQL Database.
Aby uzyskać więcej informacji na temat modelu zakupów jednostek DTU, zobacz Omówienie modelu zakupów opartego na jednostkach DTU.
Rdzenie wirtualne
Model rdzeni wirtualnych umożliwia zakup określonej liczby rdzeni wirtualnych na podstawie podanych obciążeń. Rdzenie wirtualne to domyślny model zakupów podczas zakupu zasobów usługi Azure SQL Database. Bazy danych rdzeni wirtualnych mają określoną relację między liczbą rdzeni a ilością pamięci i magazynem dostarczonym do bazy danych. Model zakupów rdzeni wirtualnych jest obsługiwany przez usługę Azure SQL Database i usługę Azure SQL Managed Instance.
Bazy danych rdzeni wirtualnych można również kupić w trzech różnych warstwach usług:
Ogólnego przeznaczenia — ta warstwa jest przeznaczony dla obciążeń ogólnego przeznaczenia. Jest on wspierany przez usługę Azure Premium Storage. Będzie to miało większe opóźnienie niż Krytyczne dla działania firmy. Udostępnia również następujące warstwy obliczeniowe:
- Aprowizuj — zasoby obliczeniowe są wstępnie przydzielane. Rozliczane na godzinę na podstawie skonfigurowanych rdzeni wirtualnych.
- Bezserwerowe — zasoby obliczeniowe są skalowane automatycznie. Rozliczane na sekundę na podstawie użytych rdzeni wirtualnych.
Krytyczne dla działania firmy — Ta warstwa jest przeznaczony dla obciążeń o wysokiej wydajności, co zapewnia najmniejsze opóźnienie jednej z warstw usług. Ta warstwa jest wspierana przez lokalne dyski SSD zamiast usługi Azure Blob Storage. Zapewnia również najwyższą odporność na awarie, a także zapewnia wbudowaną replikę bazy danych tylko do odczytu, która może służyć do obciążeń raportowania poza obciążeniem.
Hiperskala — bazy danych w warstwie Hiperskala mogą być skalowane znacznie poza limitem 4 TB innych ofert usługi Azure SQL Database i mają unikatową architekturę, która obsługuje bazy danych o rozmiarze do 100 TB.
Praca bezserwerowa
Nazwa "Bezserwerowa" może być nieco myląca, ponieważ nadal wdrażasz usługę Azure SQL Database na serwerze logicznym, z którym nawiązujesz połączenie. Bezserwerowa usługa Azure SQL Database to warstwa obliczeniowa, która automatycznie skaluje zasoby w górę lub w dół dla danej bazy danych na podstawie zapotrzebowania na obciążenie. Jeśli obciążenie nie wymaga już zasobów obliczeniowych, baza danych stanie się "wstrzymana", a opłaty za magazyn będą naliczane tylko w okresie, w których baza danych jest nieaktywna. Po podjęciu próby nawiązania połączenia baza danych zostanie "wznowiona" i stanie się dostępna.
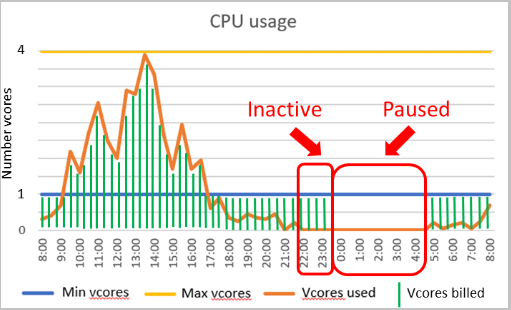
Ustawienie do kontrolowania wstrzymania jest określane jako opóźnienie autopaużytu i ma minimalną wartość 60 minut i maksymalną wartość siedmiu dni. Jeśli baza danych była bezczynna przez ten okres, zostanie wstrzymana.
Gdy baza danych będzie nieaktywna przez określony czas, zostanie wstrzymana do momentu podjęcia kolejnej próby nawiązania połączenia. Konfigurowanie zakresu skalowania automatycznego obliczeń i opóźnienie automatycznego wstrzymywania wpływa na wydajność bazy danych i koszty obliczeń.
Wszystkie aplikacje korzystające z bezserwerowych powinny być skonfigurowane do obsługi błędów połączenia i uwzględniać logikę ponawiania prób, ponieważ nawiązanie połączenia z wstrzymaną bazą danych spowoduje wygenerowanie błędu połączenia.
Kolejną różnicą między modelem bezserwerowym a normalnym modelem rdzeni wirtualnych usługi Azure SQL Database jest to, że bezserwerowa można określić minimalną i maksymalną liczbę rdzeni wirtualnych. Limity pamięci i operacji we/wy są proporcjonalne do określonego zakresu.
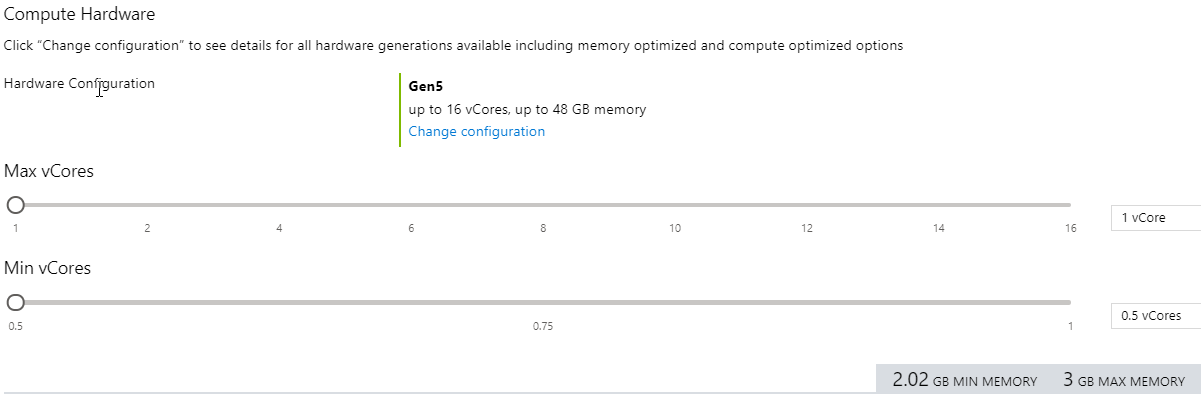
Na powyższym obrazie przedstawiono ekran konfiguracji bezserwerowej bazy danych w witrynie Azure Portal. Możesz wybrać minimalną połowę rdzeni wirtualnych i maksymalnie maksymalnie 16 rdzeni wirtualnych.
Bezserwerowa nie jest w pełni zgodna ze wszystkimi funkcjami usługi Azure SQL Database, ponieważ niektóre z nich wymagają uruchamiania procesów w tle przez cały czas, takich jak:
- Replikacja geograficzna
- Długoterminowe przechowywanie kopii zapasowych
- Baza danych zadań w zadaniach elastycznych
- Baza danych synchronizacji w usłudze SQL Data Sync (Data Sync to usługa, która replikuje dane między grupą baz danych)
Uwaga
Usługa SQL Database bezserwerowa jest obecnie obsługiwana tylko w warstwie Ogólnego przeznaczenia w modelu zakupów rdzeni wirtualnych.
Kopie zapasowe
Jedną z najważniejszych funkcji oferty platformy jako usługi jest tworzenie kopii zapasowych. W takim przypadku kopie zapasowe są wykonywane automatycznie bez żadnej interwencji użytkownika. Kopie zapasowe są przechowywane w magazynie geograficznie nadmiarowym obiektów blob platformy Azure, a domyślnie są przechowywane przez okres od 7 do 35 dni na podstawie warstwy usługi bazy danych. Podstawowe i rdzenie wirtualne bazy danych są domyślnie do siedmiu dni przechowywania, a w bazach danych rdzeni wirtualnych tę wartość można dostosować przez administratora. Czas przechowywania można przedłużyć, konfigurując przechowywanie długoterminowe (LTR), co pozwoli na przechowywanie kopii zapasowych przez maksymalnie 10 lat.
Aby zapewnić nadmiarowość, można również użyć dostępnego do odczytu magazynu obiektów blob geograficznie nadmiarowych. Ten magazyn replikuje kopie zapasowe bazy danych do pomocniczego regionu preferencji. Umożliwi to również odczyt z tego regionu pomocniczego w razie potrzeby. Ręczne tworzenie kopii zapasowych baz danych nie jest obsługiwane, a platforma odmówi wykonania jakichkolwiek żądań.
Kopie zapasowe bazy danych są wykonywane zgodnie z określonym harmonogramem:
- Pełny — raz w tygodniu
- Różnicowy — co 12 godzin
- Dziennik — co 5–10 minut w zależności od aktywności dziennika transakcji
Ten harmonogram tworzenia kopii zapasowych powinien spełniać potrzeby większości celów punktu/czasu odzyskiwania (RPO/RTO), jednak każdy klient powinien ocenić, czy spełniają wymagania biznesowe.
Istnieje kilka opcji przywracania bazy danych. Ze względu na charakter platformy jako usługi nie można ręcznie przywrócić bazy danych przy użyciu konwencjonalnych metod, takich jak wydawanie polecenia RESTORE DATABASEjęzyka T-SQL.
Niezależnie od tego, która metoda przywracania jest zaimplementowana, nie można przywrócić istniejącej bazy danych. Jeśli należy przywrócić bazę danych, należy usunąć istniejącą bazę danych lub zmienić jej nazwę przed zainicjowaniem procesu przywracania. Ponadto należy pamiętać, że w zależności od warstwy usługi platformy czasy przywracania nie są gwarantowane i mogą się wahać. Zaleca się przetestowanie procesu przywracania w celu uzyskania metryki bazowej dotyczącej tego, jak długo może trwać przywracanie.
Dostępne opcje przywracania to:
Przywracanie przy użyciu witryny Azure Portal — w witrynie Azure Portal możesz przywrócić bazę danych na tym samym serwerze usługi Azure SQL Database lub użyć przywracania, aby utworzyć nową bazę danych na nowym serwerze w dowolnym regionie świadczenia usługi Azure.
Przywracanie przy użyciu języków skryptów — w celu przywrócenia bazy danych można użyć zarówno programu PowerShell, jak i interfejsu wiersza polecenia platformy Azure.
Uwaga
Kopia zapasowa tylko do kopiowania do usługi Azure Blob Storage jest dostępna dla usługi SQL Managed Instance. Usługa SQL Database nie obsługuje tej funkcji.
Aby uzyskać więcej informacji na temat automatycznych kopii zapasowych, zobacz Automatyczne kopie zapasowe — Azure SQL Database i Azure SQL Managed Instance.
Aktywna replikacja geograficzna
Replikacja geograficzna to funkcja ciągłości działania, która asynchronicznie replikuje bazę danych do maksymalnie czterech replik pomocniczych. Ponieważ transakcje są zatwierdzane w obiekcie podstawowym (i jego replikach w tym samym regionie), transakcje są wysyłane do serwerów pomocniczych, które mają być odtwarzane. Ponieważ ta komunikacja jest wykonywana asynchronicznie, aplikacja wywołująca nie musi czekać, aż replika pomocnicza zatwierdzi transakcję przed zwróceniem kontroli do obiektu wywołującego programu SQL Server.
Pomocnicze bazy danych są czytelne i mogą służyć do odciążania obciążeń tylko do odczytu, dzięki czemu zwalniają zasoby dla obciążeń transakcyjnych na serwerze podstawowym lub umieszczają dane bliżej użytkowników końcowych. Ponadto pomocnicze bazy danych mogą znajdować się w tym samym regionie co podstawowy lub w innym regionie świadczenia usługi Azure.
Replikacja geograficzna umożliwia zainicjowanie trybu failover ręcznie przez użytkownika lub aplikację. Jeśli nastąpi przejście w tryb failover, potencjalnie trzeba będzie zaktualizować parametry połączenia aplikacji, aby odzwierciedlić nowy punkt końcowy tego, co jest teraz podstawową bazą danych.
Grupy trybu failover
Grupy trybu failover są oparte na technologii używanej w replikacji geograficznej, ale zapewniają jeden punkt końcowy dla połączenia. Główną przyczyną używania grup trybu failover jest to, że technologia udostępnia punkty końcowe, których można użyć do kierowania ruchu do odpowiedniej repliki. Aplikacja może następnie łączyć się po przejściu w tryb failover bez parametry połączenia zmian.