Eksplorowanie wydajności i zabezpieczeń
Ekosystem platformy Azure oferuje kilka opcji wydajności i zabezpieczeń dla wystąpienia programu SQL Server na maszynie wirtualnej platformy Azure. Każda opcja zapewnia kilka możliwości, takich jak różne typy dysków, które spełniają wymagania dotyczące pojemności i wydajności obciążenia.
Zagadnienia dotyczące magazynu
Program SQL Server wymaga dobrej wydajności magazynu, aby zapewnić niezawodną wydajność aplikacji, niezależnie od tego, czy jest to wystąpienie lokalne, czy zainstalowane na maszynie wirtualnej platformy Azure. Platforma Azure oferuje szeroką gamę rozwiązań magazynu, które spełniają potrzeby obciążenia. Platforma Azure oferuje różne typy magazynów (obiekty blob, pliki, kolejki, tabele) w większości przypadków obciążenia programu SQL Server będą używać dysków zarządzanych platformy Azure. Wyjątki są następujące, że wystąpienie klastra trybu failover można skompilować na magazynie plików, a kopie zapasowe będą używać magazynu obiektów blob. Dyski zarządzane platformy Azure działają jako urządzenie magazynu na poziomie bloku, które jest prezentowane maszynie wirtualnej platformy Azure. Dyski zarządzane oferują szereg korzyści, w tym dostępność na poziomie 99,999%, skalowalne wdrożenie (w przypadku awarii można mieć do 50 000 dysków maszyn wirtualnych na subskrypcję) oraz integrację z zestawami dostępności i strefami, aby zapewnić wyższy poziom odporności.
Wszystkie dyski zarządzane platformy Azure oferują dwa typy szyfrowania. Szyfrowanie po stronie serwera platformy Azure jest dostarczane przez usługę magazynu i działa jako szyfrowanie magazynowane udostępniane przez usługę magazynu. Usługa Azure Disk Encryption używa funkcji BitLocker w systemie Windows i narzędzia DM-Crypt w systemie Linux w celu zapewnienia szyfrowania dysków systemu operacyjnego i danych wewnątrz maszyny wirtualnej. Obie technologie integrują się z usługą Azure Key Vault i umożliwiają korzystanie z własnego klucza szyfrowania.
Każda maszyna wirtualna będzie mieć co najmniej dwa skojarzone z nim dyski:
Dysk systemu operacyjnego — każda maszyna wirtualna będzie wymagać dysku systemu operacyjnego zawierającego wolumin rozruchowy. Ten dysk będzie dyskiem C: w przypadku maszyny wirtualnej platformy Windows lub /dev/sda1 w systemie Linux. System operacyjny zostanie automatycznie zainstalowany na dysku systemu operacyjnego.
Dysk tymczasowy — każda maszyna wirtualna będzie zawierać jeden dysk używany do przechowywania tymczasowego. Ten magazyn ma być używany w przypadku danych, które nie muszą być trwałe, takie jak pliki stronicowania lub pliki wymiany. Ponieważ dysk jest tymczasowy, nie należy go używać do przechowywania żadnych krytycznych informacji, takich jak bazy danych lub pliki dziennika transakcji, ponieważ zostaną utracone podczas konserwacji lub ponownego uruchomienia maszyny wirtualnej. Ten dysk zostanie zainstalowany jako D:\ w systemie Windows i /dev/sdb1 w systemie Linux.
Ponadto możesz i należy dodać dodatkowe dyski danych do maszyn wirtualnych platformy Azure z uruchomionym programem SQL Server.
- Dyski danych — termin dysk danych jest używany w witrynie Azure Portal, ale w praktyce są to tylko dodatkowe dyski zarządzane dodane do maszyny wirtualnej. Te dyski można pulować w celu zwiększenia dostępnych operacji we/wy i pojemności magazynu przy użyciu Miejsca do magazynowania w systemie Windows lub zarządzanie woluminami logicznymi w systemie Linux.
Ponadto każdy dysk może być jednym z kilku typów:
| Funkcja | Dysk Ultra Disk | Dysk SSD w warstwie Premium | Dysk SSD w warstwie Standardowa | Dysk HDD w warstwie Standardowa |
|---|---|---|---|---|
| Typ dysku | SSD | SSD | SSD | HDD |
| Najlepsze dla | Obciążenie intensywnie korzystające z operacji we/wy | Obciążenie wrażliwe na wydajność | Uproszczone obciążenia | Kopie zapasowe, obciążenia niekrytyczne |
| Maksymalny rozmiar dysku | 65 536 GiB | 32 767 GiB | 32 767 GiB | 32 767 GiB |
| Maksymalna przepustowość | 2000 MB/s | 900 MB/s | 750 MB/s | 500 MB/s |
| Maks. liczba operacji we/wy na sekundę | 160 000 | 20 000 | 6000 | 2000 |
Najlepsze rozwiązania dotyczące programu SQL Server na platformie Azure zalecają używanie dysków w warstwie Premium w puli w celu zwiększenia liczby operacji we/wy i pojemności magazynu. Pliki danych powinny być przechowywane we własnej puli z buforowaniem odczytu na dyskach platformy Azure.
Pliki dziennika transakcji nie będą korzystać z tego buforowania, więc pliki te powinny przejść do własnej puli bez buforowania. Baza danych TempDB może opcjonalnie przejść do własnej puli lub użyć dysku tymczasowego maszyny wirtualnej, co zapewnia małe opóźnienie, ponieważ jest fizycznie dołączone do serwera fizycznego, na którym działają maszyny wirtualne. Prawidłowo skonfigurowane dyski SSD w warstwie Premium będą widzieć opóźnienia w milisekundach pojedynczej cyfry. W przypadku obciążeń o znaczeniu krytycznym, które wymagają mniejszego opóźnienia, należy rozważyć użycie dysków SSD w warstwie Ultra.
Zagadnienia dotyczące zabezpieczeń
Istnieje kilka branżowych przepisów i standardów, które platforma Azure spełnia, co umożliwia utworzenie zgodnego rozwiązania z programem SQL Server uruchomionym na maszynie wirtualnej.
Usługa Microsoft Defender dla usługi SQL
Usługa Microsoft Defender for SQL udostępnia funkcje zabezpieczeń usługi Azure Security Center, takie jak oceny luk w zabezpieczeniach i alerty zabezpieczeń.
Usługa Azure Defender for SQL może służyć do identyfikowania i eliminowania potencjalnych luk w zabezpieczeniach w wystąpieniu i bazie danych programu SQL Server. Funkcja oceny luk w zabezpieczeniach może wykrywać potencjalne zagrożenia w środowisku programu SQL Server i pomóc w ich skorygowaniu. Zapewnia również wgląd w stan zabezpieczeń i kroki umożliwiające podejmowanie działań w celu rozwiązania problemów z zabezpieczeniami.
Azure Security Center
Azure Security Center to ujednolicony system zarządzania zabezpieczeniami, który ocenia i oferuje możliwości poprawy kilku aspektów zabezpieczeń środowiska danych. Usługa Azure Security Center zapewnia kompleksowy wgląd w kondycję zabezpieczeń wszystkich zasobów chmury hybrydowej.
Zagadnienia dotyczące wydajności
Większość istniejących lokalnych funkcji wydajności programu SQL Server jest również dostępna na maszynach wirtualnych platformy Azure. Wśród oferowanych opcji jest kompresja danych, która może zwiększyć wydajność obciążeń intensywnie korzystających z operacji we/wy przy jednoczesnym zmniejszeniu rozmiaru bazy danych. Podobnie partycjonowanie tabel i indeksów może poprawić wydajność zapytań dla dużych tabel, jednocześnie zwiększając wydajność i skalowalność.
Partycjonowanie tabel
Partycjonowanie tabel zapewnia wiele korzyści, ale często ta strategia jest brana pod uwagę tylko wtedy, gdy tabela staje się wystarczająco duża, aby zaczynać pogarszać wydajność zapytań. Określenie, które tabele są kandydatami do partycjonowania tabel, jest dobrą praktyką, która może prowadzić do mniejszej liczby zakłóceń i interwencji. Podczas filtrowania danych przy użyciu kolumny partycji uzyskuje się dostęp tylko do podzbioru danych, a nie całej tabeli. Podobnie operacje konserwacji w tabeli partycjonowanej skrócią czas trwania konserwacji, na przykład przez kompresowanie określonych danych w określonej partycji lub ponowne kompilowanie określonych partycji indeksu.
Podczas definiowania partycji tabeli wymagane są cztery główne kroki:
- Tworzenie grup plików, które definiuje pliki związane z tworzeniem partycji.
- Tworzenie funkcji partycji, która definiuje reguły partycji na podstawie określonej kolumny.
- Tworzenie schematu partycji, który definiuje grupę plików każdej partycji.
- Tabela do partycjonowania.
W poniższym przykładzie pokazano, jak utworzyć funkcję partycji dla 1 stycznia 2021 r. do 1 grudnia 2021 r. i dystrybuować partycje w różnych grupach plików.
-- Partition function
CREATE PARTITION FUNCTION PartitionByMonth (datetime2)
AS RANGE RIGHT
-- The boundary values defined is the first day of each month, where the table will be partitioned into 13 partitions
FOR VALUES ('20210101', '20210201', '20210301',
'20210401', '20210501', '20210601', '20210701',
'20210801', '20210901', '20211001', '20211101',
'20211201');
-- The partition scheme below will use the partition function created above, and assign each partition to a specific filegroup.
CREATE PARTITION SCHEME PartitionByMonthSch
AS PARTITION PartitionByMonth
TO (FILEGROUP1, FILEGROUP2, FILEGROUP3, FILEGROUP4,
FILEGROUP5, FILEGROUP6, FILEGROUP7, FILEGROUP8,
FILEGROUP9, FILEGROUP10, FILEGROUP11, FILEGROUP12);
-- Creates a partitioned table called Order that applies PartitionByMonthSch partition scheme to partition the OrderDate column
CREATE TABLE Order ([Id] int PRIMARY KEY, OrderDate datetime2)
ON PartitionByMonthSch (OrderDate) ;
GO
Kompresja danych
Program SQL Server oferuje różne opcje kompresji danych. Podczas gdy program SQL Server nadal przechowuje skompresowane dane na 8 KB stron, gdy dane są kompresowane, więcej wierszy danych można przechowywać na danej stronie, co umożliwia zapytaniu odczytywanie mniejszej liczby stron. Odczytywanie mniejszej liczby stron ma podwójną korzyść: zmniejsza ilość wykonywanych operacji we/wy fizycznych i umożliwia przechowywanie większej liczby wierszy w puli, dzięki czemu bardziej wydajne wykorzystanie pamięci. W razie potrzeby zalecamy włączenie kompresji strony bazy danych.
Kompromisy związane z kompresją są to, że wymaga ona niewielkiej ilości obciążenia procesora CPU, jednak w większości przypadków operacje we/wy magazynu znacznie przewyższają wszelkie dodatkowe użycie procesora.
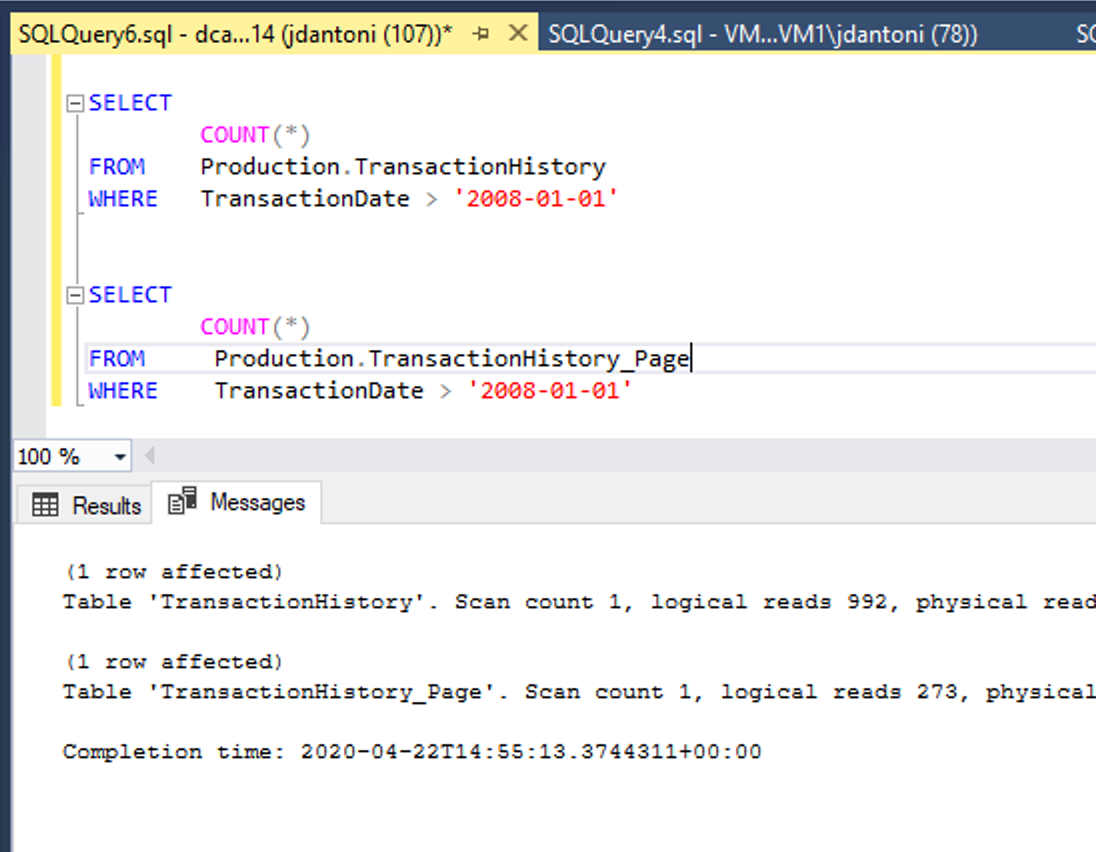
Na powyższym obrazie przedstawiono tę korzyść z wydajności. Te tabele mają te same indeksy bazowe; Jedyną różnicą jest to, że indeksy klastrowane i nieklastrowane w tabeli Production.TransactionHistory_Pagesą kompresowane na stronie. Zapytanie względem skompresowanego obiektu strony wykonuje 72% mniej operacji odczytu logicznego niż zapytanie korzystające z nieskompresowanych obiektów.
Kompresja jest implementowana w programie SQL Server na poziomie obiektu. Każdy indeks lub tabelę można skompresować indywidualnie i można kompresować partycje w tabeli partycjonowanej lub indeksie. Możesz ocenić ilość miejsca, które zaoszczędzisz, korzystając z procedury składowanej systemu sp_estimate_data_compression_savings. Przed programem SQL Server 2019 ta procedura nie obsługiwała indeksów magazynu kolumn ani kompresji archiwalnej magazynu kolumn.
Kompresja wierszy — kompresja wierszy jest dość podstawowa i nie wiąże się z dużym obciążeniem, jednak nie oferuje takiej samej ilości kompresji (mierzonej procentowo zmniejszenie ilości wymaganego miejsca do magazynowania), że kompresja strony może zaoferować. Kompresja wierszy zasadniczo przechowuje każdą wartość w każdej kolumnie w wierszu w minimalnej ilości miejsca potrzebnego do przechowywania tej wartości. Używa formatu magazynu o zmiennej długości dla typów danych liczbowych, takich jak liczba całkowita, zmiennoprzecinkowa i dziesiętna, i przechowuje ciągi znaków o stałej długości przy użyciu formatu zmiennej długości.
Kompresja strony — kompresja strony jest nadzbiorem kompresji wierszy, ponieważ wszystkie strony będą początkowo kompresowane wierszami przed zastosowaniem kompresji strony. Następnie do danych są stosowane kombinacje technik nazywanych prefiksem i kompresją słownika. Kompresja prefiksu eliminuje nadmiarowe dane w jednej kolumnie, przechowując wskaźniki z powrotem do nagłówka strony. Po tym kroku kompresja słownika wyszukuje powtarzające się wartości na stronie i zastępuje je wskaźnikami, co jeszcze bardziej zmniejsza ilość miejsca w magazynie. Im większa nadmiarowość danych, tym większe oszczędności miejsca podczas kompresowania danych.
Kompresja archiwalna magazynu kolumn — obiekty magazynu kolumn są zawsze kompresowane, jednak można je dodatkowo skompresować przy użyciu kompresji archiwalnej, która używa algorytmu kompresji Microsoft XPRESS na danych. Ten typ kompresji jest najlepiej używany w przypadku danych, które są rzadko odczytywane, ale muszą być przechowywane ze względów prawnych lub biznesowych. Chociaż te dane są jeszcze bardziej skompresowane, koszt procesora CPU dekompresji zwykle przewyższa wszelkie wzrosty wydajności z redukcji operacji we/wy.
Opcje dodatkowe
Poniżej znajduje się lista dodatkowych funkcji i akcji programu SQL Server, które należy wziąć pod uwagę w przypadku obciążeń produkcyjnych:
- Włącz kompresję kopii zapasowych
- Włącz natychmiastowe inicjowanie plików dla plików danych
- Ogranicz automatyczne zwiększanie bazy danych
- Wyłączanie autoshrink/autoclose dla baz danych
- Przenoszenie wszystkich baz danych na dyski danych, w tym systemowych baz danych
- Przenoszenie dzienników błędów programu SQL Server i katalogów plików śledzenia na dyski danych
- Ustawianie maksymalnego limitu pamięci programu SQL Server
- Włącz strony blokady w pamięci
- Włączanie optymalizacji pod kątem obciążeń adhoc w środowiskach o dużym obciążeniu OLTP
- Włącz magazyn zapytań.
- Planowanie zadań agenta programu SQL Server w celu uruchamiania zadań DBCC CHECKDB, reorganizacji indeksu, ponownego kompilowania indeksu i aktualizowania statystyk
- Monitorowanie kondycji i rozmiaru plików dziennika transakcji i zarządzanie nimi
Aby uzyskać więcej informacji na temat najlepszych rozwiązań dotyczących wydajności, zobacz Najlepsze rozwiązania dotyczące programu SQL Server na maszynach wirtualnych platformy Azure.