Omówienie pojęć związanych z uczeniem głębokim
W mózgu masz komórki nerwowe zwane neuronami, które są połączone ze sobą przez rozszerzenia nerwowe, które przekazują sygnały elektrochemiczne przez sieć.

Gdy pierwszy neuron w sieci jest stymulowany, sygnał wejściowy jest przetwarzany, a jeśli przekroczy określony próg, neuron jest aktywowany i przekazuje sygnał do neuronów, do których jest podłączony. Te neurony z kolei mogą być aktywowane i przekazywać sygnał przez pozostałą część sieci. W miarę upływu czasu połączenia między neuronami są wzmacniane przez częste stosowanie, gdy nauczysz się skutecznie reagować. Jeśli na przykład pokazano obraz pingwina, twoje połączenia neuronowe umożliwiają przetwarzanie informacji na obrazie i znajomość cech pingwina w celu zidentyfikowania go jako takiego. W miarę upływu czasu, jeśli pokazano wiele zdjęć różnych zwierząt, sieć neuronów zaangażowanych w identyfikację zwierząt na podstawie ich cech rośnie silniejszy. Innymi słowy, lepiej jest dokładnie identyfikować różne zwierzęta.
Uczenie głębokie emuluje ten proces biologiczny przy użyciu sztucznych sieci neuronowych, które przetwarzają dane wejściowe liczbowe, a nie bodźce elektrochemiczne.
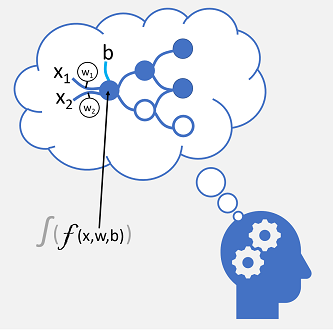
Przychodzące połączenia nerwowe są zastępowane przez dane wejściowe liczbowe, które są zwykle identyfikowane jako x. Jeśli istnieje więcej niż jedna wartość wejściowa, x jest traktowana jako wektor z elementami o nazwie x1, x2 itd.
Skojarzona z każdą wartością x jest wagą (w), która służy do wzmacniania lub osłabienia efektu wartości x do symulowania uczenia. Ponadto dodawana jest stronniczość (b), aby umożliwić precyzyjną kontrolę nad siecią. Podczas procesu trenowania wartości w i b są dostosowywane, aby dostroić sieć tak, aby "nauczyła się" generować poprawne dane wyjściowe.
Sam neuron hermetyzuje funkcję, która oblicza ważoną sumę x, w i b. Ta funkcja jest z kolei ujęta w funkcję aktywacji, która ogranicza wynik (często do wartości od 0 do 1), aby określić, czy neuron przekazuje dane wyjściowe do następnej warstwy neuronów w sieci.
Trenowanie modelu uczenia głębokiego
Modele uczenia głębokiego to sieci neuronowe składające się z wielu warstw sztucznych neuronów. Każda warstwa reprezentuje zestaw funkcji wykonywanych na wartościach x ze skojarzonymi wagami i stronniczościami b, a końcowe wyniki warstwy na danych wyjściowych etykiety y, którą przewiduje model. W przypadku modelu klasyfikacji (który przewiduje najbardziej prawdopodobną kategorię lub klasę dla danych wejściowych), dane wyjściowe są wektorem zawierającym prawdopodobieństwo dla każdej możliwej klasy .
Na poniższym diagramie przedstawiono model uczenia głębokiego, który przewiduje klasę jednostki danych na podstawie czterech funkcji (wartości x). Dane wyjściowe modelu ( wartości y ) to prawdopodobieństwo dla każdej z trzech możliwych etykiet klas.
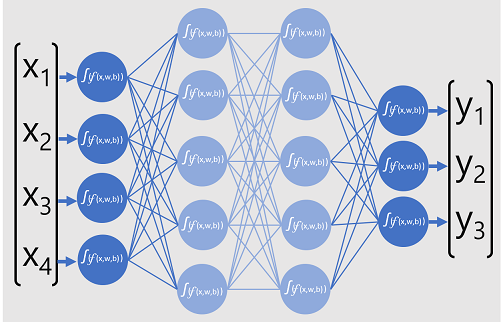
Aby wytrenować model, platforma uczenia głębokiego przesyła wiele partii danych wejściowych (dla których są znane rzeczywiste wartości etykiet), stosuje funkcje we wszystkich warstwach sieciowych i mierzy różnicę między prawdopodobieństwami danych wyjściowych a rzeczywistymi znanymi etykietami klas danych treningowych. Zagregowana różnica między danymi wyjściowymi przewidywania a rzeczywistymi etykietami jest nazywana utratą.
Po obliczeniu zagregowanej utraty dla wszystkich partii danych struktura uczenia głębokiego używa optymalizatora w celu określenia sposobu dostosowania wagi i uprzedzeń w modelu w celu zmniejszenia ogólnej utraty. Te korekty są następnie ponownie propagowane do warstw w modelu sieci neuronowej, a następnie dane są przekazywane przez sieć ponownie, a utrata zostanie ponownie obliczona. Ten proces powtarza się wiele razy (każda iteracja jest znana jako epoka), dopóki strata nie zostanie zminimalizowana, a model "nauczył się" odpowiednich wag i uprzedzeń, aby móc dokładnie przewidzieć.
W każdej epoki wagi i uprzedzenia są dostosowywane, aby zminimalizować utratę. Wartość, przez którą są one dostosowywane, jest określana przez współczynnik uczenia określony dla optymalizatora. Jeśli tempo nauki jest zbyt niskie, proces trenowania może zająć dużo czasu, aby określić optymalne wartości; ale jeśli jest zbyt wysoka, optymalizator nigdy nie może znaleźć optymalnych wartości.