Omówienie składników usługi Azure Data Factory
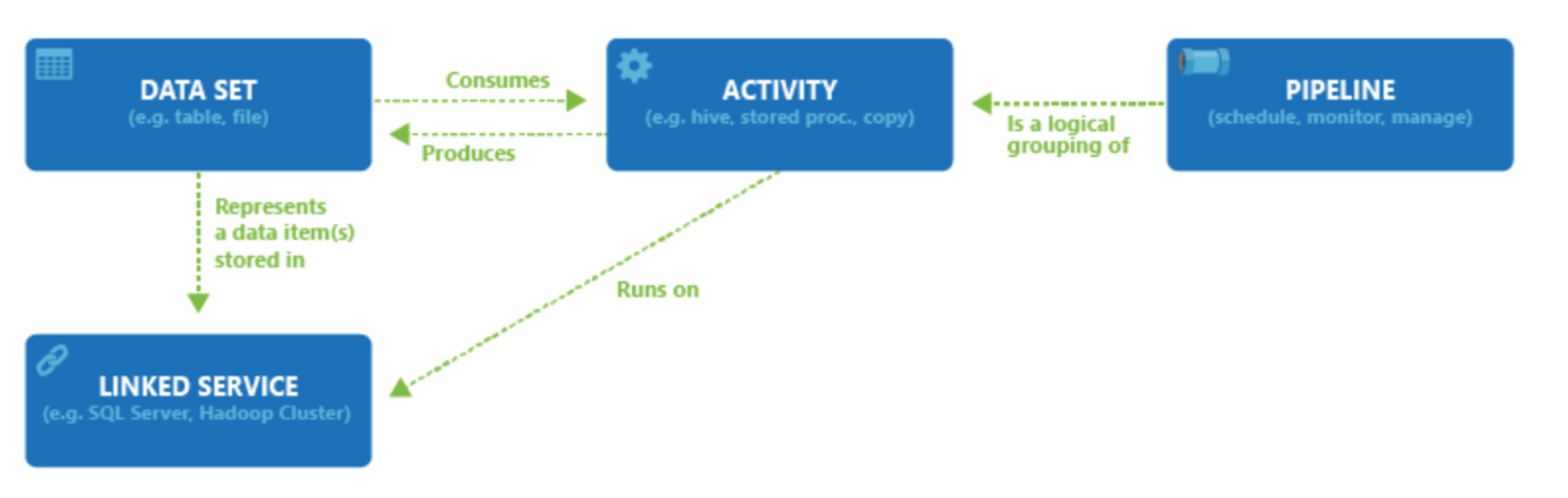
Subskrypcja platformy Azure może mieć co najmniej jedno wystąpienie usługi Azure Data Factory. Usługa Azure Data Factory składa się z czterech podstawowych składników. Ich współdziałanie pozwala udostępnić platformę umożliwiającą tworzenie opartych na danych przepływów pracy wraz z etapami służącymi do przenoszenia i przekształcania danych.
Usługa Data Factory obsługuje szeroką gamę źródeł danych, z którymi można nawiązać połączenie za pośrednictwem tworzenia obiektu znanego jako połączona usługa, co umożliwia pozyskiwanie danych ze źródła danych w gotowości do przygotowania danych do transformacji i/lub analizy. Ponadto połączone usługi mogą uruchamiać usługi obliczeniowe na żądanie. Na przykład może być wymagane uruchomienie klastra usługi HDInsight na żądanie w celu przetwarzania danych za pomocą zapytania Hive. Dlatego połączone usługi umożliwiają definiowanie źródeł danych lub zasobów obliczeniowych wymaganych do pozyskiwania i przygotowywania danych.
Po zdefiniowaniu połączonej usługi usługa Azure Data Factory jest świadoma zestawów danych, których powinna używać za pośrednictwem tworzenia obiektu Zestawy danych. Zestawy danych reprezentują struktury danych w magazynie danych, do którego odwołuje się obiekt Połączona usługa. Zestawy danych mogą być również używane przez obiekt usługi ADF znany jako Działanie.
Działania zwykle zawierają logikę przekształcania lub polecenia analizy pracy usługi Azure Data Factory. Działania obejmują działanie kopiowania, które może służyć do pozyskiwania danych z różnych źródeł danych. Może również zawierać Przepływ danych mapowania w celu wykonania przekształceń danych bez użycia kodu. Może również obejmować wykonywanie procedury składowanej, zapytania Hive lub skryptu pig w celu przekształcenia danych. Możesz wypchnąć dane do modelu uczenia maszynowego w celu przeprowadzenia analizy. Nie jest rzadkością dla wielu działań, które mogą obejmować przekształcanie danych przy użyciu procedury składowanej SQL, a następnie wykonywanie analiz za pomocą usługi Databricks. W takim przypadku wiele działań może być logicznie zgrupowanych razem z obiektem nazywanym potokiem i można je zaplanować do wykonania lub można zdefiniować wyzwalacz, który określa, kiedy należy rozpocząć wykonywanie potoku. Istnieją różne typy wyzwalaczy dla różnych typów zdarzeń.
Przepływ sterowania to aranżacja działań potoku, która obejmuje działania łańcuchowe w sekwencji, rozgałęzianie, definiowanie parametrów na poziomie potoku i przekazywanie argumentów podczas wywoływania potoku na żądanie lub z wyzwalacza. Obejmuje on również kontenery przekazujące i przekazujące w pętli niestandardowe oraz iteratory dla każdego.
Parametry to pary klucz-wartość konfiguracji tylko do odczytu. Parametry są definiowane w potoku. Argumenty dla zdefiniowanych parametrów są przekazywane w trakcie wykonania z kontekstu uruchomienia utworzonego przez wyzwalacz lub potok wykonany ręcznie. Działania w ramach potoku wykorzystują wartości parametrów.
Usługa Azure Data Factory ma środowisko Integration Runtime , które umożliwia mu mostek między obiektami działania i połączonymi usługami. Odwołuje się do niej połączona usługa i zapewnia środowisko obliczeniowe, w którym działanie jest uruchamiane lub z którego jest wysyłane. W ten sposób działanie można wykonać w regionie najbliżej możliwego. Istnieją trzy typy środowiska Integration Runtime, w tym azure, self-hosted i Azure-SSIS.
Po zakończeniu wszystkich prac możesz użyć usługi Data Factory, aby opublikować końcowy zestaw danych w innej połączonej usłudze, która może być następnie używana przez technologie, takie jak Power BI lub Machine Learning.