Informacje o modelu i jego testowanie
Utworzyliśmy model uczenia maszynowego! Przetestujmy go i przyjrzyjmy się, jak dobrze działa.
Wydajność modelu
Usługa Custom Vision wyświetla trzy metryki podczas testowania modelu. Metryki to wskaźniki, które mogą pomóc zrozumieć, jak działa model. Wskaźniki nie wskazują, jak rzeczywisty lub dokładny jest model. Wskaźniki informują tylko o tym, jak model był wykonywany na podanych danych. Jak dobrze model jest wykonywany na znanych danych, daje wyobrażenie o tym, jak model będzie działać na nowych danych.
Dla całego modelu i dla każdej klasy podano następujące metryki:
| Metryczne | opis |
|---|---|
precision |
Jeśli model przewiduje tag, ta metryka wskazuje, jak prawdopodobne jest przewidywanie poprawnego tagu. |
recall |
Spośród tagów, które model powinien prawidłowo przewidzieć, ta metryka wskazuje procent tagów, które model prawidłowo przewidział. |
average precision |
Mierzy wydajność modelu przez obliczenie dokładności i kompletności przy różnych progach. |
Podczas testowania modelu usługi Custom Vision zobaczymy liczby dla każdej z tych metryk w wynikach testu iteracji.
Typowe błędy
Zanim przetestujemy nasz model, rozważmy niektóre błędy "początkujących", które należy obserwować podczas pierwszego rozpoczęcia tworzenia modeli uczenia maszynowego.
Korzystanie z danych niezrównoważonych
To ostrzeżenie może zostać wyświetlone podczas wdrażania modelu:
Unbalanced data detected. The distribution of images per tag should be uniform to ensure model performance.
To ostrzeżenie oznacza, że nie masz parzystej liczby próbek dla każdej klasy danych. Chociaż w tym scenariuszu istnieje wiele opcji, typowym sposobem rozwiązania niezrównoważonego danych jest użycie techniki próbkowania syntetycznej mniejszości (SMOTE). SmOTE duplikuje przykłady trenowania z istniejącej puli szkoleniowej.
Uwaga
W naszym modelu może nie być widoczne to ostrzeżenie, zwłaszcza jeśli przekazano ułamek zestawu danych. Podzestaw danych modelu Red-tailed Hawk (Ciemny morf) zawiera mniej niż 60 zdjęć w porównaniu z innymi modelami, które mają więcej niż 100 zdjęć. Używanie niezrównoważonych danych jest czymś, co należy obserwować w dowolnym modelu uczenia maszynowego.
Nadmierne dopasowanie modelu
Jeśli nie masz wystarczającej ilości danych lub jeśli dane nie są wystarczająco zróżnicowane, model może stać się nadmiernie dopasowany. Gdy model jest nadmiernie dopasowany, dobrze zna podany zestaw danych i jest on nadmiernie dopasowany do wzorców w tych danych. W takim przypadku model działa dobrze na danych treningowych, ale działa źle na nowych danych, których wcześniej nie widział. Z tego powodu zawsze używamy nowych danych do testowania modelu.
Testowanie przy użyciu danych treningowych
Podobnie jak w przypadku nadmiernego dopasowania, jeśli testujesz model przy użyciu tych samych danych, które były używane do trenowania modelu, model wydaje się działać prawidłowo. Jednak podczas wdrażania modelu w środowisku produkcyjnym najprawdopodobniej będzie działać źle.
Używanie nieprawidłowych danych
Innym typowym błędem jest użycie nieprawidłowych danych do wytrenowania modelu. Niektóre dane mogą rzeczywiście zmniejszyć dokładność modelu. Na przykład użycie danych , które są "hałaśliwe", może zmniejszyć dokładność modelu. W hałaśliwych danych zbyt wiele informacji, które nie są przydatne, znajduje się w zestawie danych i powoduje zamieszanie w modelu. Więcej danych jest lepiej tylko wtedy, gdy dane są dobrymi danymi, których może używać model. Może być konieczne wyczyszczenie danych lub usunięcie funkcji w celu zwiększenia dokładności modelu.
Testowanie modelu
Zgodnie z metrykami, które udostępnia usługa Custom Vision, nasz model działa na zadowalającym poziomie. Przetestujmy go i zobaczmy, jak działa na danych, których jeszcze nie zna. Użyjemy obrazu ptaka z wyszukiwania w Internecie.
W przeglądarce internetowej wyszukaj obraz ptaka pasujący do jednego z gatunków, które wytrenowane model został rozpoznany. Skopiuj adres URL obrazu.
W portalu Custom Vision wybierz projekt Klasyfikacja ptaków.
Na górnym pasku menu wybierz pozycję Szybki test.
W obszarze Szybki test wklej adres URL w polu Adres URL obrazu, a następnie naciśnij Enter, aby przetestować dokładność modelu. Prognoza jest wyświetlana w oknie.
Usługa Custom Vision analizuje obraz w celu przetestowania dokładności modelu i wyświetla wyniki:
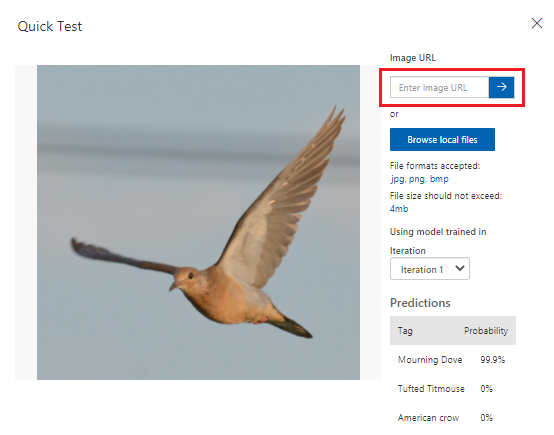
W następnym kroku zostanie wdrożony model. Po wdrożeniu modelu możemy przeprowadzić więcej testów za pomocą punktu końcowego, który utworzymy.