Ćwiczenie — wykonywanie zapytań w klastrze platformy Spark w usłudze HDInsight
W tym ćwiczeniu dowiesz się, jak utworzyć ramkę danych na podstawie pliku CSV i jak uruchamiać interakcyjne zapytania Spark SQL względem klastra Apache Spark w usłudze Azure HDInsight. Na platformie Spark ramka danych jest rozproszoną kolekcją danych zorganizowanych w nazwanych kolumnach. Ramka danych jest koncepcyjnie równoważna tabeli w relacyjnej bazie danych lub ramce danych w języku R/Python.
Z tego samouczka dowiesz się, jak wykonywać następujące czynności:
- Tworzenie ramki danych z pliku csv
- Uruchamianie zapytań na ramce danych
Tworzenie ramki danych z pliku csv
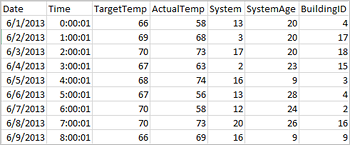
Poniższy przykładowy plik CSV zawiera informacje o temperaturze budynku i jest przechowywany w systemie plików klastra Spark.
Wklej następujący kod w pustej komórce notesu Jupyter, a następnie naciśnij SHIFT + ENTER, aby uruchomić kod. Kod importuje typy wymagane w tym scenariuszu
from pyspark.sql import * from pyspark.sql. types import *Podczas uruchamiania interakcyjnego zapytania w programie Jupyter w oknie przeglądarki internetowej lub w tytule karty wyświetlany jest stan (Busy) (Zajęty) wraz z tytułem notesu. Widoczne jest także pełne kółko obok tekstu PySpark w prawym górnym rogu. Po zakończeniu zadania zmienia się ono w pusty okrąg.
Uruchom następujący kod, aby utworzyć ramkę danych i tabelę tymczasową (hvac).
# Create a dataframe and table from sample data csvFile = spark.read.csv ('/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv', header=True, inferSchema=True) csvFile.write. saveAsTable("hvac")
Uruchamianie zapytań na ramce danych
Po utworzeniu tabeli możesz uruchomić interakcyjne zapytanie na danych.
W pustej komórce notesu uruchom następujący kod:
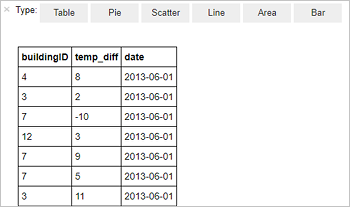
%%sql SELECT buildingID, (targettemp - actualtemp) AS temp_diff, date FROM hvac WHERE date = \"6/1/13\"Zostanie wyświetlona następująca tabela danych wyjściowych.
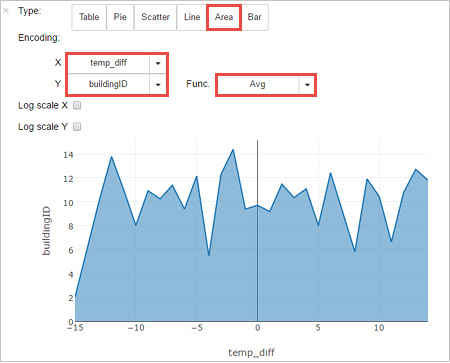
Wyniki można również przeglądać w postaci innych wizualizacji. Aby wyświetlić wykres warstwowy dla tych samych danych wyjściowych, wybierz pozycję Area (Obszar), a następnie ustaw inne wartości, jak pokazano poniżej.
Na pasku menu notesu przejdź do pozycji Plik > Zapisz i Punkt kontrolny.
Zamknij notes, aby zwolnić zasoby klastra: na pasku menu notesu przejdź do pozycji Zamknij plik > i zatrzymaj.