Tworzenie klastra usługi HDInsight
Istnieją różne metody tworzenia klastra usługi HDInsight. Może to obejmować korzystanie z witryny Azure Portal w celu łatwego interfejsu użytkownika po skryptowe konfiguracje, które mogą pomóc w zautomatyzowanych wdrożeniach. W poniższej tabeli przedstawiono różne metody, których można użyć do skonfigurowania klastra usługi HDInsight.
| Klastry utworzone za pomocą polecenia | Przeglądarka sieci Web | Wiersz polecenia | Interfejs API REST | SDK |
|---|---|---|---|---|
| Azure Portal | ✔ | |||
| Azure Data Factory | ✔ | ✔ | ✔ | ✔ |
| Interfejs wiersza polecenia platformy Azure | ✔ | |||
| Azure PowerShell | ✔ | |||
| cURL | ✔ | ✔ | ||
| Zestaw SDK platformy .NET | ✔ | |||
| Szablon usługi Azure Resource Manager | ✔ |
Wszystkie konfiguracje usługi HDInsight wymagają następujących podstawowych informacji, w tym:
Karta Podstawowe
Szczegóły projektu
Subskrypcja
Definiuje subskrypcję platformy Azure, w ramach której będą naliczane opłaty za usługę HDInsight i zarządzane.
Nazwa grupy zasobów
Grupa zasobów to logiczne grupowanie technologii i usług platformy Azure, które zwykle odnoszą się do tej samej aplikacji lub cyklu życia aplikacji. Grupowanie usług w tej samej grupie zasobów ułatwia konserwację administracyjną.
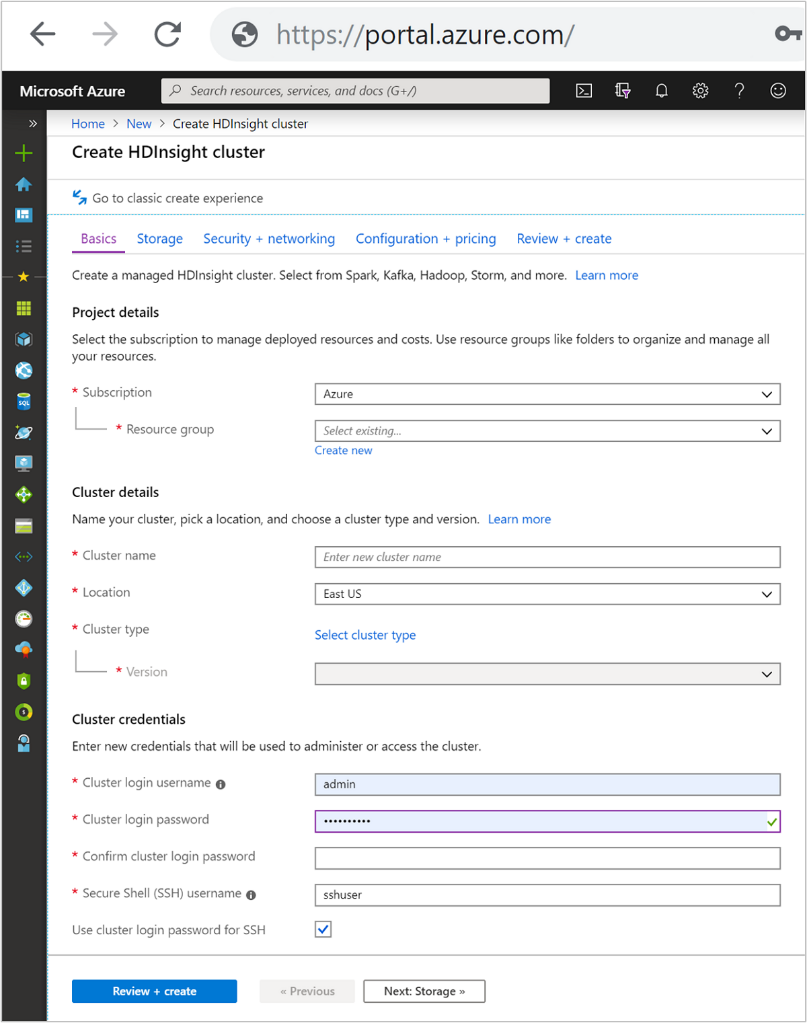
Szczegóły klastra
Nazwa klastra
Nazwy klastrów usługi HDInsight mają następujące ograniczenia:
- Dozwolone znaki: a-z, 0-9, A-Z
- Maksymalna długość: 59
- Nazwy zarezerwowane: aplikacje
- Zakres nazewnictwa klastra dotyczy całej platformy Azure we wszystkich subskrypcjach. Dlatego nazwa klastra musi być unikatowa na całym świecie.
- Pierwsze sześć znaków musi być unikatowe w sieci wirtualnej
Lokalizacja
Określa lokalizację, w której jest przechowywany typ klastra. Jeśli żadna lokalizacja nie jest zdefiniowana, klaster jest kolokowany w tej samej lokalizacji co magazyn domyślny. Lokalizacja powinna być jak najbliżej użytkowników, aby zmniejszyć opóźnienie.
Typy klastrów
Definiuje stos technologii aprowizowany w klastrze zasobów. Wybierz typ klastra na podstawie typu posiadanych danych i wymaganego rodzaju przetwarzania scenariusza. Dostępne typy klastrów przedstawione w poniższej tabeli.
| Typ klastra | Opis |
|---|---|
| Apache Hadoop | Struktura korzystająca z systemu plików HDFS i prostego modelu programowania MapReduce do przetwarzania i analizowania danych wsadowych. |
| Apache Spark | platforma przetwarzania równoległego typu „open source”, która obsługuje przetwarzanie w pamięci umożliwiające zwiększenie wydajności aplikacji do analizy danych big data. |
| HBase | baza danych NoSQL oparta na platformie Hadoop, która zapewnia dostęp losowy i wysoki poziom spójności w przypadku dużych ilości nieustrukturyzowanych i częściowo ustrukturyzowanych danych — potencjalnie miliardów wierszy pomnożonych przez miliony kolumn. |
| Zapytanie interakcyjne Apache | pamięć podręczna w pamięci do interaktywnego i szybszego wykonywania zapytań programu Hive. |
| Apache Kafka | platforma typu „open source”, która służy do tworzenia potoków danych przesyłanych strumieniowo i aplikacji do obsługi tych danych. Platforma Kafka obejmuje również funkcję kolejki komunikatów, która umożliwia publikowanie i subskrybowanie strumieni danych. |
Wersja
Definiuje wersję usługi HDInsight dla tego klastra. Usługa HDInsight 4.0 jest najnowszą wersją i ma najnowsze struktury aprowidowane w klastrach.
Poświadczenia klastra
Za pomocą klastrów usługi HDInsight można skonfigurować dwa konta użytkowników podczas tworzenia klastra.
Nazwa logowania i hasło klastra
Domyślna nazwa użytkownika to administrator. Używa on podstawowej konfiguracji w witrynie Azure Portal. Czasami jest to nazywane "użytkownikiem klastra".
Nazwa użytkownika i hasło protokołu SSH
Służy do nawiązywania połączenia z klastrem za pośrednictwem protokołu SSH.
Uwaga
Pakiet zabezpieczeń przedsiębiorstwa umożliwia integrację usługi HDInsight z usługami Active Directory i Apache Ranger. Wielu użytkowników można utworzyć przy użyciu pakietu Enterprise Security.
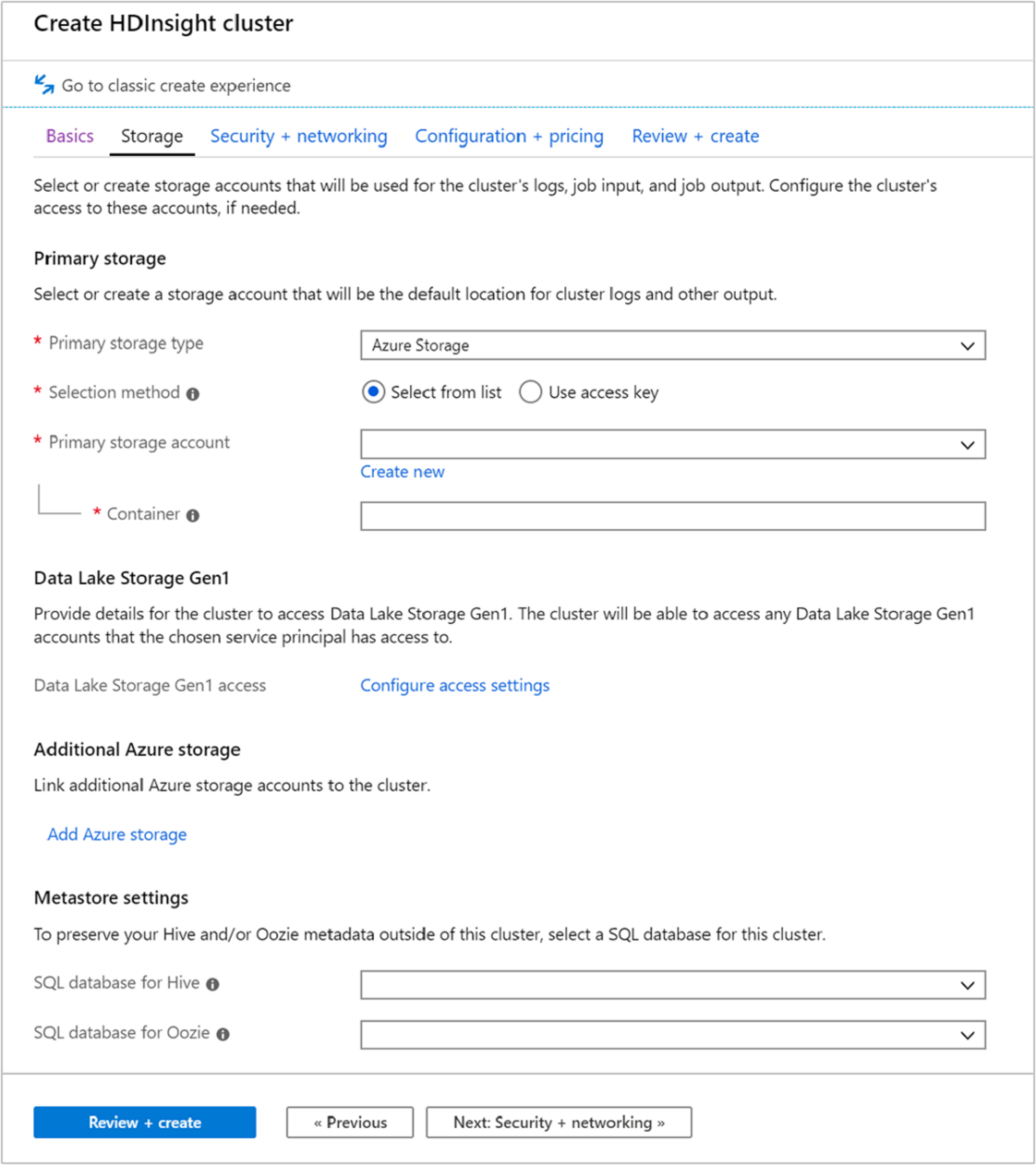
Karta Magazyn
Klastry usługi HDInsight mogą używać następujących opcji magazynu, jak pokazano na ekranie magazynu:
- Azure Data Lake Storage Gen2
- Usługa Azure Data Lake Storage 1. generacji
- Ogólnego przeznaczenia usługi Azure Storage w wersji 2
- Ogólnego przeznaczenia usługi Azure Storage w wersji 1
- Blokowy obiekt blob usługi Azure Storage (obsługiwany tylko jako magazyn pomocniczy)
Ekran magazynu umożliwia zdefiniowanie podstawowego konta magazynu i domyślnego kontenera. Możesz również połączyć dodatkową usługę Azure Storage z klastrem. Ustawienia magazynu metadanych umożliwiają zdefiniowanie zewnętrznej bazy danych SQL do przechowywania tabel programu Hive po usunięciu klastra oraz zwiększenie wydajności usługi Oozie przez przechowywanie metadanych w magazynie zewnętrznym.
Zabezpieczenia i sieć
W przypadku typów klastrów Hadoop, Spark, HBase, Kafka i Interactive Query można włączyć pakiet Enterprise Security. Ten pakiet zapewnia opcję bardziej bezpiecznej konfiguracji klastra przy użyciu platformy Apache Ranger i integracji z identyfikatorem Entra firmy Microsoft.
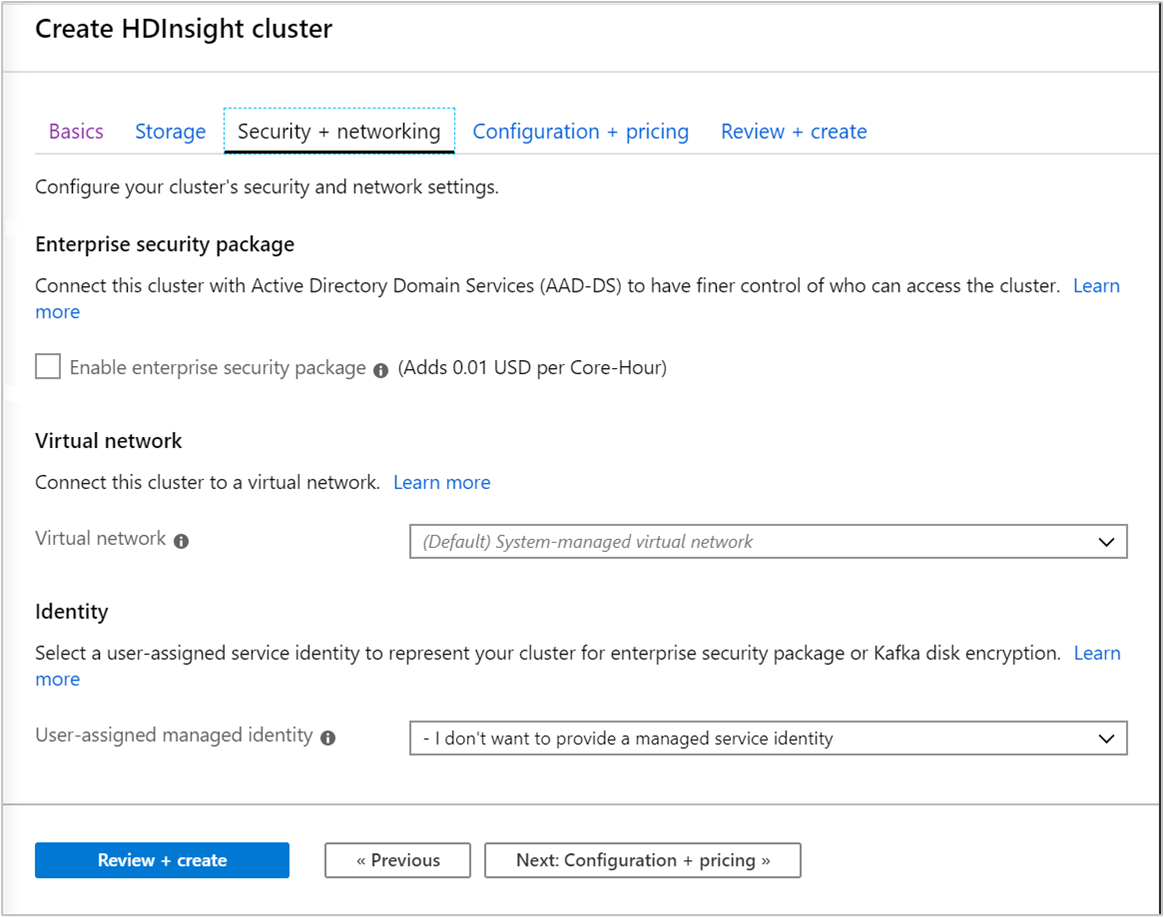
Ponadto zawsze zaleca się wdrażanie klastrów usługi HDInsight w sieci wirtualnej i definiowanie i ustawianie sieci wirtualnej na tym ekranie. Jeśli twoje rozwiązanie wymaga technologii, które są rozmieszczone w wielu typach klastrów usługi HDInsight, sieć wirtualna platformy Azure może połączyć wymagane typy klastrów. Ta konfiguracja umożliwia klastrom i wszystkim wdrażanemu w nich kodowi bezpośrednie komunikowanie się ze sobą.
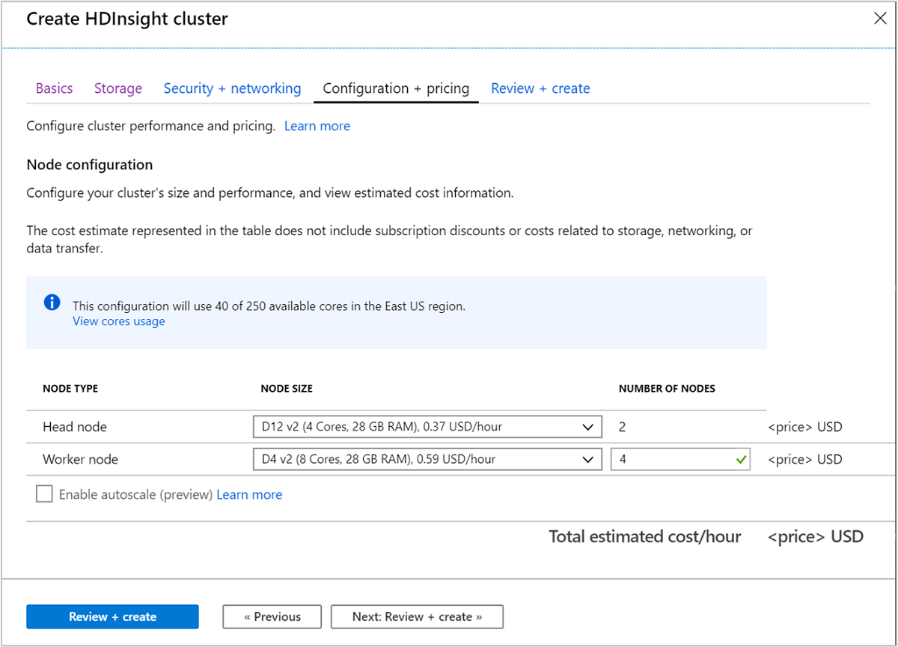
Konfiguracja i cennik
Ta strona umożliwia skonfigurowanie rozmiaru i wydajności klastra oraz wyświetlenie szacowanych informacji o kosztach. Na tym ekranie można zdefiniować maszyny wirtualne, które będą używane dla węzłów głównych (głównych) i węzłów roboczych.