Korzystanie z interfejsu API zamiany tekstu na mowę
Podobnie jak w przypadku interfejsów API zamiany mowy na tekst usługa Azure AI Speech oferuje inne interfejsy API REST do syntezy mowy:
- Interfejs API zamiany tekstu na mowę , który jest podstawowym sposobem wykonywania syntezy mowy.
- Interfejs API syntezy usługi Batch, który jest przeznaczony do obsługi operacji wsadowych, które konwertują duże ilości tekstu na dźwięk — na przykład w celu wygenerowania książki audio na podstawie tekstu źródłowego.
Więcej informacji na temat interfejsów API REST można uzyskać w dokumentacji interfejsu API REST zamiany tekstu na mowę. W praktyce większość interakcyjnych aplikacji obsługujących mowę korzysta z usługi Rozpoznawanie mowy azure AI za pomocą zestawu SDK specyficznego dla języka (programowania).
Korzystanie z zestawu Azure AI Speech SDK
Podobnie jak w przypadku rozpoznawania mowy, w praktyce większość interaktywnych aplikacji z obsługą mowy jest kompilowana przy użyciu zestawu SDK usługi Mowa azure AI.
Wzorzec implementowania syntezy mowy jest podobny do wzorca rozpoznawania mowy:
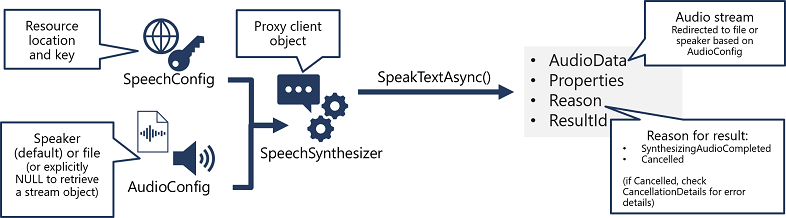
- Użyj obiektu SpeechConfig, aby hermetyzować informacje wymagane do nawiązania połączenia z zasobem usługi Mowa usługi Azure AI. W szczególności jego lokalizacja i klucz.
- Opcjonalnie użyj polecenia AudioConfig , aby zdefiniować urządzenie wyjściowe dla mowy, które ma być syntetyzowane. Domyślnie jest to domyślny głośnik systemowy, ale można również określić plik audio lub jawnie ustawiając tę wartość na wartość null, można przetworzyć obiekt strumienia audio zwracany bezpośrednio.
- Użyj funkcji SpeechConfig i AudioConfig, aby utworzyć obiekt SpeechSynthesizer. Ten obiekt jest klientem proxy interfejsu API zamiany tekstu na mowę .
- Użyj metod obiektu SpeechSynthesizer , aby wywołać podstawowe funkcje interfejsu API. Na przykład metoda SpeakTextAsync() używa usługi Azure AI Speech do konwertowania tekstu na dźwięk mówiony.
- Przetwórz odpowiedź z usługi Azure AI Speech. W przypadku metody SpeakTextAsync wynik jest obiektem SpeechSynthesisResult zawierającym następujące właściwości:
- AudioData
- Właściwości
- Przyczyna
- ResultId
Po pomyślnym zsyntetyzowaniu mowy właściwość Reason jest ustawiona na wyliczenie SynthesizingAudioCompleted , a właściwość AudioData zawiera strumień audio (który w zależności od konfiguracji AudioConfig mógł zostać automatycznie wysłany do osoby mówiącej lub pliku).