Ćwiczenie — monitorowanie stanu pipeline'u
W tym ćwiczeniu zapoznasz się z funkcjami analizy oferowanymi przez usługę Azure Pipelines.
Irwin zapytał zespół Tailspin o to, jak mogą wydać szybciej. Tworzenie zautomatyzowanego potoku wydania to doskonały krok w kierunku szybkiego i niezawodnego wydawania. W miarę częstszego i szybszego wydawania ważne jest zrozumienie stanu i historii wydań. Regularne analizowanie trendów kondycji może pomóc w zdiagnozowaniu potencjalnych problemów, zanim staną się krytyczne.
Zanim przyjrzymy się analizom pipeline'u, posłuchajmy może zespołu Tailspin na ich porannym spotkaniu.
Jak mogę śledzić kondycję potoku?
Jest następny poranek. Na spotkaniu zespołu Andy i Mara zakończyli demonstrację skonfigurowanego potoku kompilacji i wydania.
Amita: To fantastyczne! Potok kompilacji był świetnym początkiem, ale nadal musiałem ręcznie zainstalować artefakt kompilacji w laboratorium, abym mógł go przetestować. Jeśli mogę pobrać te wersje do mojego środowiska testowego zgodnie z regularnym harmonogramem, mogę znacznie szybciej przenosić nowe funkcje za pośrednictwem kontroli jakości.
Mara: dokładnie! Pamiętaj, że zawsze możemy rozszerzyć potok wydania, aby uwzględnić więcej etapów. Celem jest utworzenie kompletnego przepływu pracy wdrażania.
Tim: Środowisko przejściowe byłoby świetne. Mógłbym zrobić więcej testów obciążeniowych, zanim przedstawimy nowe funkcje kierownictwu do ostatecznego zatwierdzenia.
Zespół jest podekscytowany, aby zobaczyć, co może zrobić nowy potok. Wszyscy zaczynają mówić w tym samym czasie.
Andy: jestem też podekscytowany. Jednak skoncentrujmy się na jednym kroku naraz. Tak, myślę, że możemy wprowadzić wszystkie te zmiany i nie tylko, ale jest to tylko dowód koncepcji. Będziemy pracować nad rozszerzeniem go w czasie.
Amita: Jak śledzić kondycję potoków dostarczania?
Andy: Pamiętasz pulpit nawigacyjny, który stworzyliśmy do monitorowania kondycji kompilacji? Możemy skonfigurować ten sam rodzaj systemu dla naszych wydań.
Tim: Irwinowi się to spodoba.
Andy: Wstrzymajmy tworzenie pulpitu wydania, dopóki nie będziemy mieć pełnego przepływu pracy dotyczącego wydania. Na razie przyjrzyjmy się niektórym wbudowanym analizom zapewnianym przez usługę Azure Pipelines.
Zespół zbiera się wokół laptopa Andy'ego.
Jakie informacje zapewnia analiza potoku?
Każdy potok generuje raporty zawierające metryki, trendy i szczegółowe informacje. Te raporty mogą pomóc w zwiększeniu wydajności przepływu.
Raporty obejmują:
- Ogólny wskaźnik zdawalności twojego potoku.
- Wskaźnik zdawalności jakichkolwiek testów w twoim potoku.
- Średni czas trwania przebiegów potoku; w tym zadania kompilacji, które zajmują jak najwięcej czasu na ukończenie.
Oto przykładowy raport przedstawiający niepowodzenia w potoku, błędy testów i czas trwania potoku.
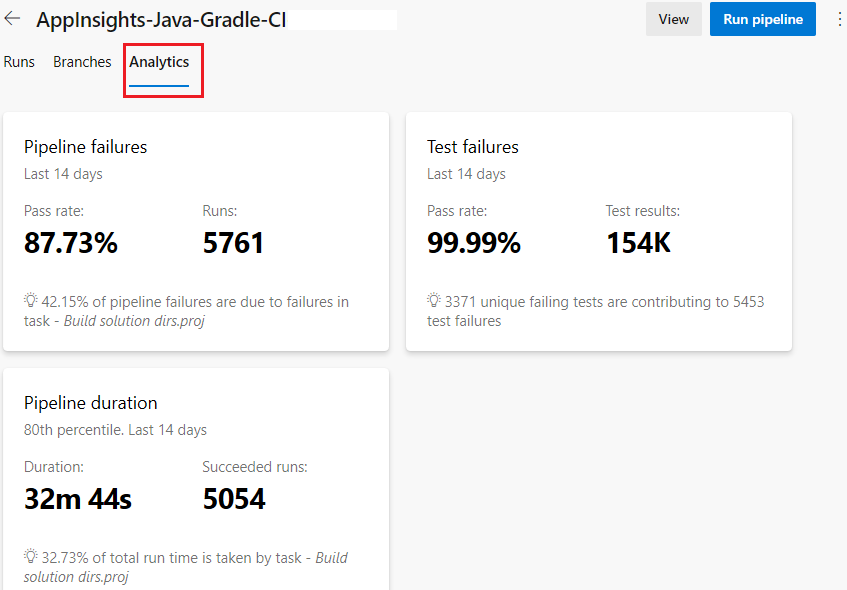
Możesz filtrować wyniki, aby skoncentrować się na określonym przedziale czasu lub na ogólnej aktywności gałęzi usługi GitHub. Usługa Azure DevOps udostępnia również te informacje jako źródło danych OData. Ten kanał informacyjny umożliwia publikowanie raportów i powiadomień w systemach, takich jak Power BI, Microsoft Teams lub Slack. Na końcu tego modułu możesz dowiedzieć się więcej na temat źródeł danych analitycznych.
Przeglądaj analizy potoku danych
W usłudze Azure DevOps wybierz opcję Pipelines, a następnie wybierz swój pipeline.
Wybierz kartę Analytics.

Przejrzyj współczynniki przekazywania i średni czas trwania przebiegów potoku.
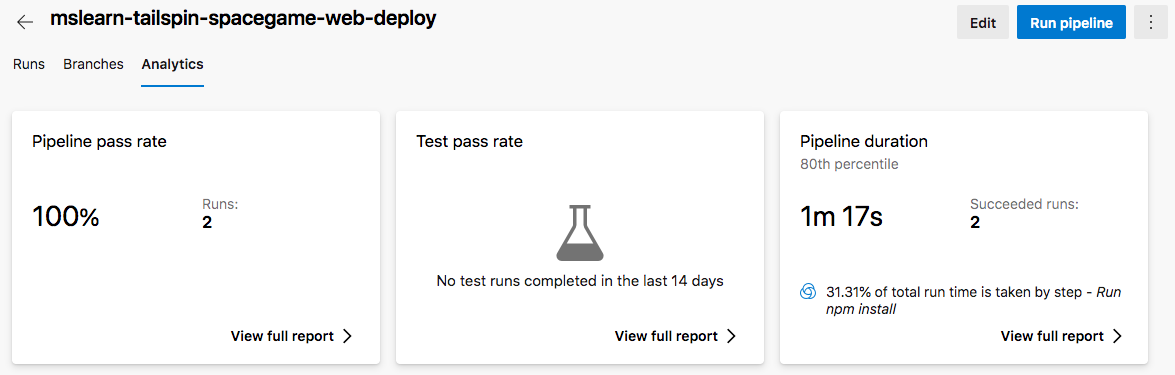
W sekcji wskaźnik zakończenia potokuwybierz opcję Pokaż pełny raport, aby zobaczyć szczegółowy raport.
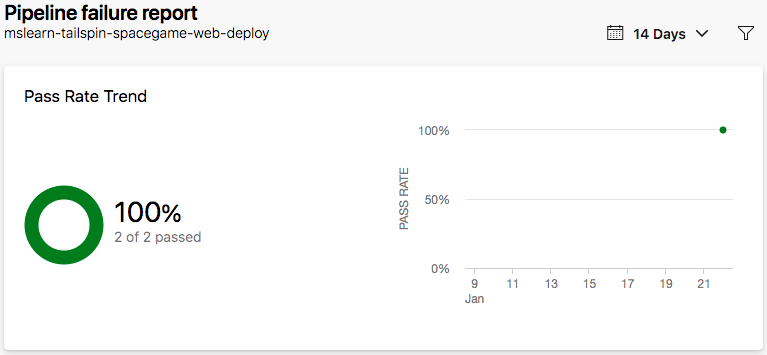
Amita: To są informacje, które chcę, ale nie widzę jeszcze wielu danych.
Andy: To prawda. Będziemy zbierać więcej danych, w miarę jak z czasem będziemy wykonywać kolejne przebiegi. Użyjemy tych danych, aby uzyskać szczegółowe informacje i dowiedzieć się, jak możemy uczynić je bardziej wydajnymi.
Mara: widzę, że zadanie npm install trwa najdłużej. Być może możemy przyspieszyć jego działanie, buforując pakiety npm.
Andy: To świetny pomysł! Możemy to dokładniej zbadać, gdy będziemy mieli więcej przebiegów procesów przetwarzania danych.