Odporność w projekcie i zasadach
Fraza, która prawdopodobnie usłyszy najczęściej w połączeniu z "odzyskiwaniem po awarii", to "ciągłość działalności biznesowej". Ciągłość ma pozytywną konotację. Mówi o ideale ograniczenia zakresu awarii, lub nawet jakiegoś mniejszego zdarzenia, do ścian centrum danych.
Jednak „ciągłość” nie jest terminem inżynieryjnym, pomimo wysiłków, aby ją takim uczynić. Nie ma jednej formuły, metodologii czy instrukcji zapewniającej ciągłość działania. Każda organizacja może mieć własny, unikatowy zestaw najlepszych rozwiązań, które odnoszą się do typu działalności i sposobu jej prowadzenia. Ciągłość to pomyślne zastosowanie tych rozwiązań w celu uzyskania pozytywnego wyniku.
Znaczenie odporności
Inżynierowie rozumieją pojęcie odporności. Jeśli system działa prawidłowo w zmieniających się okolicznościach, jest uważany za odporny. Menedżer ds. ryzyka uzna, że firma jest dobrze przygotowana, jeśli zaimplementuje ona zabezpieczenia przed błędami, środki bezpieczeństwa i procedury awaryjne gotowe do zareagowania na wszelkie negatywne wpływy, których może doświadczyć. Inżynier może nie postrzegać środowiska, w którym system działa w takich czarno-białych kategoriach, "normalny" i "zagrożony", "bezpieczeństwo" i "katastrofa". Ta osoba postrzega system, który obsługuje firmę w odpowiedniej kolejności działania, gdy zapewnia ciągłe i przewidywalne poziomy usług w obliczu niekorzystnych okoliczności.
W 2011 r., podobnie jak przetwarzanie w chmurze stało się rosnącym trendem w centrum danych, Europejską Agencją Sieci i Bezpieczeństwa Informacji (ANDREW, jednostką Unii Europejskiej) wydało sprawozdanie w odpowiedzi na wniosek rządu UE o wgląd w odporność systemów używanych do zbierania i zbierania informacji. W raporcie stwierdzono otwarcie, że wśród personelu informatycznego nie ma jeszcze zgody co do tego, co tak naprawdę oznacza „odporność” ani jak można ją mierzyć.
Doprowadziło to DO odkrycia projektu rozpoczętego przez zespół naukowców z University of Kansas (KU), prowadzonego przez prof. Jamesa P. G. Sterbenza, z zamiarem wdrożenia w Us Dept of Defense. Nazywa się on Resilient and Survivable Networking Initiative (ResiliNets)1 i jest to metoda wizualizacji zmieniającego się stanu odporności w systemach informacyjnych w różnorodnych sytuacjach. ResiliNets to prototyp modelu konsensusu dotyczącego zasad odporności w organizacjach.
Model uniwersytetu KU wykorzystuje wiele znanych i łatwych do objaśnienia metryk, z których część została już przedstawiona w tym rozdziale. To na przykład:
Odporność na uszkodzenia — jak wyjaśniono wcześniej, zdolność systemu do utrzymania oczekiwanych poziomów usług w przypadku wystąpienia błędów
Odporność na zakłócenia — zdolność tego samego systemu do utrzymania oczekiwanych poziomów usług w przypadku wystąpienia nieprzewidywalnych i często ekstremalnych okoliczności operacyjnych, które nie są spowodowane przez sam system — takich jak awarie sieci elektrycznej, brak przepustowości internetowej i skoki w nasileniu ruchu
Przetrwalność — oszacowanie zdolności systemu do zapewnienia rozsądnych, jeśli nie zawsze nominalnych, poziomów wydajności usług we wszystkich możliwych sytuacjach, w tym w przypadku klęsk żywiołowych
Kluczową teorią wysuniętą przez zespół ResiliNets jest to, że systemy informatyczne są o wiele bardziej odporne, jeśli połączymy inżynierię systemu i wysiłki człowieka. To, co robią ludzie — a raczej bardziej to, co kontynuują w ramach codziennych działań — sprawia, że systemy są silniejsze.
Biorąc pod uwagę, jak żołnierze, marynarze i marines w aktywnym teatrze operacji uczą się i pamiętają zasady taktycznego wdrażania, zespół KU zaproponował back-of-the-serwetek mnemonic do zapamiętania cyklu życia praktyki ResiliNets: D2 R 2 +DR. Jak przedstawiono na rysunku 9, te zmienne oznaczają, co następuje (w przedstawionej kolejności):**
Defend czyli „Ochraniaj” system przed zagrożeniami, aby zapewnić jego normalne działanie
Detect czyli „Wykrywaj” wystąpienia niekorzystnych efektów możliwych błędów oraz okoliczności zewnętrznych
Remediate czyli „Koryguj” dalszy wpływ tych efektów na system, nawet jeśli ten wpływ nie został jeszcze podtrzymany
Recover czyli „Odzyskaj” normalne poziomy usług
Diagnose czyli „Zdiagnozuj” główną przyczynę zdarzeń
Refine czyli „Dopracuj” przyszłe zachowania, aby lepiej przygotować się na ponowne wystąpienie tych zdarzeń
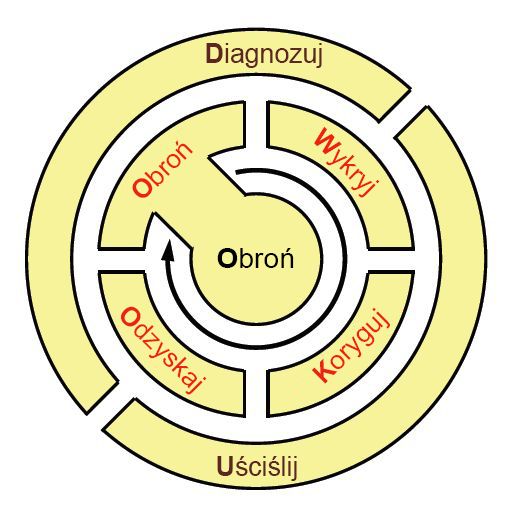
Rysunek 9. Cykl życia działań dotyczących najlepszych rozwiązań w środowisku korzystającym z usługi ResiliNets.
Na każdym z tych etapów uzyskiwane są pewne metryki dotyczące wydajności i działania, zarówno dla osób, jak i systemów. Połączenie tych metryk daje punkty, które można przedstawić na wykresie (jak na rysunku 9.10), używając płaszczyzny euklidesowej. Każda metryka może zostać zredukowana do dwóch jednowymiarowych wartości: jednej, która odzwierciedla parametry poziomu usługi P, a druga reprezentująca stan operacyjny N. Ponieważ wszystkie sześć etapów cyklu ResiliNets jest implementowane i powtarzane, stan usługi S jest wykreśliny na wykresie o współrzędnych (N, P).
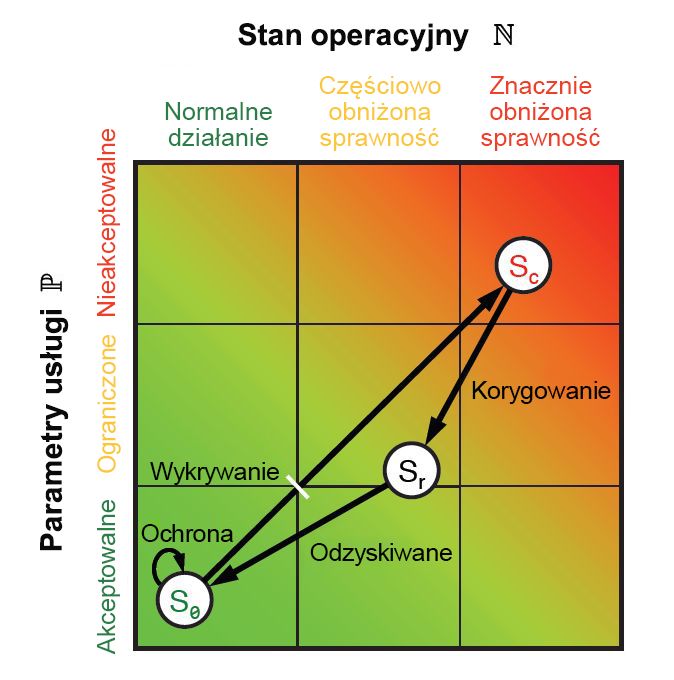
Rysunek 10. Przestrzeń stanu i pętla wewnętrzna strategii ResiliNets.
Stan S organizacji, która spełnia swoje cele usługi, będzie znajdować się blisko lewego dolnego rogu wykresu, i będzie tam pozostawać w czasie trwania tak zwanej pętli wewnętrznej. Gdy cele usługi będą się obniżać, stan będzie się przesuwać wzdłuż niepożądanego wektora w kierunku prawego górnego rogu.
Mimo że model ResiliNets nie stał się powszechnie przyjętym obrazem odporności informatycznej w przedsiębiorstwie, jego wdrożenie przez niektóre ważne organizacje, szczególnie w sektorze publicznym, wyzwoliło pewne zmiany, które stały się katalizatorem rewolucji w chmurze:
Wizualizacja wydajności. Odporność nie musi być filozofią, aby jej obecny stan został przekazany odpowiednim zainteresowanym stronom. W rzeczywistości można ją przedstawić przy użyciu mniej niż jednego słowa. Nowoczesne platformy do zarządzania wydajnością, które uwzględniają metryki z chmury, mają wbudowane pulpity nawigacyjne i podobne narzędzia, dzięki którym ich argumenty są równie skuteczne.
Środki i procedury odzyskiwania nie muszą czekać na awarię. Starannie i dobrze zaprojektowany system informacyjny, stale obsadzony przez czujnych inżynierów i operatorów, będzie codziennie implementował procedury konserwacyjne, które w niewielkim stopniu (jeśli w ogóle) różnią się od procedur naprawczych w trakcie kryzysu. Na przykład w środowisku odzyskiwania po awarii, które dysponuje rezerwą dynamiczną, korygowanie problemu na poziomie usług może faktycznie stać się automatyczne — główny router po prostu przekierowuje ruch z zagrożonych składników. Innymi słowy, przygotowanie na awarię nie musi oznaczać oczekiwania na wystąpienie awarii.
Systemy informacyjne składają się z ludzi. Automatyzacja może sprawić, że ludzka praca będzie wydajniejsza, a wytwarzane produkty — lepsze. Jednak nie można zastąpić ludzi w systemie zaprojektowanym tak, aby reagował na okoliczności i zmiany w środowisku, których nie da się przewidzieć.
Przetwarzanie zorientowane na odzyskiwanie
ResiliNets to jedna z implementacji koncepcji noszącej nazwę przetwarzania zorientowanego na odzyskiwanie (Recovery-Oriented Computing, ROC), do której wymyślenia przyczyniła się firma Microsoft na przełomie wieków.2 Jej kluczową zasadą było to, że awarie i błędy są odwieczną prawdą w środowisku obliczeniowym. Zamiast spędzania przesadnie dużej ilości czasu na dezynfekcji tego środowiska, bardziej korzystne dla organizacji może być stosowanie rozsądnych środków, które przyczyniają się do zwiększenia jego odporności. Jest to komputerowy odpowiednik wprowadzonej tuż przed końcem dwudziestego wieku radykalnej koncepcji, że ludzie powinni myć ręce kilka razy dziennie.
Odporność w chmurze publicznej
Wszyscy dostawcy usług w chmurze publicznej stosują zasady i struktury odporności, nawet jeśli nie nazywają tego w ten sposób. Jednak platforma w chmurze nie zwiększa odporności centrum danych organizacji, jeśli nie wchłania zasobów informatycznych tej organizacji do chmury w całości. Implementacja chmury hybrydowej jest odporna tylko w takim stopniu, w jakim zapewniają to jej najmniej pracowici administratorzy. Jeśli możemy założyć, że administratorzy dostawcy rozwiązań w chmurze będą sumiennie dbali o odporność (w przeciwnym razie naruszają warunki umowy SLA), zachowanie odporności całego systemu zawsze musi być zadaniem klienta.
Struktura odporności platformy Azure
Międzynarodowe wytyczne dotyczące standardu strategii ciągłości działania noszą nazwę ISO 22301. Podobnie jak w przypadku innych struktur Międzynarodowej Organizacji Normalizacyjnej (ISO), zawierają one wskazówki dotyczące najlepszych rozwiązań i operacji, zgodność z którymi umożliwia organizacji uzyskanie profesjonalnego certyfikatu.
Ta struktura ISO w rzeczywistości nie definiuje ciągłości działania czy, w tym przypadku, odporności. Natomiast określa, co oznacza ciągłość w kontekście danej organizacji. W jej dokumencie przewodnim czytamy: „Organizacja powinna zidentyfikować i wybrać strategie ciągłości działania w oparciu o dane wyjściowe z analizy wpływu na działalność firmy i oceny ryzyka. Strategie ciągłości działalności biznesowej składają się z co najmniej jednego rozwiązania. Nie zawiera on listy tych rozwiązań, które mogą być lub powinny być.3
Rysunek 11 przedstawia wizję firmy Microsoft dotyczącą wieloetapowej implementacji zgodności platformy Azure z normą ISO 22301. Zwróć uwagę na uwzględnienie celów związanych z czasem działania określonych w umowie dotyczącej poziomu usług (SLA). W przypadku klientów, którzy wybierają ten poziom odporności, platforma Azure replikuje wirtualne centra danych w swoich lokalnych strefach dostępności, a następnie aprowizuje oddzielne repliki, których lokalizacje geograficzne są oddalone od siebie o setki kilometrów. Jednak ze względów prawnych (zwłaszcza w celu zachowania zgodności z przepisami dotyczącymi ochrony prywatności w Unii Europejskiej) ta nadmiarowość oddalonych lokalizacji geograficznych jest zwykle ograniczona do „granic miejsca przechowywania danych”, takich jak Ameryka Północna lub Europa.
![Rysunek 11. Struktura odporności platformy Azure, która chroni aktywne składniki na wielu poziomach zgodnie z normą ISO 22301. [Dzięki uprzejmości Firmy Microsoft]](../../cmu-cloud-admin/cmu-disaster-recovery-backup/media/fig9-11.jpg)
Rysunek 11. Struktura odporności platformy Azure, która chroni aktywne składniki na wielu poziomach zgodnie z normą ISO 22301. [Dzięki uprzejmości Firmy Microsoft]
Mimo iż norma ISO 22301 kojarzy się z odpornością i często jest opisywana jako zestaw wytycznych dotyczących odporności, poziomy odporności, dla których przetestowano platformę Azure, dotyczą tylko platformy Azure, a nie zasobów klienta hostowanych na tej platformie. Obowiązkiem klienta jest zarządzanie, konserwowanie i częste usprawnianie procesów, między innymi sposobu replikowania zasobów w chmurze platformy Azure i w innych miejscach.
Google Container Engine
Jeszcze do niedawna oprogramowanie było postrzegane jako stan komputera funkcjonalnie identyczny z sprzętem, ale w formie cyfrowej. W tym świetle oprogramowanie było odbierane jako względnie statyczny składnik w systemie informacyjnym. Protokoły zabezpieczeń nakazywały regularne aktualizowanie oprogramowania, a „regularne” zazwyczaj oznaczało kilka razy w roku, po udostępnieniu aktualizacji i poprawek błędów.
Co stało się realne dzięki dynamice chmury, a czego nie przewidziało wielu inżynierów IT, to możliwość stopniowego, ale częstego rozwijania oprogramowania. Ciągła integracja i ciągłe wdrażanie (CI/CD) to nowy zestaw zasad, zgodnie z którymi automatyzacja umożliwia częste (nawet codzienne) przemieszczanie przyrostowych zmian w oprogramowaniu, zarówno po stronie serwera, jak i klienta. Użytkownicy smartfonów regularnie mają kontakt z technologią CI/CD, korzystając z aplikacji, które są aktualizowane w sklepach z aplikacjami nawet kilka razy w tygodniu. Poszczególne zmiany wprowadzane przez technologię CI/CD mogą być niewielkie, ale fakt, że drobne zmiany można wdrażać błyskawicznie i bez żadnych trudności, przyniósł nieprzewidziany, choć pożądany efekt uboczny: znacznie większą odporność systemów informacyjnych.
W modelach wdrażania CI/CD całkowicie nadmiarowe klastry serwerów są aprowizowane i utrzymywane, często w infrastrukturze chmury publicznej, wyłącznie jako środek do testowania nowo wyprodukowanych składników oprogramowania na potrzeby obsługi błędów, a następnie przemieszczania tych składników w symulowanym środowisku roboczym w celu ujawnienia potencjalnych problemów. Dzięki temu procesy korygowania mogą odbywać się w bezpiecznym środowisku, które nie ma bezpośredniego wpływu na poziomy usług dla klienta lub użytkownika, dopóki środki zaradcze nie zostaną zastosowane, przetestowane i zatwierdzone do wdrożenia.
Usługa Google Container Engine (GKE, gdzie „K” oznacza „Kubernetes”) to środowisko Google Cloud Platform dla klientów wdrażających aplikacje i usługi oparte na kontenerach, zamiast aplikacji opartych na maszynach wirtualnych. Pełne wdrożenie konteneryzowane może obejmować mikrousługi („μ-usługi”), bazy danych oddzielone od obciążeń i przeznaczone do niezależnego działania („zestawy danych stanowych”), zależne biblioteki kodów i małe systemy operacyjne używane w przypadku, gdy kod aplikacji musi korzystać z własnego systemu plików kontenera. Rysunek 9.12 przedstawia tego rodzaju wdrożenie w stylu zalecanym przez firmę Google dla jej klientów usługi GKE.
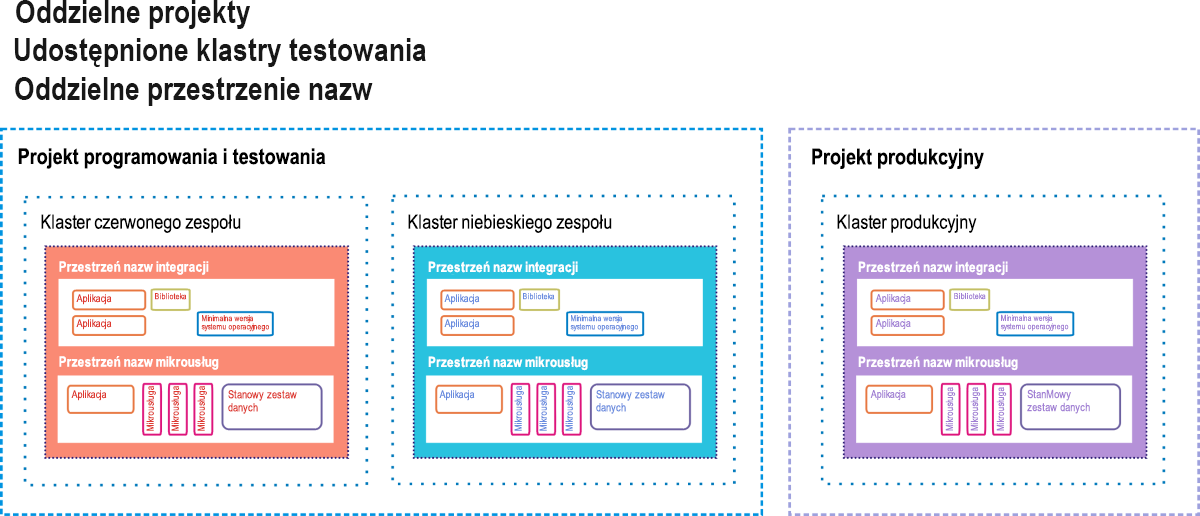
Rysunek 12. Opcja rezerwy dynamicznej jako środowisko przejściowe ciągłej integracji/ciągłego wdrażania dla aparatu kontenera Google.
W usłudze GKE projekt przypomina centrum danych pod tym względem, że ma wszystkie zasoby, które normalnie ma centrum danych, tylko w formie wirtualnej. Do projektu może być przypisany co najmniej jeden klaster serwerów. Konteneryzowane składniki istnieją we własnej przestrzeni nazw, które są jak ich środowiska domowe. Każda z nich składa się ze wszystkich adresowalnych składników, do których mają dostęp jej kontenery elementów członkowskich, a wszystkie elementy poza przestrzenią nazw muszą być adresowane przy użyciu zdalnych adresów IP. Inżynierowie firmy Google sugerują, że aplikacje klient/serwer w starym stylu (nazywane przez deweloperów kontenerów „monolitami”) mogą współistnieć z aplikacjami konteneryzowanymi, współużytkując ten sam projekt, dopóki każda klasa zapewnia bezpieczeństwo przy użyciu własnej przestrzeni nazw.
Na tym diagramie zalecanego wdrożenia znajdują się trzy aktywne klastry, z których każdy działa w dwóch przestrzeniach nazw: jednej dla starego oprogramowania i jednej dla nowego. Dwa z tych klastrów zostały oddelegowane na potrzeby testowania: jeden do wstępnego testowania programistycznego i jeden do finalnego przemieszczania. W potoku CI/CD nowe kontenery kodu są wprowadzane do jednego z klastrów testowania. W tym miejscu muszą przejść szereg zautomatyzowanych testów, udowadniając, że są względnie wolne od błędów, zanim zostaną przesłane do środowiska przejściowego. Tam czeka na nowe kontenery oprogramowania drugi zestaw testów. Tylko kod, który przeszedł testy przejściowe drugiej warstwy, może zostać wprowadzony do aktywnego klastra produkcyjnego używanego przez klientów końcowych.
Jednak nawet tam znajdują się zabezpieczenia przed błędami. W scenariuszu wdrażania A/B nowy kod współistnieje ze starym kodem przez określony czas. Jeśli nowy kod nie działa zgodnie ze specyfikacjami lub wprowadza błędy do systemu, można go wycofać, pozostawiając stary kod. Jeśli interwał dopuszczenia warunkowego wygasa, a nowy kod działa prawidłowo, wycofywany jest stary kod.
Ten proces to systematyczny i częściowo zautomatyzowany sposób na uniknięcie wprowadzania w systemach informacyjnych błędów, które prowadzą do awarii. Jednak nie jest to konfiguracja odporna na awarie, o ile sam klaster produkcyjny nie jest replikowany w trybie rezerwy dynamicznej. Oczywiście ten schemat replikacji zużywa mnóstwo zasobów opartych na chmurze. Jednak koszty wciąż mogą być dużo mniejsze od tych, które poniosłaby organizacja pozostawiona bez ochrony na wypadek awarii systemu.
Informacje
Sterbenz, James P.G., et al. "ResiliNets: Multilevel Resilient and Survivable Networking Initiative". https://resilinets.org/main_page.html
Patterson, David, et al. "Obliczenia zorientowane na odzyskiwanie: motywacja, definicja, zasady i przykłady." Microsoft Research, marzec 2002 r. https://www.microsoft.com/research/publication/recovery-oriented-computing-motivation-definition-principles-and-examples/.
ISO "Zabezpieczenia i odporność — systemy zarządzania ciągłością działania — wymagania". https://dri.ca/docs/ISO_DIS_22301_(E).pdf