Usługi odzyskiwania po awarii
Odzyskiwanie kopii zapasowych danych to, z oczywistych powodów, standardowa funkcja usług kopii zapasowych. Awarie nie ograniczają się jednak niestety do utraty danych. Awarie, które uniemożliwiają dostęp do serwerów organizacji, zarówno rzeczywistych, jak i wirtualnych, lokalnych, jak i w chmurze, wpływają na organizację w negatywny, a czasami nawet katastroficzny, sposób. Celem usługi odzyskiwania po awarii (DR, disaster recovery) jest zapewnienie kopii zapasowej nie tylko dla danych i poszczególnych zasobów, ale dla całych systemów, aby w sytuacji, gdy te systemy przestaną działać lub przejdą do trybu offline, można było wznowić usługę, przekierowując ruch do replik, które są gotowe do przejęcia obciążenia.
Odzyskiwanie po awarii to dziedzina, w której chmura publiczna naprawdę się przydaje. To coś więcej, niż tylko ogromna stacja taśm. Ponieważ zasoby w chmurze są wirtualne, repliki można uruchomić błyskawicznie, aby zastąpiły zasoby, które nagle zniknęły. Repliki mogą nawet być hostowane w innych częściach świata, niż odzwierciedlane przez nie systemy, aby obejść awarie dotyczące całego obszaru. Wystarczy porównać to z wydatkami związanymi z utrzymywaniem fizycznych replik fizycznych systemów informacyjnych (zlokalizowanych w różnych regionach geograficznych), a wartość chmury w zakresie utrzymywania ciągłości tych systemów zaczyna być oczywista.
Wiodący dostawcy usług w chmurze oferują odzyskiwanie po awarii jako usługę (DRaaS, Disaster-Recovery-as-a-Service), ale te usługi należy celowo zaplanować i skonfigurować, aby zapewnić obsługę trybu failover, której żąda klient. W związku z tym zaczniemy od zbadania celów i metryk, które składają się na takie planowanie.
Cele i metryki
Podczas awarii organizacja i jej klienci mogą utracić dostęp do wielu klas zasobów cyfrowych jednocześnie — najważniejsze z nich są następujące:
Bazy danych i magazyny danych, które oprócz rejestrowania ważnych informacji o klientach i towarach i/lub usługach w spisie, utrzymują aktywny stan transakcji i procesów biznesowych dla całej organizacji
Dane zbiorcze, w tym dokumenty, pliki multimedialne i inne zapisane rekordy, które są produktami aplikacji używanych przez ludzi
Komunikacja i łączność z osobami i usługami biznesowymi, co stanowi istotę wszelkich możliwych działań biznesowych
Aplikacje, które reprezentują witryny sklepów organizacji dla klientów i patronów, a także dla własnych uczestników projektów
Mimo że odzyskiwanie po awarii jest przedstawiane klientom jako pojedyncza usługa, proces odzyskiwania dla każdej z tych klas jest oddzielny. W erze klientów/serwerów wiele organizacji prowadziło swoją codzienną działalność na komputerach osobistych. Jeśli komputer uległ awarii, ale istniał obraz kopii zapasowej lokalnego magazynu komputera, teoretycznie można go było odzyskać na nowym komputerze i kontynuować pracę. W przypadku pierwszych komputerów sieciowych połączonych za pomocą systemów operacyjnych sieci LAN i kabla Ethernet można było przywrócić każdy komputer w sieci z obrazu kopii zapasowej, a następnie wznowić pracę samej sieci.
Chmura nie działa w ten sposób. Nawet maszyna wirtualna, która pełni rolę serwera dla aplikacji organizacji, nie obejmuje w całości żadnej części wykonywanej przez siebie pracy. Usługi kopii zapasowych chronią dane zbiorcze oraz, w ograniczonym zakresie, dane transakcyjne i bazy danych. Jednak każda z tych jednostek jest własnym składnikiem, dlatego przywrócenie funkcji biznesowych w trakcie awarii wymaga ponownego ustanowienia większości, jeśli nie wszystkich, funkcji każdego z tych składników z bezpiecznej lokalizacji.
W związku z tym proces odzyskiwania po awarii wymaga koordynacji wszystkich procedur wdrożonych w celu przywrócenia pełnej zdolności operacyjnej organizacji. Co więcej, charakter działalności prowadzonej w tym okresie staje się bardziej krytyczny ze względu na istnienie samej awarii. Zdarzenie, które jest w stanie wyłączyć krytyczną infrastrukturę, prawdopodobnie powoduje uszkodzenie innych aspektów związanych z funkcjonowaniem firmy — magazynów, wysyłek, produkcji i dostaw. Przypuszczalnie przywracana działalność nie może być bezproblemowym wznowieniem działania firmy, które było prowadzone przed zdarzeniem awarii.
To, co łączy wszystkie te procedury, to obecność wspólnych, jasno zdefiniowanych celów poziomu usług. Usługi odzyskiwania po awarii platform AWS i Azure, a także usługi innych firm utworzone na platformie Google Cloud, uwzględniają następujące cele:
Cel punktu odzyskiwania (RPO) — Minimalna dozwolona ilość danych, które muszą zostać dostarczone z powrotem do klientów dla usługi opartej na zasobach kopii zapasowych, aby można je było uznać za odzyskane. Z drugiej strony ta ilość może być uważana za maksymalną akceptowalną utratę danych wyrażoną w wartości procentowej odjętej od liczby 100.
Cel czasu odzyskiwania (RTO) — Maksymalny dozwolony przedział czasu dla trwania procesu przywracania, który może być również traktowany jako miara tego, na jak duży przestój może sobie pozwolić organizacja.
Okres przechowywania — Maksymalny dozwolony okres czasu, przez jaki może być przechowywany zestaw kopii zapasowej, zanim trzeba go będzie odświeżyć i wymienić.
Cele RTO i RPO mogą być postrzegane jako równoważone względem siebie, dzięki czemu klient może zdecydować się na wydłużenie czasu odzyskiwania w celu uzyskania wyższych punktów odzyskiwania. Jeśli czas odzyskiwania jest problemem dla klienta ze względu na dostępną przepustowość lub ryzyko przestoju, klient może nie być w stanie osiągnąć wysokiego celu punktu odzyskiwania.
Profesjonalny doradca ds. ryzyka lub specjalista ds. ciągłości działania prawdopodobnie będzie nalegać na zastosowanie tych trzech zmiennych podczas formułowania zasad odzyskiwania po awarii. W większości raportów dotyczących analizy wpływu na działalność biznesową (BIA, business impact analysis), cele RTO i RPO zajmują centralne miejsce. Są to krytyczne zmienne w ocenach specjalistów dotyczących potencjalnych strat wynikających ze zdarzeń awarii. Niektórzy doradcy używają zmiennej zagregowanej o nazwie cel poziomu usługi (SLO, service-level objective), jednak nie istnieje jeszcze pojedyncza formuła pozwalająca ocenić cel SLO. Jeśli dostawca rozwiązań w chmurze potrafi określić poziom swoich usług przy użyciu terminologii, którą znają i doceniają doradcy ds. ryzyka, ułatwia to obustronną współpracę — co często odgrywa znaczącą rolę przy wyborze dostawcy usług odzyskiwania po awarii przez organizację.
Metodologie i procedury
W poprzedniej lekcji omówiliśmy najbardziej podstawową formę odzyskiwania systemu informacyjnego obejmującą kopie zapasowe odpowiednich plików, woluminów magazynów i obrazów maszyn wirtualnych. Mimo że nadal jest to przedstawiane jako opcja usługi odzyskiwania po awarii, w praktyce ma to zastosowanie do coraz mniejszej liczby organizacji, głównie dlatego, że utrzymanie odpowiednich celów RTO nie jest możliwe.
Profesjonalne usługi odzyskiwania po awarii oferują różne metodologie wdrażania i zarządzania, a niektóre z nich obejmują konserwację usługi przed zdarzeniem awarii. Te metodologie zostały zestawione poniżej. Wszystkie trzy są oparte na różnorodnych opcjach kopii zapasowych omówionych w poprzedniej lekcji i są one tak samo odpowiednie dla wszystkich dostawców usług. Klient, który chce uruchomić jeden z tych trybów odzyskiwania, wybiera klasy replikacji, geolokalizacji i magazynu najlepiej dopasowane do danego trybu.
Płomień pilotażowy
W tej metodologii (rysunek 5) istnieje miejsce na kompletne centrum danych w stanie gotowości. Tam, pewne podstawowe usługi i aplikacje, wraz z danymi, które je obsługują, są utrzymywane w klastrze trybu failover, który można „odpalić” w momencie wystąpienia zdarzenia awarii, często automatycznie. W międzyczasie wdrażane są serwery wirtualne z podstawowymi funkcjami wymaganymi do utrzymania aktywności w razie potrzeby. Te zredukowane serwery mogą być wyposażone w funkcje poczty e-mail i sieci internetowej, umożliwiające komunikację z klientami i w organizacji. Włączenie trybu odzyskiwania Płomień pilotażowy może wymagać ciągłego synchronizowania nietrwałych magazynów danych, takich jak transakcyjne bazy danych i woluminy poczty e-mail.
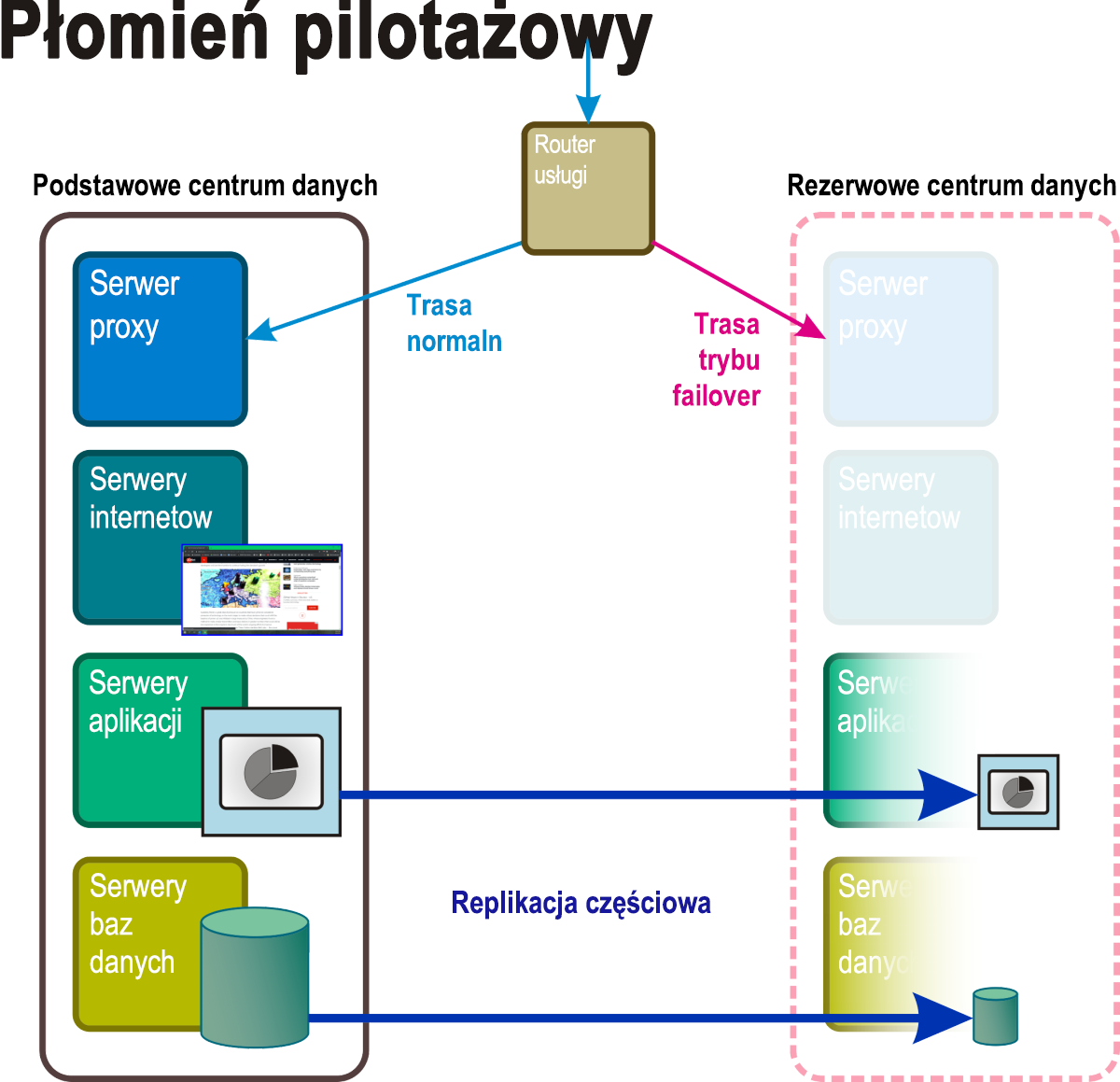
Rysunek 5. Aktywne i pasywne składniki scenariusza odzyskiwania światła pilotażowego.
Rezerwa aktywna
W tym trybie odzyskiwania, przedstawionym na rysunku 6, w co najmniej jednej oddzielnej lokalizacji geograficznej utrzymywane są stale uruchamiane repliki wszystkich usług i aplikacji systemowych oraz wszystkich krytycznych danych firmowych. Dostęp do tej kompletnej repliki jest pomijany przez aktywny router do momentu, aż zdarzenie awarii wyzwoli regułę, która zastępuje adres aktywnej sieci adresem znajdującym się na trasie pomijania.
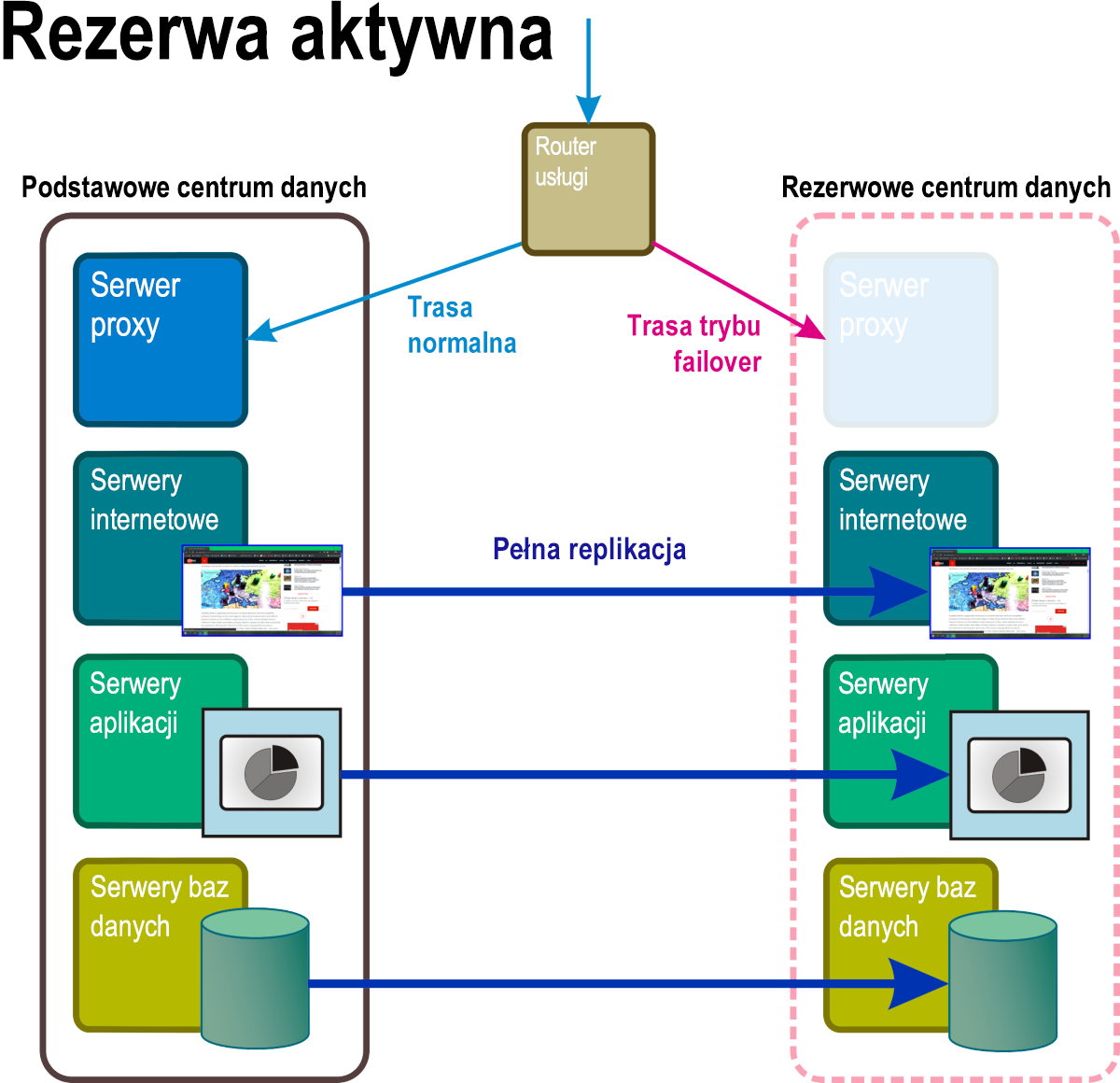
Rysunek 6. Scenariusz odzyskiwania rezerwy ciepłej z niektórymi składnikami w rezerwowej przestrzeni nazw w pełni operacyjnej.
Rezerwa dynamiczna
W tym scenariuszu (rysunek 7) co najmniej dwie kompletne repliki wszystkich usług i aplikacji działają przez cały czas, z pełną i ciągłą synchronizacją danych między nimi. Router główny pełni rolę pewnego rodzaju głównego modułu równoważenia obciążenia, który dystrybuuje żądania do wszystkich lokalizacji serwera w mniej więcej równych proporcjach. Wystąpienie zdarzenia awarii wyzwala proces działający podobnie do zapory, w którym adres dotkniętego systemu jest usuwany z tabeli routingu.
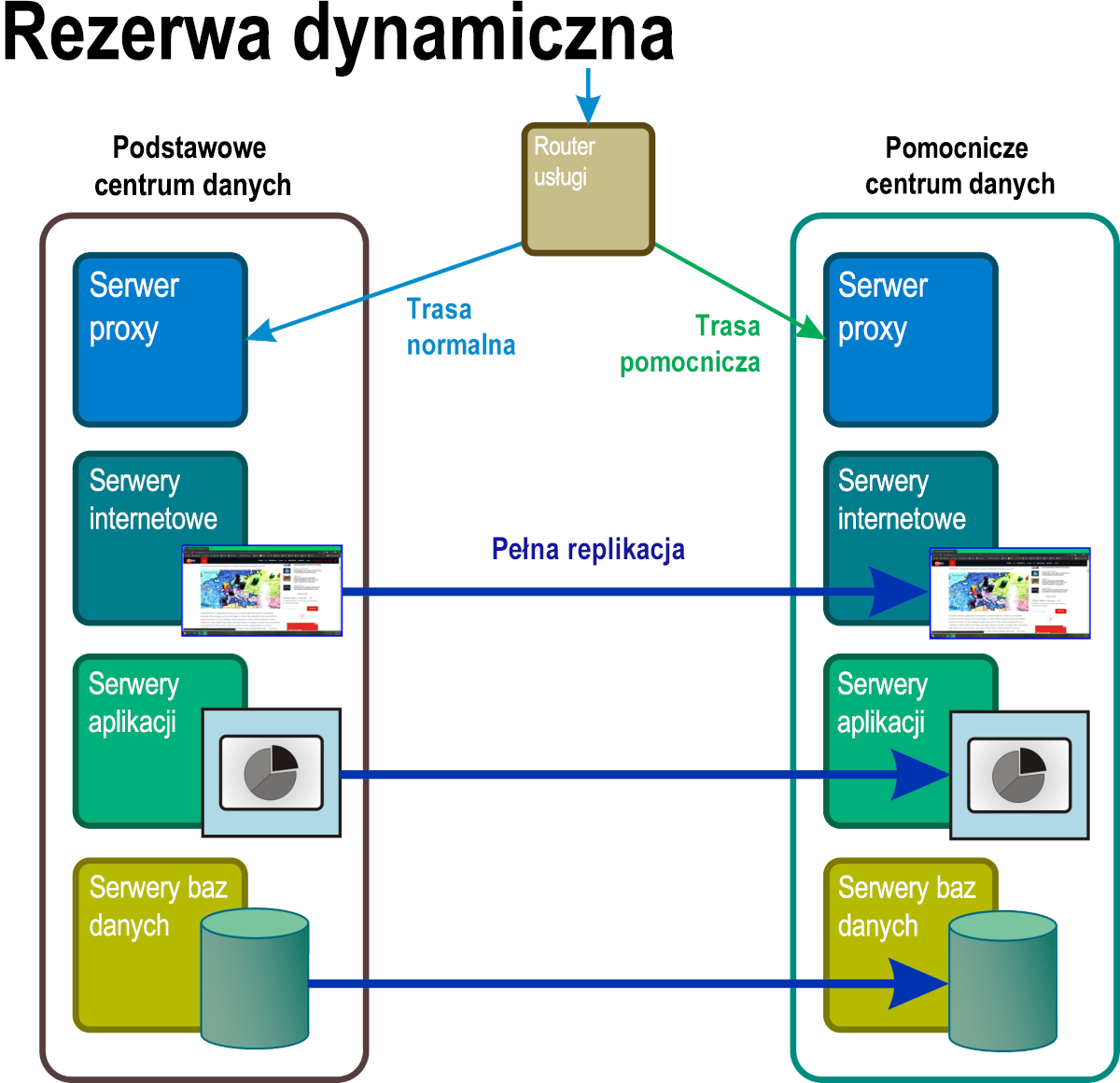
Rysunek 7. W przypadku rezerwy dynamicznej wszystkie składniki w przestrzeni nazw, które normalnie byłyby rezerwą, miejscem rezerwowym, są aktywne, w pełni operacyjne i przetwarzają repliki danych podstawowych w czasie rzeczywistym.
Aplikacje natywne dla chmury
Teoretycznie jest możliwe, aby organizacja wybrała usługę odzyskiwania po awarii od jednego dostawcy jako zabezpieczenie dla usług hostowanych przez innego dostawcę. Innymi słowy, zakładając właściwy poziom uwagi personelu IT, infrastruktura jednego dostawcy CSP (np. firmy Google) może służyć jako miejsce docelowe trybu failover dla procedury rezerwy aktywnej hostowanej w infrastrukturze innego dostawcy CSP (takiej jak platforma Azure). Taka konfiguracja może być niezbędna w scenariuszach dotyczących księgowości lub jeśli zasoby obliczeniowe w przedsiębiorstwie są zarządzane przez oddzielne działy w różnych częściach świata.
Obecność infrastruktury konteneryzowanej w lokalnym centrum danych, a także w chmurze, może mieć znaczący wpływ na wszystkie te metodologie odzyskiwania po awarii. Tak zwana aplikacja natywna dla chmury, opracowana wyłącznie do użytku na platformie chmury publicznej lub na platformie, która działa podobnie (na przykład Microsoft Azure Stack), dystrybuuje funkcje w wielu kontenerach replik, z których kilka lub wszystkie mogą działać jednocześnie. Powodem jest nie tyle umożliwienie nowej klasy scenariusza odzyskiwania po awarii, co dystrybucja obciążeń między procesorami.
Jednym z kolejnych aspektów architektury natywnej dla chmury jest możliwość kontaktu z bazami danych, których zawartość jest już automatycznie replikowana, za pomocą adresu sieciowego, którego mapa jest dostępna wyłącznie dla danej aplikacji. (Innymi słowy, chociaż używa protokołu internetowego, jego adres nie jest lokalizacją w szerszym publicznym Internecie). W ten sposób podczas zdarzenia awarii niektóre węzły dołączone do bazy danych mogą ulec awarii, wiele będzie się powtarzać, a inne będą mieć miejsce niedostępnych węzłów. Nie kwalifikuje się to jeszcze jako wbudowane odzyskiwanie po awarii, jednak można to zdecydowanie opisać jako odporność na awarie.
Odzyskiwanie po awarii jako usługa (DRaaS)
W przypadku dostawcy usług w chmurze publicznej odzyskiwanie po awarii jest sposobem na korzystanie z podstawowych usług tworzenia kopii zapasowych i przesyłania danych. Każdy główny dostawca rozwiązań w chmurze, oprócz swoich usług tworzenia kopii zapasowych, implementuje inną strategię w zakresie ułatwiania odzyskiwania po awarii.
AWS CloudEndure
Migracja usługi odnosi się do przenoszenia obciążeń wirtualnych z prywatnej infrastruktury lokalnej do infrastruktury chmury publicznej. Ta relokacja jest niezbędna w przypadku niektórych usług odzyskiwania po awarii, które działają w chmurze publicznej, aby osiągnąć cel przejścia do trybu failover i odzyskiwania w ciągu kilku minut od zdarzenia awarii.
W styczniu 2019 r. firma Amazon nabyła usługę migracji usług prywatnych CloudEndure, która używała już platformy AWS jako swojego dostawcy infrastruktury. Od tego czasu firma Amazon zintegrowała usługę CloudEndure ze swoją główną linią usług, oferując swoim klientom migrację usług bez dodatkowych opłat. Obecnie platforma AWS implementuje migrację usług jako sposób na szybkie uruchomienie procesu rezerwy aktywnej lub dynamicznej. W usługach AWS proces migracji jest bezpłatny, jednak pobierane są opłaty za nadmiarowe zasoby aprowizowane na potrzeby każdego scenariusza odzyskiwania po awarii. Mimo to brak dodatkowej opłaty sprawia, że rozwiązanie CloudEndure jest konkurencyjne w porównaniu z mnóstwem usług odzyskiwania po awarii innych firm.
Azure Site Recovery
Usługa odzyskiwania po awarii firmy Microsoft, Azure Site Recovery, jest zarządzanym wdrożeniem metody odzyskiwania Rezerwa aktywna dla środowisk opartych na maszynach wirtualnych i dla serwerów fizycznych (lokalnych) z systemem Linux lub Windows. Maszyny wirtualne są aktywnie replikowane do regionu pomocniczego (rysunek 9.8), do którego można zainicjować tryb failover za pomocą jednego kliknięcia. Klienci są naliczani miesięczną opłatę (obecnie około 25 USD) za każdy serwer lub maszynę wirtualną chronioną przez usługę Azure Site Recovery.
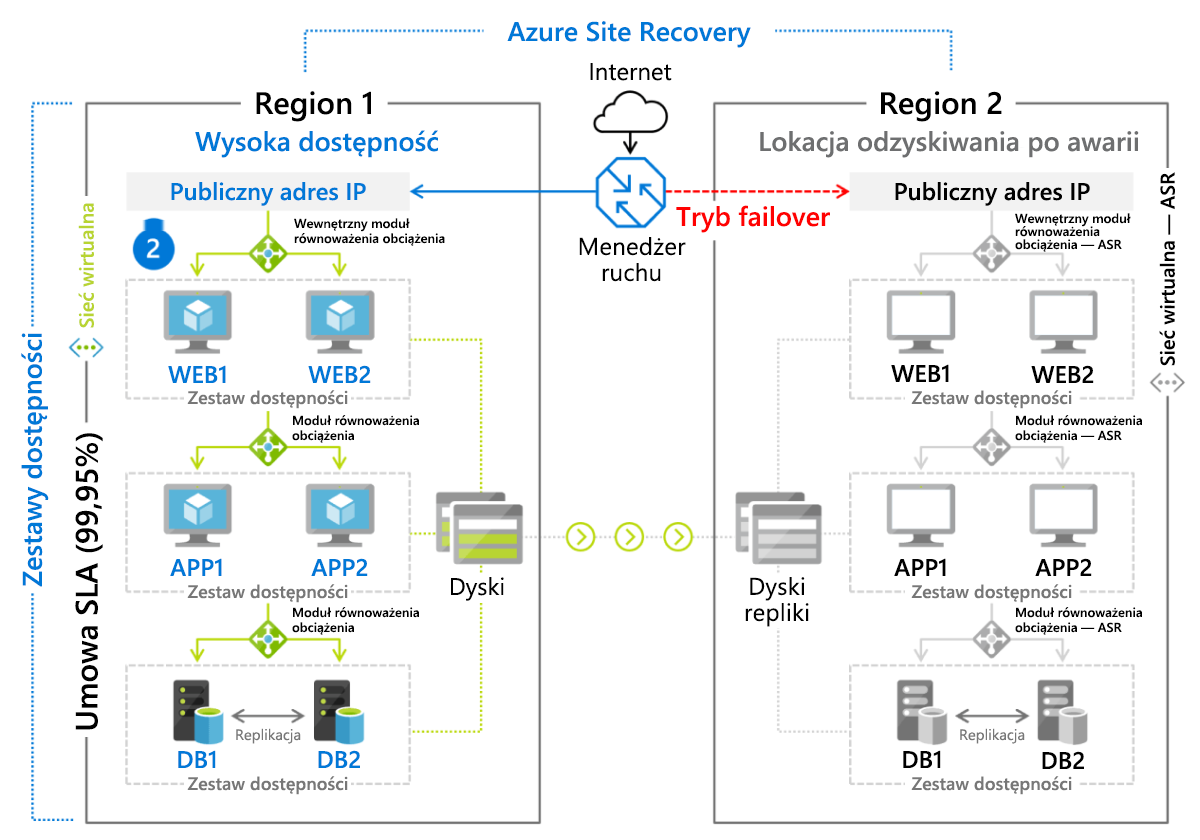
Rysunek 8. Scenariusz trybu failover zaimplementowany przy użyciu usługi Azure Site Recovery.
Odzyskiwanie po awarii platformy Google Cloud
Podobnie jak w przypadku kopii zapasowej, firma Google nie oferuje własnej usługi przeznaczonej wyłącznie do odzyskiwania po awarii. Zamiast tego udostępnia niezbędne narzędzia i zasoby do przechowywania i przesyłania danych oraz oferuje klientom wskazówki, jak najlepiej używać ich w różnych scenariuszach odzyskiwania po awarii.
Ponieważ firma Google oferuje opcje magazynu zimnego i stosuje do nich rabat, platforma GCP ma zastosowanie do szerokiego zakresu scenariuszy. Magazyn zimny jest atrakcyjną opcją dla organizacji, które utrzymują dużą ilość danych zbiorczych. Wirujące dyski magnetyczne stają się niepraktycznymi zbiornikami na pliki multimedialne, których średnie rozmiary wynoszą dziesiątki gigabajtów. Składniki magazynu dołączonego do sieci (NAS, Network-Attached Storage) zapewniają rozwiązanie do udostępniania i zarządzania dla organizacji tworzących multimedia, ale tylko na poziomie lokalnym. Oferują one wewnętrzną nadmiarowość, ale nie są odporne na awarie. Dla tej klasy klientów scenariusz odzyskiwania po awarii, taki jak trzy przedstawione wcześniej, nie byłby praktyczny (ani nawet ekonomiczny). Magazyn zimny przedstawia przynajmniej jeden realny sposób osiągnięcia przez tego klienta nominalnego poziomu zapewnienia ciągłości działania.