Awarie i odporność na uszkodzenia
W codziennym rozszkoleniu firma Microsoft chce w sposób nieswobodny mówić o niepowodzeniach systemów przyczyn. Wystąpił błąd, usterka, błąd, usterka, wada — te warunki są używane zamiennie. W centrum danych specjaliści nigdy nie muszą mylić tych wyrazów ani korzystać z nich zamiast innych. Oto Szczegółowa definicja warunków związanych z dyskusjami o odporności na uszkodzenia:
Usterka jest anomalią w projekcie systemu, który powoduje, że jego zachowanie może się różnić w zależności od wymagań lub oczekiwań. Może to być w jednym sensie, że system lub oprogramowanie nie spełnia oczekiwań, ale usterka nie jest uszkodzeniem systemu. W rzeczywistości wiele usterek jest produktem, który działa dokładnie tak, jak zostały zaprojektowane, w przeciwieństwie do przeznaczenia. Kluczowym słowem jest tutaj "konsekwentnie". Zachowanie usterki może zostać odtworzone we wszystkich wystąpieniach systemu. Debugowanie to czynność przetworzenia systemu w celu wyeliminowania błędów.
Usterka jest anomalią w systemie, która sprawia, że nie działa inaczej niż jego projekt lub aby całkowicie zaprzestać działania. W tym miejscu projekt systemu może nie mieć żadnych wad, ale w jednej implementacji lub wystąpieniu tego projektu może nie działać prawidłowo. Błąd prowadzi do zachowania, którego nie można spodziewać się odtworzyć w żadnym innym wystąpieniu systemu. Czynność wyeliminowania błędu jest znana jako Repair. Usterka systemowa może być manifestem na jeden z trzech sposobów:
trwałe błędów to zakłócenie systemu, którego przyczyną jest nieodwracalność bez całkowitego zastąpienia składnika odpowiedzialnego
przejściowe jest tymczasowa, chociaż zwykle nie jest powtarzane, zakłócenia systemu, którego przyczyną może być naprawa lub zaakceptowana w miejscu, lub które mogą zostać wyczyszczone bez interwencji
sporadyczne błędów to tymczasowe, zwykle powtarzające się przerwy w działaniu systemu, które często wynikają z obniżenia wydajności lub nieprawidłowego projektowania składnika, co może prowadzić do trwałego błędu.
Niepowodzenie jest kompletnym zwijaniem wszystkich lub części systemu, często wyzwalane przez nieadresowanie błędu. W tym przypadku usterka jest przyczyną błędu, a wynikiem jest niepowodzenie. odporny na błędy (FT) jest taki, który zachowuje się zgodnie z oczekiwaniami lub zgodnie z założeniami dotyczącymi poziomu usług (SLA), w niekorzystnych okolicznościach i dlatego unika błędów w obecności.
Usterka jest anomalią w wytwarzaniu składnika sprzętowego lub wystąpienia składnika oprogramowania, który prowadzi do błędu w operacji i, prawdopodobnie, Niepowodzenie systemu implementującego ten składnik. Takie anomalie może zostać skorygowane tylko przez zastąpienie.
Em błędu jest iloczyn operacji, która generuje niepożądany lub niepoprawny wynik. Na urządzeniu obliczeniowym błąd może być objawem usterki w projekcie lub błędu w jego implementacji i może być skutecznym wskaźnikiem oczekujących awarii.
Konserwacja systemów odpornych na uszkodzenia wymaga od specjalisty IT, administratora lub operatora, aby comprehend te koncepcje i zrozumieć różnice między nimi. Platforma obliczeniowa w chmurze polega na użyciu definicji systemu odpornego na błędy. Jest ona zaprojektowana i skompilowana w celu przewidzenia błędów i działa, aby uniknąć awarii usługi. Z punktu widzenia inżynierów ta odporność to znaczenie koncepcji "chmurowej". Gdy inżynierowie telefoniczni w pierwszej kolejności używają kształtu chmury w swoich diagramach systemu, reprezentuje składniki sieci, które nie muszą być widoczne ani zrozumiałe, ale których poziomy usług były wystarczająco niezawodne, aby nie musiały być częścią diagramu — mogą one być zasłonięte przez chmurę.
Gdy system informacyjny, taki jak sieć IT w przedsiębiorstwie, nawiązuje kontakt z platformą chmury publicznej, Ta platforma ma obowiązek zachowywać się jako system FT. Nie jest to jednak możliwe, ale system nie może komunikować się z nim więcej uszkodzeń, niż jest to już zrobione. Odporność na uszkodzenia nie jest odporna, ani nie jest gwarancją w odniesieniu do istnienia błędów w systemie. Więcej do punktu, system FT nie musi być faultless. Nie jest to jednak zdolność systemu do obsługi oczekiwanych poziomów usług, gdy występują błędy.
Celem każdego systemu informacji jest Automatyzacja funkcji wykorzystujących informacje. Odporność na uszkodzenia może być sama tylko w ograniczonym stopniu. Sama Internet w oryginalnej inkarnacji jako ARPANET ma odporność na uszkodzenia jako jeden z celów głównych. W przypadku awarii można przekierować komunikację cyfrową w celu obejścia systemu, którego adres nie był już osiągalny. Jednak Internet nie jest samoobsługowym komputerem, żaden system informacji nie jest.
Nakłady pracy przez człowieka są ciągle niepotrzebne w przypadku każdego systemu informacji do osiągnięcia i utrzymania swoich celów usługi. Najlepsze systemy sprawiają, że interwencja ludzka i korygowanie są proste, natychmiastowe i zgodne z planem.
Odporność na uszkodzenia na platformach w chmurze
Wczesne platformy usług w chmurze były rodzaju, a mniej odporne na uszkodzenia niż ich architekty. Na przykład możliwość nadmiernej aprowizacji zasobów przez klienta dla usług, takich jak wiele wystąpień bazy danych lub zduplikowane pamięci podręczne, okazała się nieskuteczna przy niewystarczającym monitorowaniu, co czasami prowadzi do tworzenia kopii zapasowych lub replik niedostępne w sytuacjach awaryjnych. Co więcej, Inicjowanie obsługi administracyjnej jest oparte na jednej z podstawowych założenia modelu biznesowego w chmurze: płacisz tylko za te zasoby. Organizacja nie może zaoszczędzić wydatków operacyjnych, jeśli dzierżawią dodatkowe wystąpienia maszyn wirtualnych na wypadek awarii podstawowej maszyny wirtualnej.
System FT pozwala na nadmiarowość, ale w rozsądny i dynamiczny sposób, dostosowując wymagania i limity dostępności zasobów bieżącego momentu w czasie. W przypadku ery klient/serwer utworzono kopię zapasową wszystkich serwerów, w tym zarówno lokalny magazyn danych, jak i woluminy magazynu sieciowego, do których zostały dołączone, w regularnych odstępach czasu. "Tworzenie kopii zapasowej wszystkiego" stało się firmową Ethic unto. Gdy usługi w chmurze publicznej stały się zarówno przystępne cenowo, jak i praktyczne, organizacje zaczęły umieszczać je w celu "tworzenia kopii zapasowej wszystkiego". W czasie doszli do głowy, że chmura może zrobić więcej niż utrwalać stare metody. Platformy w chmurze mogą być zaprojektowane pod kątem odporności na uszkodzenia, a nie po ich wdrożeniu.
Techniki reaktywne
Niezależnie od tego, jak Thoughtfully system został zaprojektowany, większość odporności na uszkodzenia będzie zależeć od tego, jak dobrze system i osoby zarządzające nim odpowiadają na pierwsze dowody błędu. Poniżej wymieniono niektóre z nieaktywnych technik, których organizacje używają do ograniczania błędów, gdy wystąpią.
Migracja zadań niepoprzedzających prewencyjne
Technika migracji nieprewencyjneego zadania polega na tym, że host dla obciążenia, które prawdopodobnie wyniósł błąd nie jest ponownie przypisany do hosta tego samego obciążenia. Ta korzyść chroni "zadanie", chociaż może to spowodować, że system nie będzie mógł zbierać powtórzonych wystąpień błędu jako dowód błędu, co może być łatwiejsze do śledzenia za pomocą dobrze rejestrowanej ścieżki.
Replikacja zadań
Wiele rozproszonych systemów informacyjnych uruchamia wiele wystąpień (lub dla aranżacji Kubernetes, replik) zadania jednocześnie. W przypadku systemów zarządzania opartych na zasadach można przeprowadzić replikację zadania w przypadku wystąpienia widocznego lub podejrzanego błędu systemu.
Punkty kontrolne i punktów przywracania
W najprostszej postaci punkty kontrolne i punkt przywracania obejmują tworzenie migawek systemu w różnych punktach w czasie i umożliwienie administratorom "wycofywania" do określonego momentu w czasie, gdy przywracanie stanie się konieczne. Ta strategia jest bardziej skomplikowana, gdy transakcje są wykorzystywane — na przykład, gdy aplikacja wykonuje co najmniej dwie akcje w bazie danych, która musi zakończyć się powodzeniem lub niepowodzeniem jako jednostkę ("transakcja"). Typowym przykładem jest aplikacja, która jest w stanie obciążyć pieniądze na podstawie jednego konta, a dopiero po rozliczeniu z innego. Te operacje muszą zakończyć się sukcesem lub niepowodzeniem jako jednostka, aby uniknąć tworzenia lub niszczenia zasobów finansowych.
W przypadku transakcyjnego punktu kontrolnego — odzyskiwanie rekordów transakcji są przechowywane w pamięci wdrzewie procesów. W określonych punktach w trakcie transakcji, używane zasoby pamięci są replikowane i zdeponowane w puli przywracania. W przypadku, gdy analiza dzienników wskazuje błąd prawdopodobnie spowodowany przez oprogramowanie, drzewo procesu jest rozwidlenia, stan transakcji jest przenoszony z powrotem do wcześniejszego punktu i zostanie podjęta Nowa transakcja. Jeśli nowa transakcja daje lepszy sukces niż wadliwy (na przykład jeśli test korekcji błędów zostanie wyczyszczony), stara gałąź procesu zostanie oczyszczona i nowa gałąź następuje po tym etapie w drzewie, dla którego inżynierów wywołują kontekstu.1
Jedna zaawansowana wersja tej metodologii implementuje System śledzenia w drzewie procesów, dzięki czemu w przypadku ponownego wystąpienia błędu system może obsłużyć proces do tyłu i śledzić przyczynę błędu. Może następnie wybrać odpowiedni punkt przywracania lub "punkt ratowniczy" przed wyzwoleniem błędu.[2]
Inna implementacja, nazywana SGuard, została utworzona przez pracowników naukowo-badawczych na Uniwersytecie, a firma Microsoft bada w poszukiwaniu odpornego na błędy przetwarzania dużych strumieni danych. SGuard wykorzystuje rozproszony system plików Hadoop (HDFS) do zaplanowania równoczesnego zapisu kilku migawek strumieni danych podczas przetwarzania. Te migawki są podzielone na mniejsze porcje w razie potrzeby, z kolei poddzielenie przetwarzania strumienia na mniejsze segmenty. Punkty kontrolne są przechowywane w systemie plików HDFS. Ten system ma na celu utrzymywanie rekordu transakcji danych przesyłanych strumieniowo, a także wiele wydajnych replik danych przesyłanych strumieniowo w wysoce rozproszonych lokalizacjach. Chociaż implementacja rozwiązania SGuard wymaga dość rozległych prac przygotowawczych, jest ono nadal uważane za reaktywną technikę uzyskiwania odporności na uszkodzenia, ponieważ jego główne działanie jest wyzwalane w odpowiedzi na uszkodzenie.3
Techniki proaktywne
proaktywna technika FT jest podejmowana przed Revelation jakiegokolwiek błędu. Jego intencją jest prewencyjność, ale w nowoczesnej implementacji jest to bardziej metodologia niż mantrą. Poniżej przedstawiono niektóre techniki, które są obecnie używane przez nowoczesne platformy w chmurze.
Replikacja zasobów
Kluczem do efektywnej strategii replikacji zasobów może nie być tylko "tworzenie kopii zapasowej wszystkiego". Analityk systemów powinien mieć możliwość ustalenia, które zasoby w systemie (na przykład aparat bazy danych, serwer sieci Web lub router sieci wirtualnej) mogą przywrócić się po wystąpieniu zdarzenia awarii i które mogą być nieodwracalne. Inteligentna replikacja może być pierwszym wierszem obrony w systemie odpornym na błędy.
Istnieją cztery popularne strategie używane do implementowania replikacji zasobów, z których wszystkie przedstawiono na rysunku 1:
replikacji aktywnej — wszystkie zreplikowane zasoby są aktywne współbieżnie, a każdy z nich niezależnie zachowuje swój własny stan — własne dane lokalne, które to działają. Ta właściwość oznacza, że żądanie klienta jest odbierane przez wszystkie zreplikowane zasoby w klasie, a wszystkie zasoby przetwarzają odpowiedzi. Jest to jednak wystawiony zasób podstawowy w tej klasie, którego odpowiedź jest dostarczana do klienta. Jeśli jeden z zasobów ulegnie awarii, w tym węzeł podstawowy, inny węzeł zostanie wyznaczył jego następcę. Ten system wymaga przetwarzania między węzłem podstawowym a węzłami repliki, aby deterministycznych — na przykład, a w zestawie tras.
Replikacja częściowo aktywna-częściowo-aktywna replikacja jest podobna do aktywnej replikacji, a różnica polega na tym, że węzły repliki mogą przetwarzać żądania w sposób Niedeterministyczny lub nie wspólnie z węzłem podstawowym. Dane wyjściowe zasobów pomocniczych są pomijane i rejestrowane i są gotowe do przełączenia, gdy tylko wystąpi awaria zasobu podstawowego.
Replikacja pasywna — tylko podstawowy węzeł zasobów przetwarza żądania, natomiast pozostałe (repliki) utrzymują stan i oczekują na wyznaczenie, jeśli wystąpi awaria. Zasób podstawowy, z którym klient znajduje się w kontakcie, przekazuje wszelkie zmiany stanu do wszystkich replik. Wszystkie oryginały i repliki należące do klasy są uznawane za "składowe" grupy, a członek może zostać uruchomiony z grupy, jeśli prawdopodobnie się nie zakończył. Istnieje możliwość obniżenia liczby opóźnień lub jakości usług (QoS) podczas zdarzenia awarii, choć replikacja pasywna zużywa mniejszą ilość zasobów podczas normalnego działania.
Replikacja częściowo pasywna — Ta metodologia ma ten sam wzorzec relacji co w przypadku replikacji pasywnej, z tą różnicą, że nie istnieje stały zasób podstawowy. Zamiast tego rolę koordynatora jest wyznaczony dla każdego zasobu z kolei, a koordynacja jest określana przez model przekazywania tokenów o nazwie "model koordynatora.
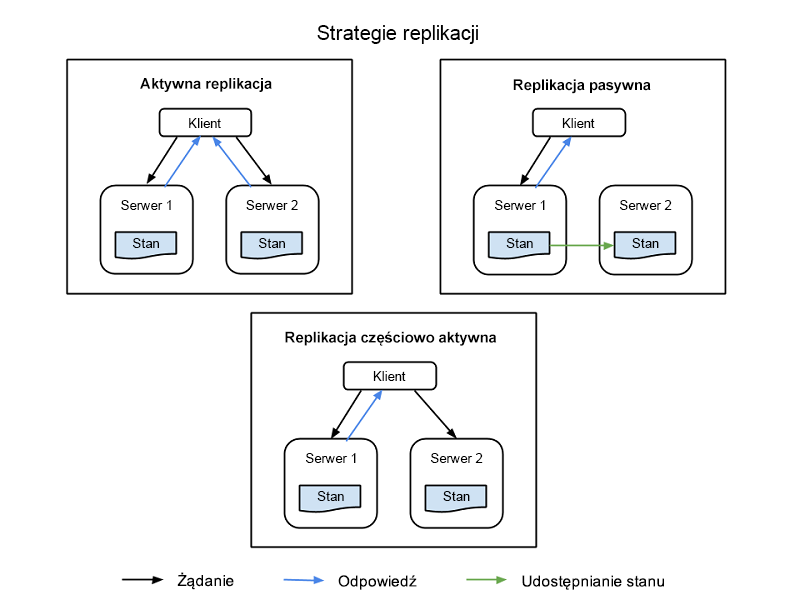
Rysunek 1. Węzły klienta, węzły podstawowe i węzły repliki w zreplikowanym systemie informacyjnym.
Równoważenie obciążenia
Moduły równoważenia obciążenia dystrybuują żądania od różnych klientów między wieloma serwerami z tą samą aplikacją, co umożliwia dystrybucję obciążeń i zmniejszenie obciążenia składników systemowych. Dodatni efekt uboczny korzystania z modułu równoważenia obciążenia polega na tym, że niektóre będą automatycznie kierować ruchem z nieodpowiadających serwerów, co zmniejsza prawdopodobieństwo wystąpienia błędów wszystkich. W przypadku bardziej nowoczesnych elementów pochodnych, w przypadku których oprogramowanie zostało zaprojektowane do dystrybucji w całej platformie chmurowej (na przykład mikrousługi), obciążenia są podzielone między osobne funkcje, które są dystrybuowane między procesorami po stronie serwera a celem w kierunku równości dystrybucji i średniego poziomu wykorzystania.
Wirtualizacja (kluczowy składnik usługi Cloud Computing) umożliwia równomierne dystrybuowanie obciążeń między procesorami przez ich przełączenie, dzięki czemu mogą one być przenoszone do fizycznego procesora, który może być optymalnym użyciem. Kontenerach poprawia tę technikę, oddzielając Zwirtualizowane obciążenia z procesorów wirtualnych, aby znajdowały się w węźle serwera, którego system operacyjny jest najlepiej przygotowany dla nich. Ta zasada jest kluczem do aranżacji obciążeń przedstawianych przez systemy takie jak Kubernetes.
Rejuvenation i rekonfiguracja
W systemach informacyjnych, w których wystąpienia oprogramowania są wdrażane przez dłuższy czas, może być konieczne ponowne uruchomienie tego oprogramowania. Niektóre starsze platformy w chmurze próbowały próbkować poziomy usług wystąpień oprogramowania w czasie, aby określić, kiedy ponowny rozruch stanie się konieczny, a później incarnations przyniesieł się do prostszej metody planowania okresowych ponownych uruchomień. Podczas tych etapów ponownego uruchamiania pliki konfiguracji mogą zostać automatycznie dostosowane do konta w celu zmiany warunków systemu lub zaniechania potencjalnego błędu po uruchomieniu.
Migracja zastępujące
Gdy Wirtualizacja najpierw stała się zszywaniem w centrach danych, zasugerowano migrację sprzed prewencyjne jako metodę wyrównywania obciążenia na sprzęcie serwera, obracając przydziały obciążeń do procesorów, na przykład w sposób okrężny. Platformy w chmurze dystrybuują ponownie obciążenia w ramach infrastruktury wirtualnej wystarczająco często, że ta metoda stała się niepotrzebna. Jednak temat został przycięty ponownie w ostatnich dyskusjach w połączeniu z sztucznie inteligentnymi metodami do przewidywania obciążeń obciążenia w różnych systemach informacyjnych. Takie systemy mogą obejmować własne reguły umożliwiające przechodzenie bardziej krytycznych obciążeń z węzłów serwera przewidywanych w celu zwiększenia prawdopodobieństwa awarii.
Samonaprawianie
W szeroko rozproszonym systemie informacji, takim jak usługa Content Delivery Network (CDN) lub platforma mediów społecznościowych, funkcje poszczególnych serwerów mogą być rozproszone na wielu adresach, zwykle w różnych lokalizacjach lub centrach danych. Sieć samonaprawiania sonduje różne połączenia w regularnych odstępach czasu (na przykład platformę zarządzania wydajnością) dla przepływu ruchu i czasu odpowiedzi. Za każdym razem, gdy występuje niezgodność wydajności, routery mogą przełączać żądania od podejrzanych składników, a ostatecznie zatrzymywać przepływ ruchu przez te składniki. Następnie stan operacyjny tego składnika może zostać przetestowany pod kątem oznak błędu. Składnik może następnie zostać ponownie uruchomiony, aby sprawdzić, czy zachowanie będzie nadal działać, i jest zwracany tylko do stanu aktywny, jeśli Diagnostyka nie ujawnia prawdopodobieństwa błędu. Ten typ zautomatyzowanej reakcji transakcyjnej jest nowoczesnym przykładem samonaprawiania w wysoce rozproszonych centrach danych.4
Planowanie procesów oparte na barter
Platforma w chmurze (obejmująca publiczne usługi oparte na chmurze, ale również może obejmować infrastrukturę lokalną) ma unikatowy dostęp do raportów własnych Stanów. Gdy Firma Amazon zaczęła implementować poprawiony model SaaS w 2009, inżynierowie opracowują koncepcję o nazwie planowanie wystąpień. W tym systemie dyskretny serwer proxy działający w imieniu klienta anonsuje wymagania dotyczące zasobów dla danego zadania i emituje rodzaj żądania ofert, w odniesieniu do węzłów serwera w całej platformie chmurowej. Każdy węzeł zgłasza własną funkcję w celu spełnienia wymagań oferty w zakresie czasu i zasobów. Najtańsze licytanty wygrywają w ramach kontraktu i wyznaczysz wystąpienie punktu (SI) dla zadania. Ten sposób planowania jest obecnie opcją dla elastycznej chmury obliczeniowej usługi Amazon.5
Informacje
Ioana, Cristescu. System odporny na błędy rekordów i powtórzeniu dla aplikacji wielowątkowych. Szkoła techniczna Cluj Napoca. http://scholar.harvard.edu/files/cristescu/files/paper.pdf.
Sidiroglou, Stelios, et al.ZAPEWNIJ: Automatyczne samonaprawiania oprogramowania przy użyciu punktów ratowniczych. Columbia University, 2009.
Kwon Yong-Chul, et al. Przetwarzanie strumienia odporne na uszkodzenia przy użyciu rozproszonego, zreplikowanego systemu plików. Association for Computing Machinery, marzec 2008. https://db.cs.washington.edu/projects/moirae/moirae-vldb08.pdf.
Yang, Chen. Punkt kontrolny i przywracanie mikrousług w kontenerach platformy Docker. School of Information Security Engineering, Shanghai Jiao Tong University, Chiny, 2015. https://download.atlantis-press.com/article/25844460.pdf.
Amazon Web Services, Inc. Wystąpienie typu spot żąda amazon, 2020. https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/spot-requests.html.