Konfigurowanie zestawu skalowania maszyn wirtualnych
Podczas skalowania dodajesz wystąpienia do zestawu skalowania maszyn wirtualnych. W scenariuszu firmy zajmującej się wysyłką skalowanie jest dobrym sposobem obsługi zmieniającej się liczby żądań w czasie. Skalowanie dostosowuje liczbę maszyn wirtualnych z uruchomioną aplikacją internetową w miarę zmian liczby użytkowników. Dzięki temu system zachowuje stały czas odpowiedzi niezależnie od bieżącego obciążenia.
W tej lekcji dowiesz się, jak skalować zestaw skalowania maszyn wirtualnych. Możesz skalować ręcznie przez jawne ustawienie liczby wystąpień maszyn wirtualnych w zestawie skalowania. Skalowanie automatyczne można skonfigurować, definiując reguły skalowania, które wyzwalają alokację i cofanie alokacji maszyn wirtualnych. Reguły skalowania monitorują różne metryki wydajności, aby określić, kiedy skalować system.
Ręczne skalowanie zestawów skalowania maszyn wirtualnych
Zestaw skalowania maszyn wirtualnych można skalować ręcznie, zwiększając lub zmniejszając liczbę wystąpień. To zadanie można wykonać programowo lub w witrynie Azure Portal.
Poniższy kod używa interfejsu wiersza polecenia platformy Azure do zmiany liczby wystąpień w zestawie skalowania maszyn wirtualnych:
az vmss scale \
--name webServerScaleSet \
--resource-group MyResourceGroup \
--new-capacity 6
Automatyczne skalowanie zestawów skalowania maszyn wirtualnych
Skalowanie ręczne jest przydatne w pewnych okolicznościach. Jednak w wielu sytuacjach autoskalowanie jest lepsze. Umożliwia systemowi sterowanie liczbą wystąpień w zestawie skalowania.
Autoskalowanie może być oparte na:
- Harmonogram: użyj tego podejścia, jeśli wiesz, że masz zwiększone obciążenie w określonym przedziale czasu lub dacie.
- Metryki: dostosuj skalowanie, monitorując metryki wydajności skojarzone z zestawem skalowania. Gdy te metryki przekroczą określony próg, zestaw skalowania może automatycznie uruchamiać nowe wystąpienia maszyn wirtualnych. Gdy metryki wskazują, że dodatkowe zasoby nie są już wymagane, zestaw skalowania może zatrzymać wszelkie nadmiarowe wystąpienia.
Definiowanie warunków, reguł i limitów autoskalowania
Skalowanie automatyczne jest oparte na zestawie warunków, reguł i limitów skalowania. Warunek skalowania łączy czas i zestaw reguł skalowania. Jeśli bieżąca godzina przypada w okresie zdefiniowanym w warunku skalowania, zostaną ocenione reguły skalowania warunku. Wyniki tej oceny określają, czy należy dodać czy usunąć wystąpienia w zestawie skalowania. Warunek skalowania definiuje również limity skalowania określające maksymalną i minimalną liczbę wystąpień.
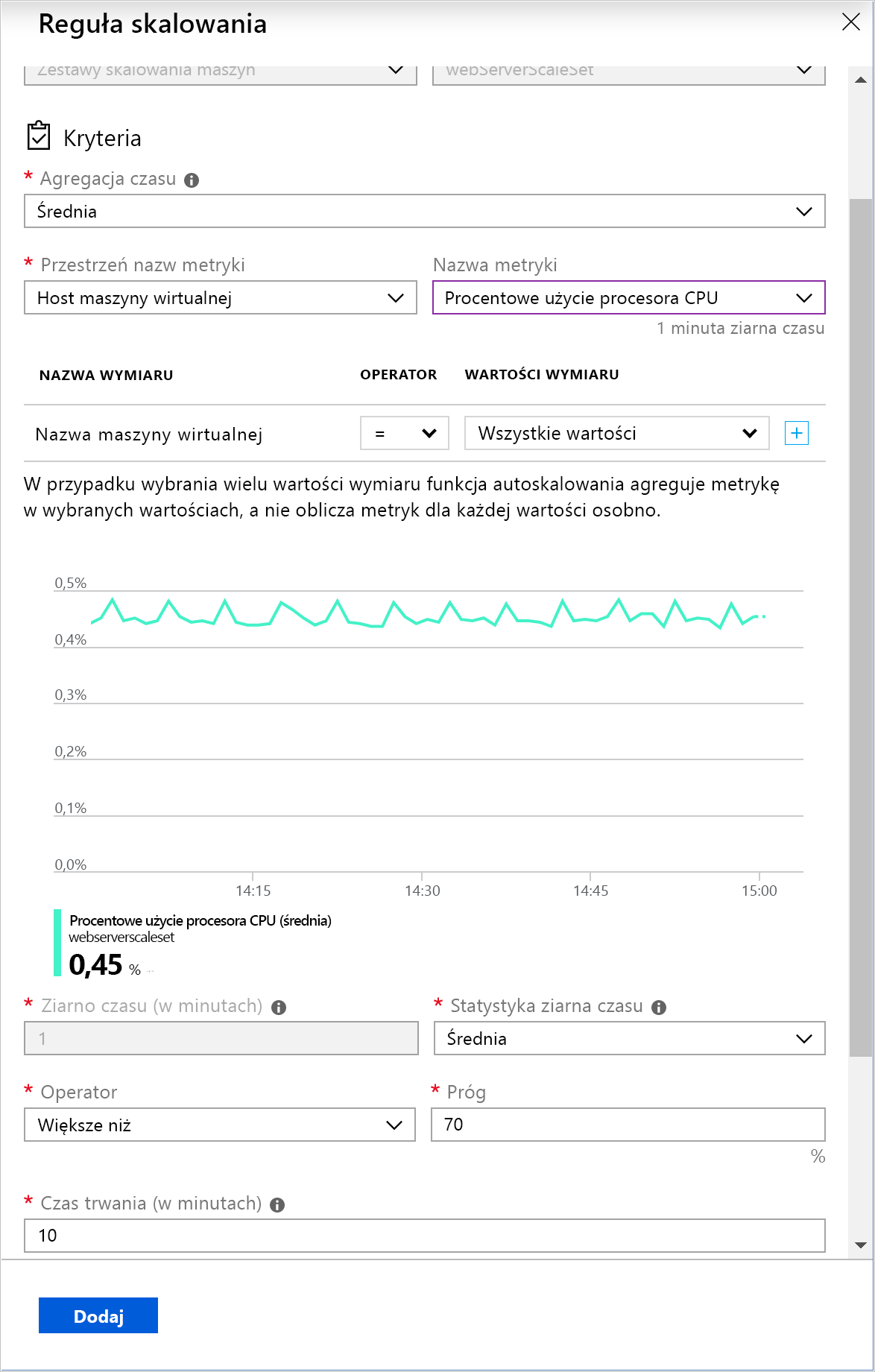
W scenariuszu firmy wysyłkowej można dodać reguły skalowania, które monitorują użycie procesora CPU w zestawie skalowania. Jeśli użycie procesora przekroczy próg 75%, reguła skalowania może zwiększyć liczbę wystąpień maszyn wirtualnych. Druga reguła skalowania może również monitorować użycie procesora CPU, ale zmniejszyć liczbę wystąpień maszyn wirtualnych, gdy użycie spadnie poniżej 50%. Ponieważ aplikacja jest globalna, te reguły powinny być aktywne przez cały czas, a nie tylko w określonych godzinach.
Zestaw skalowania maszyn wirtualnych może zawierać wiele warunków skalowania. Każdy pasujący warunek skalowania jest przetwarzany. Zestaw skalowania może również zawierać domyślny warunek skalowania, który ma być używany, jeśli żadne inne warunki skalowania nie pasują do bieżącego czasu i metryk wydajności. Domyślny warunek skalowania jest zawsze aktywny. Nie zawiera żadnych reguł skalowania, co skutecznie działa jak warunek skalowania o wartości null , który nie jest skalowany w poziomie ani w poziomie. Można jednak zmodyfikować domyślny warunek skalowania, aby ustawić domyślną liczbę wystąpień, lub dodać parę reguł skalowania, które są skalowane w poziomie i z powrotem.
Używanie autoskalowania opartego na harmonogramie
Skalowanie oparte na harmonogramie określa godzinę rozpoczęcia i zakończenia oraz liczbę wystąpień do dodania do zestawu skalowania. Poniższy zrzut ekranu przedstawia przykład w witrynie Azure Portal. Liczba wystąpień jest skalowana w poziomie do 20 między 6:00 a 18:00 co poniedziałek i środę. Poza tymi godzinami jest stosowany domyślny warunek skalowania, jeśli nie ma innych warunków skalowania.
W tym przypadku reguła domyślna powoduje skalowanie systemu z powrotem do dwóch wystąpień. Ta wartość to maksimum w domyślnym warunku skalowania.

Używanie autoskalowania opartego na metrykach
Reguła skalowania oparta na metrykach określa zasoby do monitorowania, takie jak użycie procesora lub czas odpowiedzi. Ta reguła skalowania dodaje lub usuwa wystąpienia w zestawie skalowania zgodnie z wartościami metryk. Możesz określić limity liczby wystąpień, aby zapobiec nadmiernemu skalowaniu zestawu skalowania w poziomie lub w poziomie.
W przykładowym scenariuszu liczba wystąpień jest zwiększana o 1, gdy średnie użycie procesora przekracza 75%. Ponadto należy ograniczyć operację zwiększania skali w poziomie do 50 wystąpień. Ten limit może pomóc w uniknięciu kosztownego niekontrolowanego skalowania spowodowanych przez atak. Podobnie, należy zmniejszyć skalę w poziomie, gdy średnie użycie procesora spadnie poniżej 50%.
Te metryki są często używane do monitorowania zestawu skalowania maszyn wirtualnych:
- Procentowe użycie procesora CPU: ta metryka wskazuje użycie procesora CPU we wszystkich wystąpieniach. Wysoka wartość pokazuje, że wystąpienia stają się zależne od obciążonego procesora, co może spowodować opóźnienia przetwarzania żądań klientów.
- Przepływy przychodzące i przepływy wychodzące: te metryki pokazują, jak szybki ruch sieciowy przepływa do i z maszyn wirtualnych w zestawie skalowania.
- Operacje odczytu/s dysków i operacje zapisu na dysku/s: Te metryki pokazują ilość operacji we/wy dysku w zestawie skalowania.
- Głębokość kolejki dysku danych: ta metryka pokazuje liczbę żądań we/wy tylko do dysków danych na maszynach wirtualnych oczekujących na obsługę.
Reguła skalowania agreguje wartości pobrane dla metryki dla wszystkich wystąpień. Agreguje ona wartości w okresie nazywanym ziarnem czasu. Każda metryka ma swoje własne ziarno czasu, ale w większości przypadków ten okres to jedna minuta. Zagregowana wartość jest nazywana agregacją czasu. Opcje agregacji czasu to średnia, minimalna, maksymalna, łącznie, ostatnia i liczba.
Jedna minuta to zbyt krótki okres na określenie, czy zmiana metryki jest wystarczająco długotrwała, aby autoskalowanie było opłacalne. Reguła skalowania wykonuje drugi krok, dalej agregując wartość agregacji czasu w dłuższym okresie podanym przez użytkownika. Ten okres jest nazywany czasem trwania. Minimalny czas trwania wynosi 5 minut. Jeśli na przykład czas trwania jest ustawiony na 10 minut, reguła autoskalowania będzie agregowała 10 wartości obliczonych dla ziarna czasu.
Obliczanie agregacji czasu trwania może różnić się od obliczania agregacji ziarna czasu. Załóżmy na przykład, że agregacja czasu jest oparta na wartości średniej, a zebrana statystyka to procentowa zajętość procesora dla jednominutowego ziarna czasu. Dla każdej minuty obliczane jest średnie użycie procentowe procesora CPU we wszystkich wystąpieniach w tej minucie. Jeśli statystyka ziarna czasu jest ustawiona na wartość maksymalną, a czas trwania reguły jest ustawiony na 10 minut, maksymalna z 10 wartości średnich procentowego użycia procesora określa, czy próg reguły został przekroczony.
Gdy reguła skalowania wykryje, że metryka przekroczy próg, może wykonać akcję skalowania. Akcją skalowania może być zwiększenie skali w poziomie lub zmniejszenie skali w poziomie. Akcja zwiększania skali w poziomie zwiększa liczbę wystąpień. Akcja zmniejszania skali w poziomie zmniejsza liczbę wystąpień.
Akcja skalowania korzysta z operatora (takiego jak mniejsze niż, większe niż lub równe) w celu określenia sposobu reagowania na wartość progową. Akcje zwiększania skali w poziomie zwykle porównują wartość metryki z progiem przy użyciu operatora większe niż. Akcje zmniejszania skali w poziomie najczęściej porównują wartość metryki z progiem za pomocą operatora mniejsze niż. Akcja skalowania powoduje też ustawienie liczby wystąpień na określony poziom zamiast przyrostowo zwiększać lub zmniejszać dostępną liczbę.
Akcja skalowania ma okres ochładzania, określany w minutach. W tym okresie reguła skalowania nie zostanie wyzwolona ponownie. Ochłodzenie pozwala na ustabilizowanie systemu między zdarzeniami skalowania. Uruchomienie lub zamknięcie wystąpienia chwilę trwa, a więc zbierane metryki mogą nie pokazywać znaczących zmian przez kilka minut. Minimalny okres ochładzania wynosi pięć minut.
Na koniec należy zaplanować skalowanie w poziomie, gdy obciążenie spadnie. Rozważ zdefiniowanie reguł skalowania w parach w tym samym warunku skalowania. Jedna reguła skalowania powinna wskazywać, jak zwiększać skalę systemu w poziomie, kiedy metryka przekroczy górny próg. Druga reguła musi definiować sposób ponownego zmniejszania skali systemu w poziomie, kiedy ta sama metryka spadnie poniżej dolnego progu. Nie należy określać takich samych wartości dla obu progów. W przeciwnym razie można wyzwolić serię oscylacyjnych zdarzeń, które są skalowane w poziomie i z powrotem.
Na następującej ilustracji przedstawiono regułę skalowania zdefiniowaną przy użyciu witryny Azure Portal.