Ćwiczenie — skalowanie wydajności obciążenia
W tym ćwiczeniu wykonasz problem napotkany w pierwszym ćwiczeniu i poprawisz wydajność, skalując więcej procesorów CPU dla usługi Azure SQL Database. Użyjesz bazy danych wdrożonej w poprzednim ćwiczeniu.
Wszystkie skrypty dla tego ćwiczenia można znaleźć w folderze 04-Performance\monitor_and_scale w sklonowanym repozytorium GitHub lub pobranym pliku zip.
Skalowanie w górę wydajności usługi Azure SQL
Aby skalować wydajność dla problemu, który wydaje się być problemem z wydajnością procesora CPU, należy ustalić, jakie są dostępne opcje, a następnie przeskalować procesory CPU przy użyciu podanych interfejsów dla usługi Azure SQL.
Ustal sposób skalowania wydajności. Ponieważ obciążenie jest powiązane z procesorem CPU, jednym ze sposobów zwiększenia wydajności jest zwiększenie pojemności procesora CPU lub szybkości. Użytkownik programu SQL Server musi przejść do innej maszyny lub ponownie skonfigurować maszynę wirtualną w celu uzyskania większej wydajności procesora. W niektórych przypadkach nawet administrator programu SQL Server może nie mieć uprawnień do wprowadzania tych zmian skalowania. Ten proces może zająć dużo czasu, a nawet wymagać migracji bazy danych.
W przypadku platformy Azure możesz użyć
ALTER DATABASEinterfejsu wiersza polecenia platformy Azure lub witryny Azure Portal, aby zwiększyć pojemność procesora CPU bez migracji bazy danych ze strony użytkownika.W witrynie Azure Portal można zobaczyć opcje możliwego skalowania w celu uzyskania większej ilości zasobów procesora CPU. W okienku Przegląd bazy danych wybierz warstwę cenowądla bieżącego wdrożenia. Warstwa Ceny umożliwia zmianę warstwy usługi i liczby rdzeni wirtualnych.
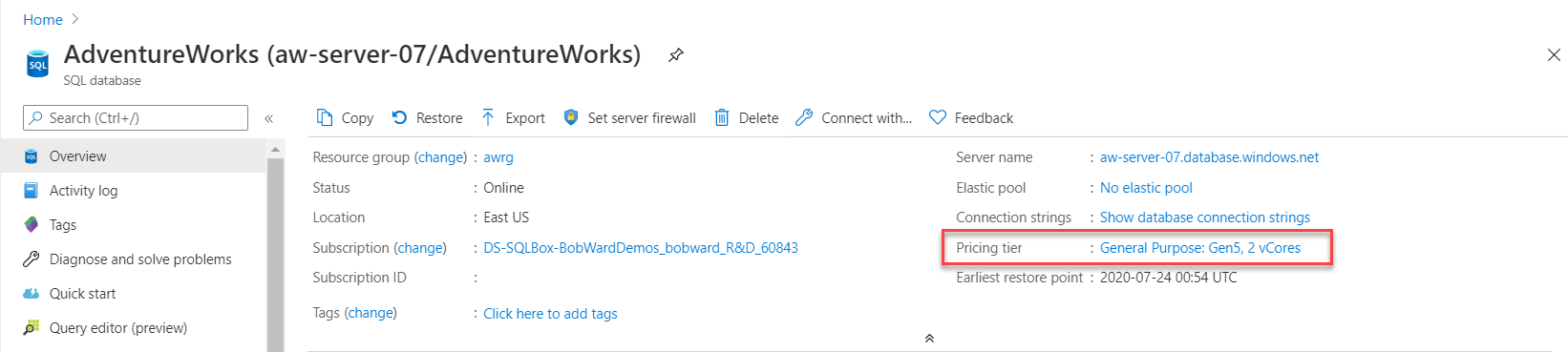
Tutaj można zobaczyć opcje zmiany lub skalowania zasobów obliczeniowych. W przypadku opcji Ogólnego przeznaczenia można łatwo skalować w górę do około 8 rdzeni wirtualnych.
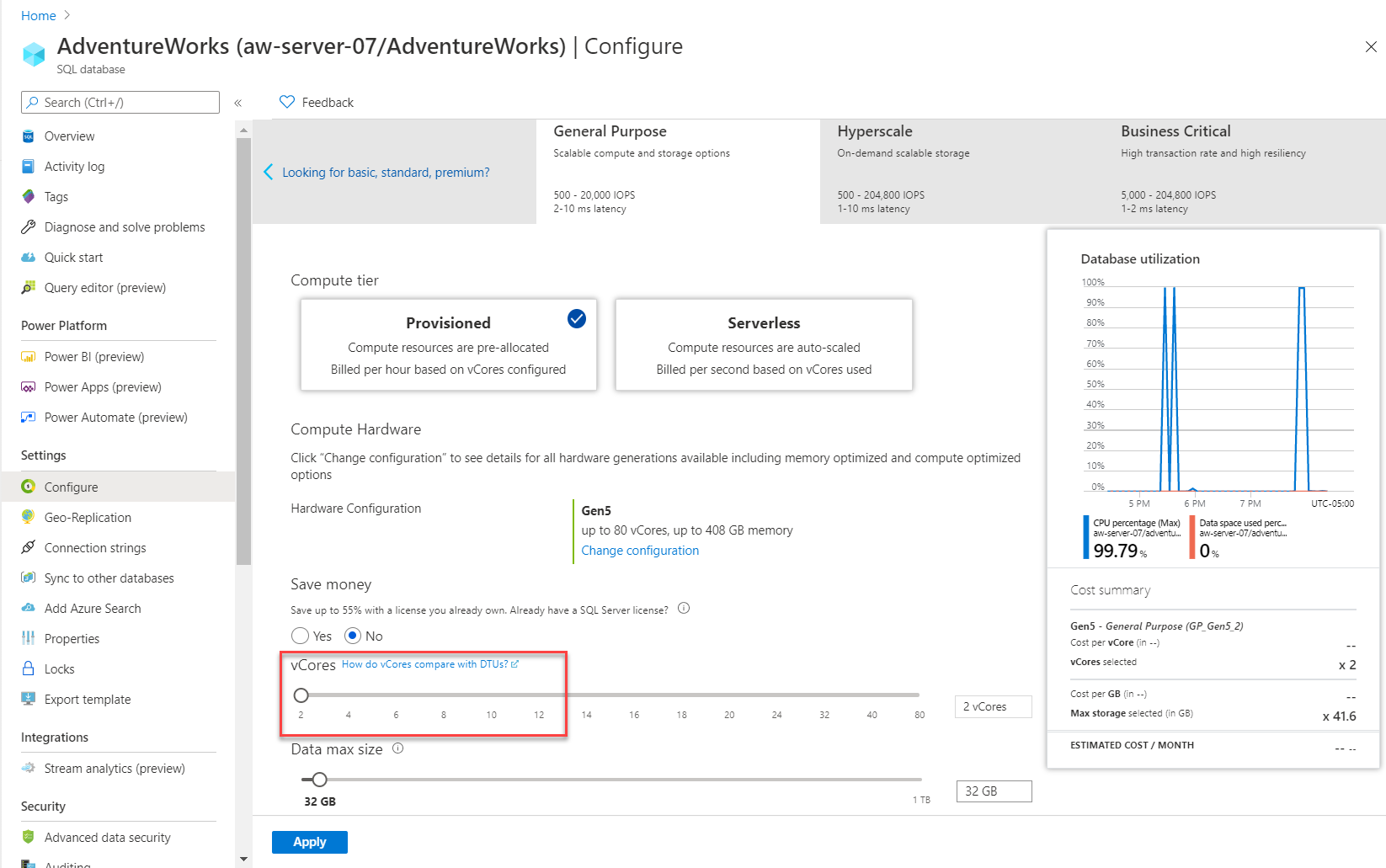
Możesz również użyć innej metody do skalowania obciążenia.
W tym ćwiczeniu należy najpierw opróżnić magazyn zapytań, aby można było zobaczyć w raportach odpowiednie różnice. W programie SQL Server Management Studio (SSMS) wybierz bazę danych AdventureWorks i użyj menu Otwórz>>. Otwórz skrypt flushhquerystore.sql w programie SSMS w kontekście bazy danych AdventureWorks. Tekst w oknie edytora zapytań powinien wyglądać następująco:
EXEC sp_query_store_flush_db;Wybierz pozycję Wykonaj , aby uruchomić tę partię języka T-SQL.
Uwaga
Uruchomienie poprzedniego zapytania opróżnia część danych magazynu zapytań na dysku w pamięci.
Otwórz skrypt get_service_objective.sql w programie SSMS. Tekst w oknie edytora zapytań powinien wyglądać następująco:
SELECT database_name,slo_name,cpu_limit,max_db_memory, max_db_max_size_in_mb, primary_max_log_rate,primary_group_max_io, volume_local_iops,volume_pfs_iops FROM sys.dm_user_db_resource_governance; GO SELECT DATABASEPROPERTYEX('AdventureWorks', 'ServiceObjective'); GOJest to metoda znajdowania warstwy usługi przy użyciu języka T-SQL. Warstwa cenowa lub warstwa usługi jest także nazywana celem usługi. Wybierz pozycję Wykonaj , aby uruchomić partie języka T-SQL.
W przypadku bieżącego wdrożenia usługi Azure SQL Database wyniki powinny wyglądać jak na poniższej ilustracji:
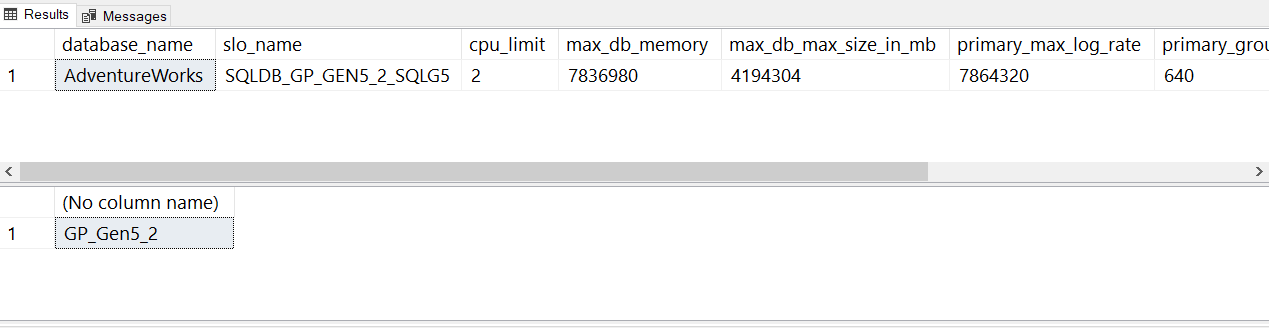
Zwróć uwagę, że termin slo_name jest również używany dla celu usługi. Skrót slo oznacza service level objective (cel poziomu usługi).
Różne
slo_namewartości nie są udokumentowane, ale można zobaczyć na podstawie wartości ciągu, która ta baza danych używa warstwy usługi ogólnego przeznaczenia z dwoma rdzeniami wirtualnymi:Uwaga
SQLDB_OP_...to ciąg używany dla warstwy Krytyczne dla działania firmy.Podczas przeglądania dokumentacji polecenia ALTER DATABASE zwróć uwagę na możliwość wyboru wdrożenia docelowego programu SQL Server w celu uzyskania prawidłowych opcji składni. Wybierz pojedynczą bazę danych/elastyczną pulę usługi SQL Database, aby wyświetlić opcje dla usługi Azure SQL Database. Aby dopasować skalę obliczeniową znalezioną w portalu, potrzebny jest cel
'GP_Gen5_8'usługi .Zmodyfikuj cel usługi dla bazy danych, aby skalować więcej procesorów CPU. Otwórz skrypt modify_service_objective.sql w programie SSMS i uruchom partię T-SQL. Tekst w oknie edytora zapytań powinien wyglądać następująco:
ALTER DATABASE AdventureWorks MODIFY (SERVICE_OBJECTIVE = 'GP_Gen5_8');Ta instrukcja natychmiast zwraca odpowiedź, ale skalowanie zasobów obliczeniowych odbywa się w tle. Tak małe skalowanie powinno trwać krócej niż minutę i przez krótki czas, w celu wprowadzenia zmiany, baza danych jest offline. Możesz monitorować postęp tego działania skalowania przy użyciu witryny Azure Portal.
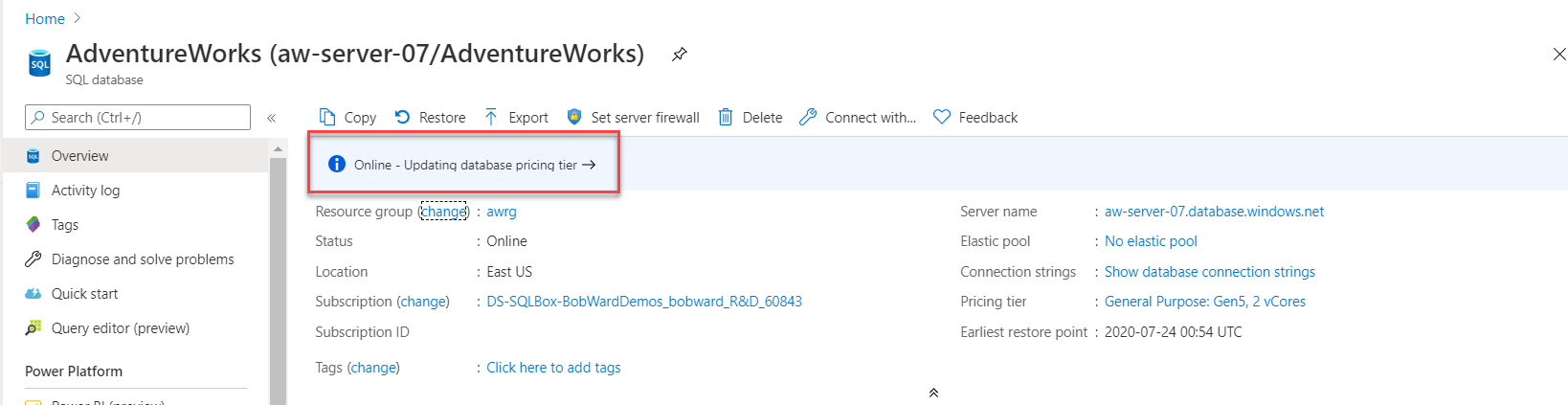
W Eksploratorze obiektów w folderze Systemowe bazy danych kliknij prawym przyciskiem myszy bazę danych master i wybierz pozycję Nowe zapytanie. Uruchom to zapytanie w oknie edytora zapytań programu SSMS:
SELECT * FROM sys.dm_operation_status;Jest to inny sposób monitorowania postępu zmieniania celu usługi dla usługi Azure SQL Database. Ten dynamiczny widok zarządzania (DMV) przedstawia historię zmian w bazie danych przy użyciu polecenia ALTER DATABASE względem celu usługi. Pokazuje to aktywne postępy zmiany.
Poniżej znajduje się przykład danych wyjściowych tego dynamicznego widoku zarządzania w formacie tabeli po uruchomieniu powyższej instrukcji ALTER DATABASE:
Towar Wartość session_activity_id 97F9474C-0334-4FC5-BFD5-337CDD1F9A21 resource_type 0 resource_type_desc baza danych major_resource_id AdventureWorks minor_resource_id rozdzielnicy ALTER DATABASE stan 1 state_desc IN_PROGRESS percent_complete 0 error_code 0 error_desc error_severity 0 error_state 0 start_time [data i godzina] last_modify_time [data i godzina] Podczas zmieniania celu usługi zapytania dotyczące bazy danych są dozwolone do momentu zaimplementowania ostatecznej zmiany. Aplikacja nie może się połączyć przez krótki czas. W przypadku usługi Azure SQL Managed Instance zmiana warstwy zezwala na zapytania i połączenia, ale uniemożliwia wykonywanie wszystkich operacji bazy danych, takich jak tworzenie nowych baz danych. W takich przypadkach zostanie wyświetlony następujący komunikat o błędzie: "Nie można ukończyć operacji, ponieważ zmiana warstwy usługi jest w toku dla wystąpienia zarządzanego "[serwer]". Poczekaj na zakończenie trwającej operacji i spróbuj ponownie”.
Po wykonaniu tej czynności użyj powyższych zapytań wymienionych z get_service_objective.sql w programie SSMS, aby sprawdzić, czy nowy cel usługi lub warstwa usługi 8 rdzeni wirtualnych została w życie.
Uruchamianie obciążenia po skalowaniu w górę
Baza danych ma teraz większą pojemność w zakresie procesora. Uruchomimy obciążenie z poprzedniego ćwiczenia, aby sprawdzić, czy wydajność uległa poprawie.
Po zakończeniu skalowania sprawdź, czy czas trwania obciążenia i czas oczekiwania na zasoby procesora są krótsze. Uruchom ponownie obciążenie przy użyciu polecenia sqlworkload.cmd uruchomionego w poprzednim ćwiczeniu.
Za pomocą programu SSMS uruchom to samo zapytanie co w pierwszym ćwiczeniu tego modułu, aby zaobserwować wyniki skryptu dmdbresourcestats.sql:
SELECT * FROM sys.dm_db_resource_stats;Z wyświetlonych informacji powinno wynikać, że średnie użycie zasobów procesora zmniejszyło się z prawie 100 procent w poprzednim ćwiczeniu.
sys.dm_db_resource_statsZwykle wyświetla jedną godzinę działania. Zmiana rozmiaru bazy danych powodujesys.dm_db_resource_statszresetowanie.Za pomocą programu SSMS uruchom to samo zapytanie co w pierwszym ćwiczeniu tego modułu, aby zaobserwować wyniki skryptu dmexecrequests.sql.
SELECT er.session_id, er.status, er.command, er.wait_type, er.last_wait_type, er.wait_resource, er.wait_time FROM sys.dm_exec_requests er INNER JOIN sys.dm_exec_sessions es ON er.session_id = es.session_id AND es.is_user_process = 1;Zobaczysz, że istnieje więcej zapytań o stanie RUNNING. Oznacza to, że procesy robocze mają więcej pojemności procesora na potrzeby wykonywania.
Zwróć uwagę na nowy czas trwania obciążenia. Czas trwania obciążenia z polecenia sqlworkload.cmd powinien być teraz znacznie krótszy i wynosić około 25–30 sekund.
Obserwowanie raportów magazynu zapytań
Przyjrzyjmy się tym samym raportom magazynu zapytań, które oglądaliśmy w poprzednim ćwiczeniu.
Korzystając z tych samych technik co w pierwszym ćwiczeniu w tym module, przyjrzyj się raportowi dotyczącemu najważniejszych zapytań zużywających zasoby z programu SSMS:
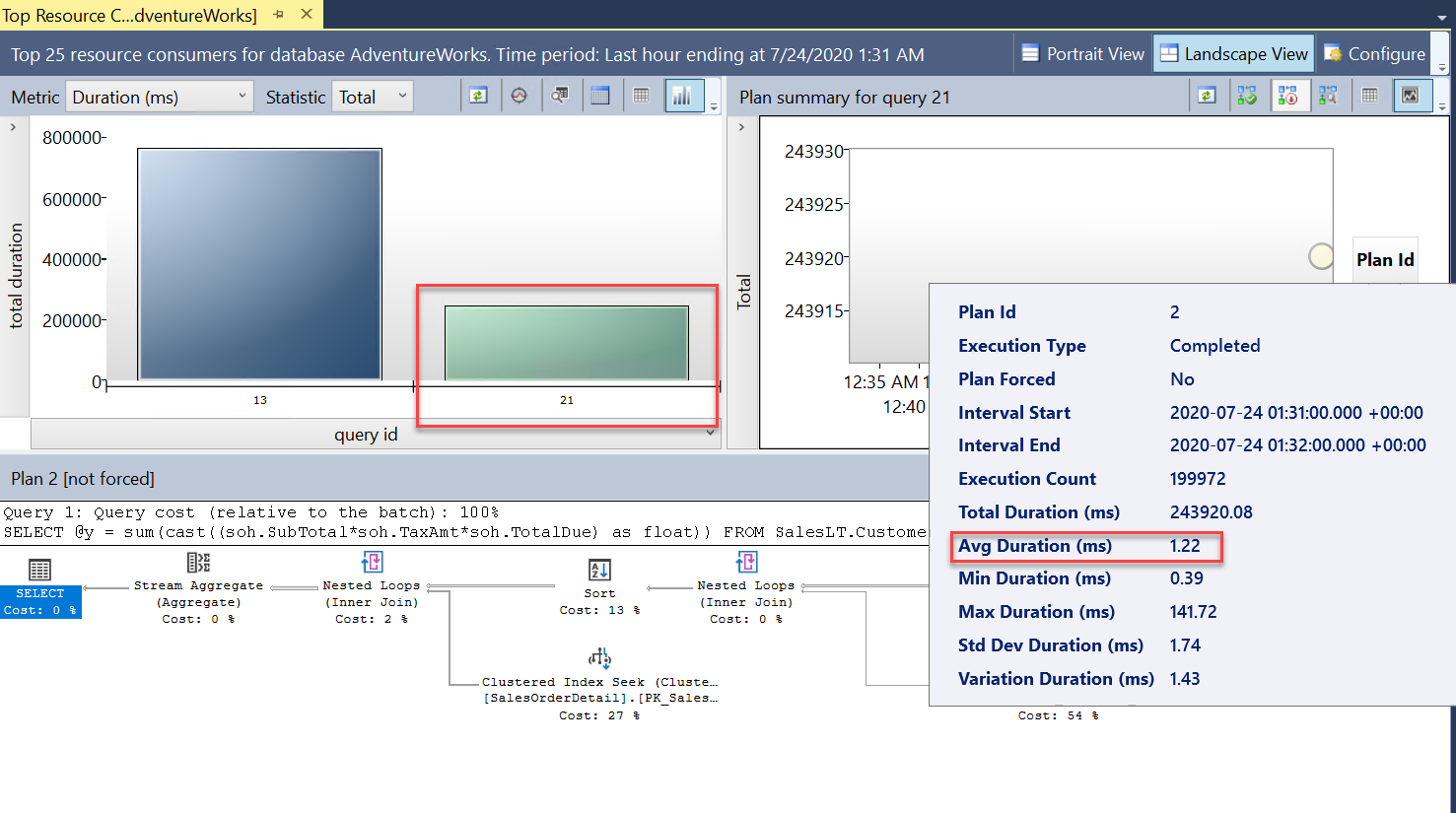
Zobaczysz teraz dwa zapytania (
query_id). Jest to to samo zapytanie, ale jest ono wyświetlane z różnymi wartościamiquery_idw magazynie zapytań, ponieważ operacja skalowania wymagała ponownego uruchomienia i ponownego skompilowania zapytania. Z raportu wynika, że ogólny i średni czas trwania są znacznie krótsze.Zapoznaj się również z raportem Statystyki oczekiwania zapytań i wybierz pasek oczekiwania procesora CPU. Jak widać, ogólny średni czas oczekiwania na zapytanie jest krótszy i stanowi mniejszą część ogólnego czasu trwania. Wskazuje to, że procesor nie stanowi już tak istotnego wąskiego gardła dla zasobów, jak wtedy, gdy baza danych miała mniejszą liczbę rdzeni wirtualnych:
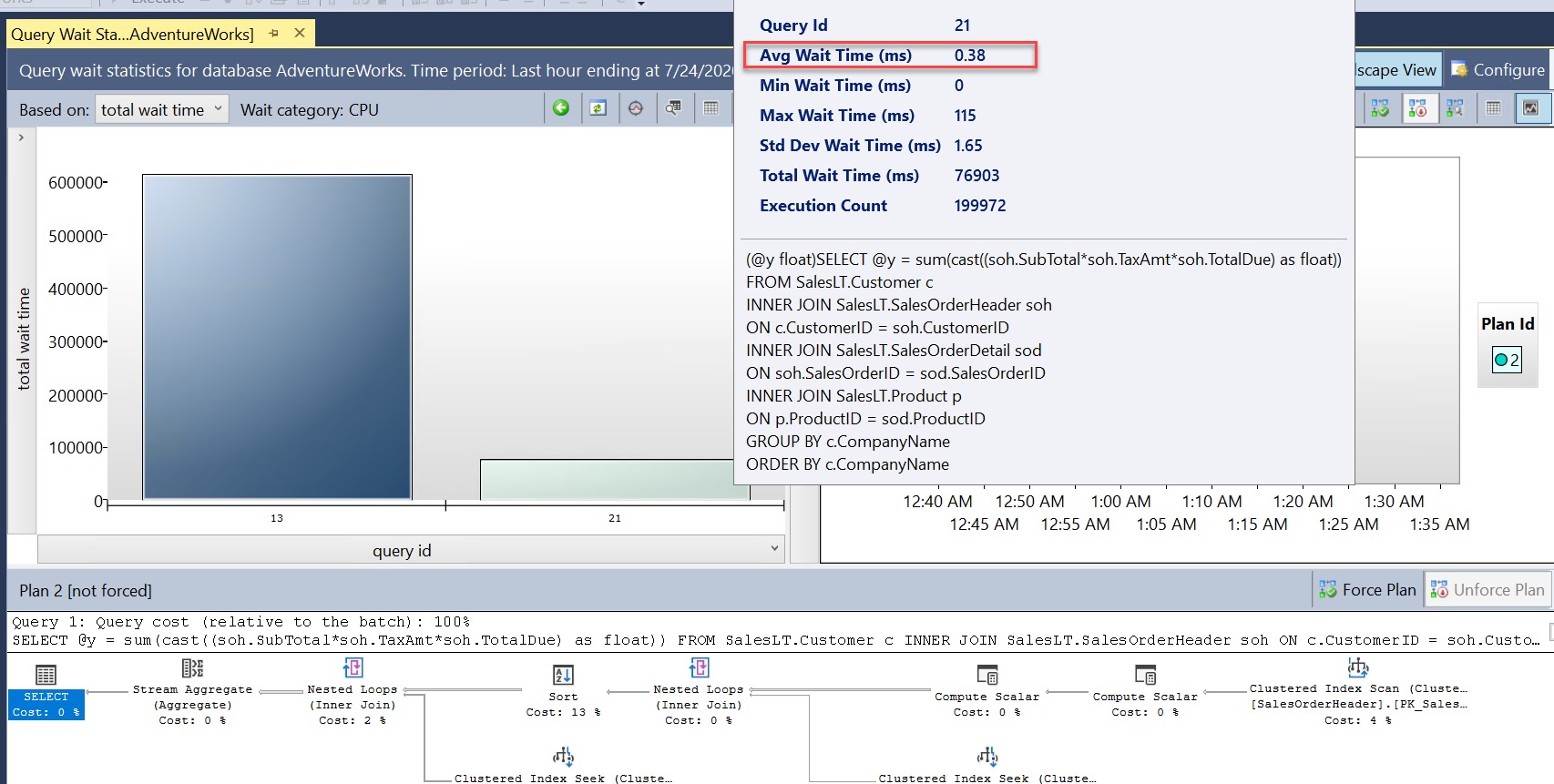
Możesz zamknąć wszystkie raporty i okna edytora zapytań. Pozostaw połączenie programu SSMS, ponieważ będzie on potrzebny w następnym ćwiczeniu.
Obserwowanie zmian w metrykach platformy Azure
Przejdź do bazy danych AdventureWorks w witrynie Azure Portal i ponownie przyjrzyj się karcie Monitorowanie w okienku Przegląd pod kątem wykorzystania zasobów obliczeniowych:
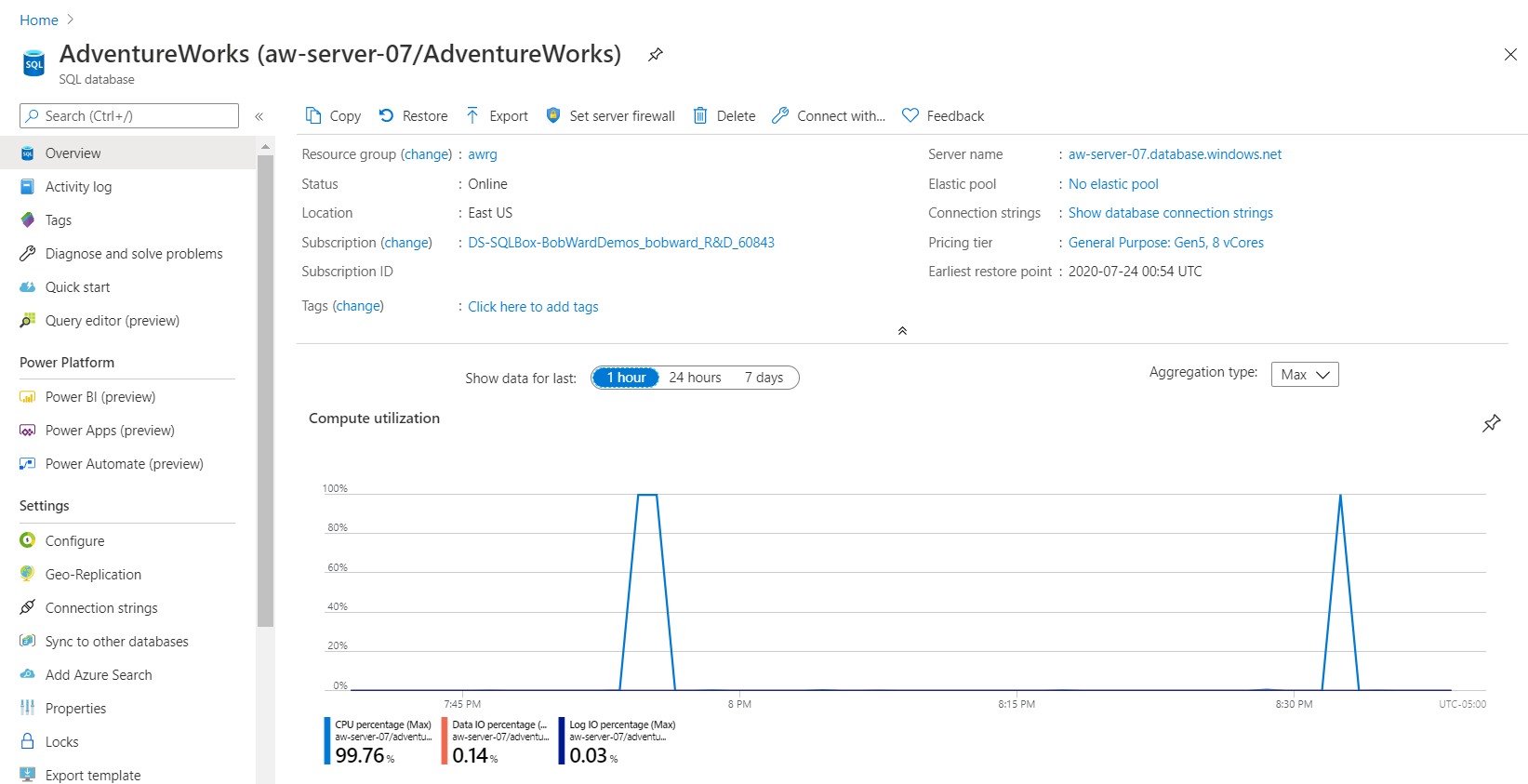
Zauważ, że czas trwania jest krótszy w przypadku dużego użycia procesora, co wskazuje na ogólny spadek ilości zasobów procesora wymaganych do uruchomienia obciążenia.
Ten wykres może być nieco mylący. W menu Monitorowanie użyj pozycji Metryki, a następnie ustaw wartość Metryka na limit procesora CPU. Wykres porównawczy procesora CPU wygląda mniej więcej tak:
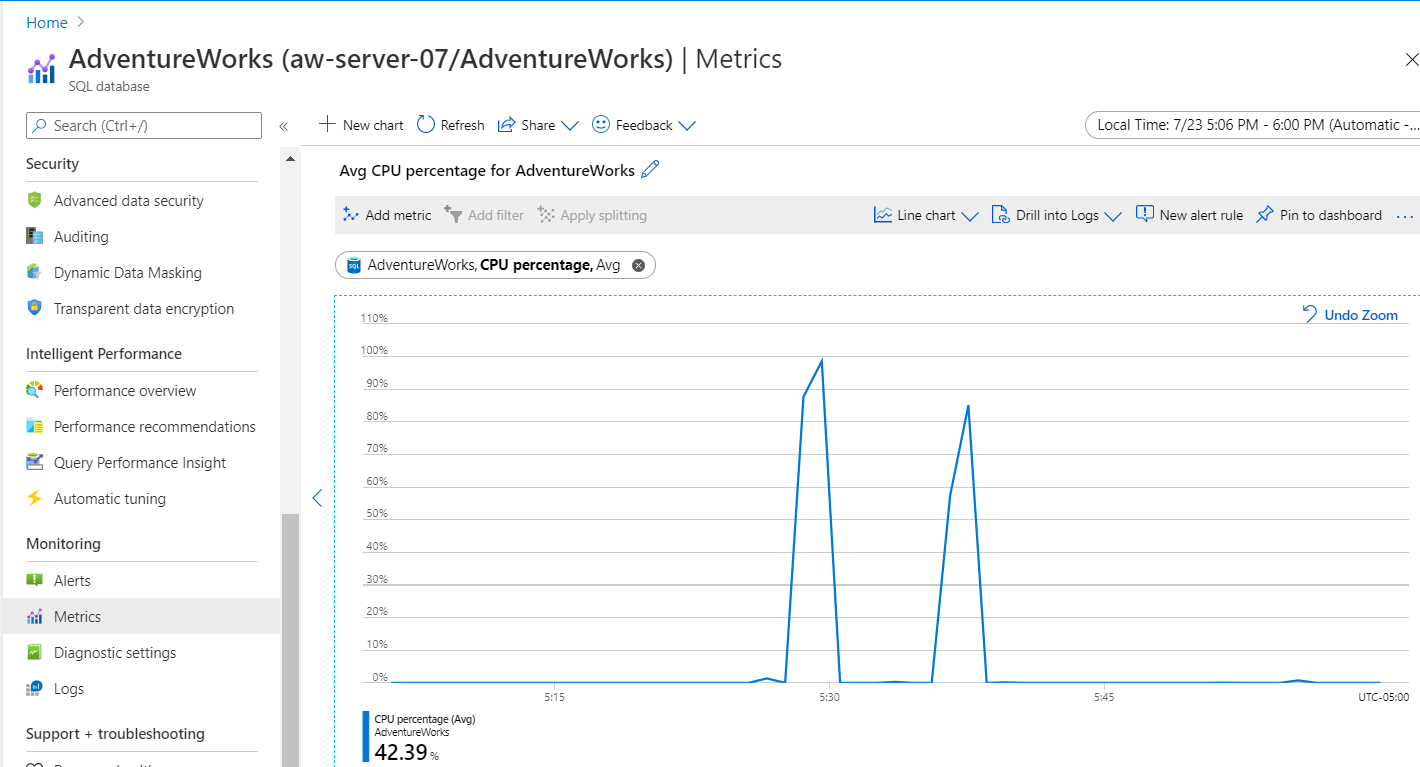
Napiwek
W przypadku dalszego zwiększania liczby rdzeni wirtualnych dla tej bazy danych można zwiększać wydajność do progu, po przekroczeniu którego wszystkie zapytania będą miały mnóstwo zasobów procesora. Nie oznacza to, że trzeba używać tylu rdzeni wirtualnych, ilu jest użytkowników równocześnie korzystających z obciążenia. Ponadto można zmienić warstwę cenową tak, aby korzystała z warstwy obliczeniowej bezserwerowejzamiast aprowizacji. Dzięki temu można osiągnąć bardziej skalowane automatycznie podejście do obciążenia. Jeśli na przykład wybrano minimalną wartość 2 rdzeni wirtualnych dla tego obciążenia i maksymalną wartość 8 rdzeni wirtualnych, to obciążenie będzie natychmiast skalowane do 8 rdzeni wirtualnych.
W następnym ćwiczeniu zaobserwujesz problem z wydajnością i rozwiążesz go, stosując najlepsze rozwiązania dotyczące wydajności aplikacji.