Ćwiczenie — tworzenie modelu kondycji aplikacji
Firma Contoso Shoes potrzebuje sposobu wykrywania, diagnozowania i przewidywania problemów w tej architekturze. Chcesz utworzyć model kondycji, który jest wymierny za pomocą stanu kondycji zastosowanego do przepływów użytkownika i systemu. Celem jest zidentyfikowanie potencjalnych punktów awarii, zanim spowodują awarię.
Bieżący stan i problem
Do tej pory dodano interfejs API sprawdzania kondycji i utworzono funkcje wieloregionowe w architekturze. Nie ma jednak możliwości uzyskania wglądu w złożoną topologię obejmującą przepływy użytkowników i systemu. Należy wypełnić tę lukę, aby zespół SRE mógł szybko identyfikować i rozwiązywać problemy.
W niedawnym zdarzeniu zespół nie mógł zobaczyć kaskadowego wpływu problemu wynikającego ze składnika interfejsu API wpływającego na jego zależności platformy. W rozwiązywaniu problemów było dużo czasu, ponieważ nie można od razu zauważyć składnika w złej kondycji. Ostatecznie nieefektywność ta doprowadziła do dłuższych przestojów, co spowodowało utratę finansową firmy.
Specyfikacja
Zaprojektuj model kondycji, który pokazuje relację między wszystkimi składnikami architektury, w tym składnikami aplikacji i zależnościami platformy. Uwzględnianie elementów istniejących w przepływie żądania, w tym bramy, obliczeń, baz danych, magazynu, pamięci podręcznych itd. Obejmują również składniki, które zwykle istnieją poza przepływem żądania. Na przykład artefakty Open Container Initiative (OCI), magazyny wpisów tajnych, usługi konfiguracji i inne. Wszystkie usługi platformy Azure muszą być skonfigurowane do wysyłania danych diagnostycznych.
Dodaj ujednolicony ujście danych w architekturze na potrzeby zbierania danych z różnych źródeł.
Zdefiniuj ogólny stan kondycji na podstawie zagregowanych dzienników historycznych i metryk. Reprezentuje stan w jednym z trzech stanów kondycji: w złej kondycji, obniżonej wydajności i dobrej kondycji.
Wizualizowanie stanu kondycji wszystkich składników w hierarchii reprezentującej wszystkie przepływy.
Zalecane podejście
Aby rozpocząć projektowanie, zalecamy wykonanie następujących kroków:
Ważne
Modelowanie kondycji to kompleksowe ćwiczenie. Podejście w tej sekcji ma pomóc w rozpoczęciu pracy. Rozbudowane stosowanie modelu do wszystkich przepływów funkcjonalnych i niefunkcjonalnych w projekcie o krytycznym znaczeniu w celu uzyskania całościowego widoku systemu.
1 — Rozpoczynanie modelowania kondycji
To ćwiczenie jest teoretyczne. Modelowanie kondycji w działaniu projektowania najwyższego poziomu, w którym potrzebna będzie kompleksowa lista składników używanych w architekturze. Ta lista powinna zawierać wszystkie składniki aplikacji i usługi platformy Azure.
Umieść te składniki na grafie zależności, który pokazuje hierarchiczny widok rozwiązania. Warstwa górna zawiera przepływy użytkownika, które śledzą żądania od użytkownika końcowego do witryny internetowej i przepływa na poziomie interfejsu API aplikacji. Warstwa dolna zawiera przepływy systemowe z usług platformy Azure. Mapuj również zależności między zasobami platformy Azure.
Wykres powinien wyglądać mniej więcej tak:
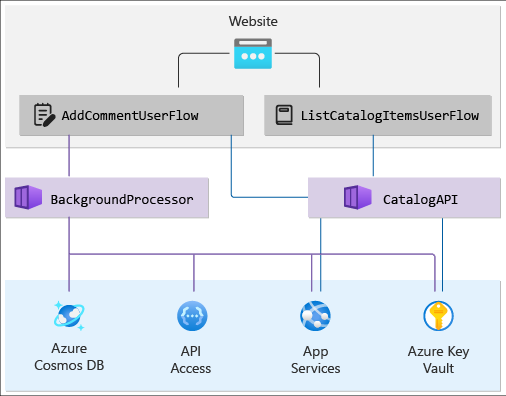
Sprawdzanie postępu: kondycja aplikacji warstwowej
2 — Definiowanie wyników kondycji
Dla każdego składnika zbierz metryki i progi metryk, a następnie określ wartość, w której składnik powinien być uznawany za w dobrej kondycji, obniżonej wydajności i złej kondycji. Ta decyzja powinna mieć wpływ na oczekiwaną wydajność i niefunkcjonalne wymagania biznesowe. Kategoryzuj metryki jako:
Metryki aplikacji: punkty danych z kodu aplikacji, takie jak liczba wyjątków.
Metryki usługi: punkty danych z usług platformy Azure, takie jak używane jednostki DTU (Database Transaction Units).
Metryki rozwiązania: punkty danych na poziomie rozwiązania, takie jak czas kompleksowego przetwarzania żądania.
Oto przykład dla usług aplikacja systemu Azure:
| App Services | Kondycja |
|---|---|
| Czas < odpowiedzi 200 ms — błędy < serwera HTTP 2 |

|
| Czas < odpowiedzi 500 ms — błędy < serwera HTTP 2 |

|
| Czas > odpowiedzi 500 ms — błędy > serwera HTTP 2 |

|
3 — Definiowanie ogólnego stanu kondycji
Dla każdego przepływu użytkownika i systemu zdefiniuj ogólny stan. Należy zagregować stan kondycji poszczególnych składników, które uczestniczą w tym przepływie.
Załóżmy, że przepływ systemu składa się ze składnika aplikacji, planu usługi aplikacja systemu Azure i usługi App Services.
| interfejs API | Plan usługi App Service | App Services | Kondycja |
|---|---|---|---|
| Maksymalne opóźnienie < 30 ms | Procesor CPU % < 70% długości < kolejki HTTP 5 |
Czas < odpowiedzi 200 ms — błędy < serwera HTTP 2 |
|
| Maksymalne opóźnienie < 30 ms | Procesor CPU % < 90% długości < kolejki HTTP 5 |
Czas < odpowiedzi 500 ms — błędy < serwera HTTP 2 |
|
| Maksymalne opóźnienie > 30 ms | Procesor CPU % > 90% długości > kolejki HTTP 5 |
Czas > odpowiedzi 500 ms — błędy > serwera HTTP 2 |
|
Wynik kondycji przepływu użytkownika powinien być reprezentowany przez najniższy wynik we wszystkich zamapowanych składnikach. W przypadku przepływów systemowych zastosuj odpowiednie wagi na podstawie krytycznego działania firmy. Między dwoma przepływami należy określić priorytety przepływów użytkowników o znaczeniu finansowym lub przepływach użytkowników przeznaczonych dla klientów.
Sprawdzanie postępu: Przykład — model kondycji warstwowej
4 — Zbieranie danych monitorowania
Potrzebny będzie ujednolicony ujście danych w każdym regionie, który zbiera dzienniki i metryki dla wszystkich usług aplikacji i platform wdrożonych w ramach sygnatury regionalnej. Potrzebujesz innego ujścia do przechowywania metryk emitowanych z zasobów globalnych, takich jak Azure Front Door i Cosmos DB.
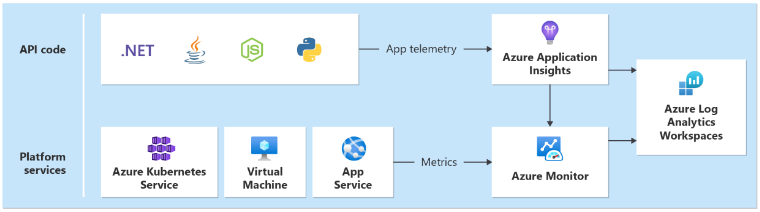
Wybór technologi
- aplikacja systemu Azure Insights: służy do zbierania wszystkich danych telemetrycznych aplikacji.
- Dzienniki usługi Azure Monitor: zbiera dane wysyłane przez usługę Application Insights i metryki platformy dla usług platformy Azure.
- Azure Log Analytics: służy jako centralne narzędzie do analizowania dzienników i metryk ze wszystkich składników aplikacji i infrastruktury.
Sprawdzanie postępu: Ujednolicony ujście danych na potrzeby skorelowanej analizy
5 — Konfigurowanie zapytań dotyczących danych monitorowania
język zapytań Kusto (KQL) jest dobrze zintegrowana z usługą Log Analytics. Zaimplementuj niestandardowe zapytania KQL jako funkcje w celu pobrania danych z usługi Azure Monitor.
Przechowuj zapytania niestandardowe w repozytorium kodu, aby były importowane i stosowane automatycznie w ramach potoków ciągłej integracji/ciągłego dostarczania (CI/CD).
6 — Wizualizowanie stanu kondycji
Wykres zależności można wizualizować przy użyciu wyników kondycji z reprezentacją światła ruchu. Użyj narzędzi, takich jak pulpity nawigacyjne platformy Azure, skoroszyty monitora lub narzędzie Grafana. Oto przykład:
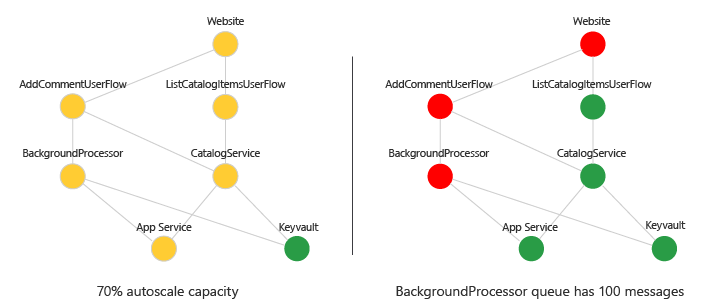
Sprawdzanie postępu: Wizualizacja
7 — Konfigurowanie alertów dotyczących zmian stanu
Pulpity nawigacyjne z alertami powinny być używane do natychmiastowego zwracania uwagi na problemy.
Jeśli stan kondycji składnika zmieni się na Obniżona lub Zła kondycja, operator powinien zostać natychmiast powiadomiony. Ustaw alerty w węźle głównym, ponieważ każda zmiana w tym węźle wskazuje stan złej kondycji w podstawowych przepływach lub zasobach użytkownika.
Sprawdzanie postępu: Alerty
Sprawdź swoją pracę
Obejrzyj ten pokaz na temat monitorowania i modelowania kondycji. Czy wszystkie aspekty zostały omówione w projekcie?
- Czy masz ujednolicony ujście danych do skorelowanej analizy?
- Czy uwzględniono dzienniki aplikacji, metryki platformy i punkty danych rozwiązania?
- Czy skonfigurowaliśmy pulpity nawigacyjne w celu wizualizacji stanu kondycji wszystkich składników?
- Czy rozważano punkty awarii w każdej usłudze (lub jej części), które mogłyby spowodować awarię lub uniemożliwić skalowanie, wdrażanie, monitorowanie?
- Czy rozważasz użycie pakietów zapytań do przechwytywania kluczowych zapytań, które mogłyby pomóc w szybszym klasyfikowaniu problemów?
- Czy interfejs API sprawdzania kondycji był przydatny w tym modelu? Czy musisz zmienić ten interfejs API, aby lepiej pasował do modelu kondycji?