Używanie rozwiązania AutoML w interfejsie użytkownika usługi Azure Databricks
Za pomocą graficznego interfejsu użytkownika w portalu usługi Azure Databricks można tworzyć eksperymenty rozwiązania AutoML i zarządzać nimi.
Konfigurowanie eksperymentu zautomatyzowanego uczenia maszynowego
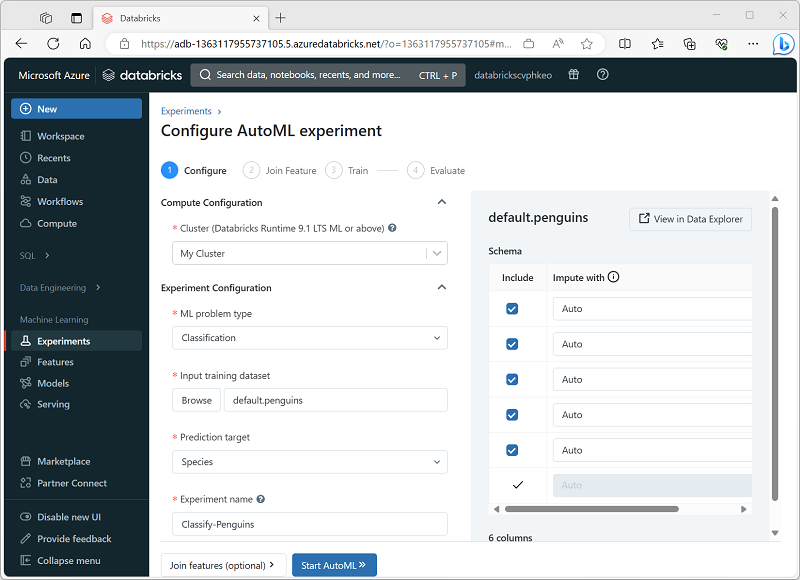
Aby skonfigurować eksperyment rozwiązania AutoML, należy określić ustawienia określonych wymagań dotyczących trenowania modelu, w tym:
- Klaster, na którym uruchamiasz eksperyment.
- Typ modelu uczenia maszynowego do wytrenowania (klastrowanie, regresja lub prognozowanie).
- Tabela zawierająca dane szkoleniowe.
- Pole etykiety docelowej do modelu musi przewidywać.
- Unikatowa nazwa eksperymentu automatycznego uczenia maszynowego (przebiegi podrzędne dla każdej wersji próbnej trenowania są unikatowo nazwane automatycznie).
- Metryka oceny, której chcesz użyć, aby określić model o najlepszej wydajności.
- Struktury szkoleniowe uczenia maszynowego, które chcesz wypróbować.
- Maksymalny czas eksperymentu.
- Wartość etykiety dodatniej (tylko dla klasyfikacji binarnej).
- Kolumna czasu (tylko dla modeli prognozowania).
- Gdzie zapisać wytrenowane modele (jako artefakty MLflow lub w magazynie DBFS).
Przeglądanie wyników rozwiązania AutoML
W miarę postępu eksperymentu zautomatyzowanego uczenia maszynowego jego przebiegi podrzędne są wyświetlane wraz z eksperymentem, który wyprodukował najlepszy model do tej pory.
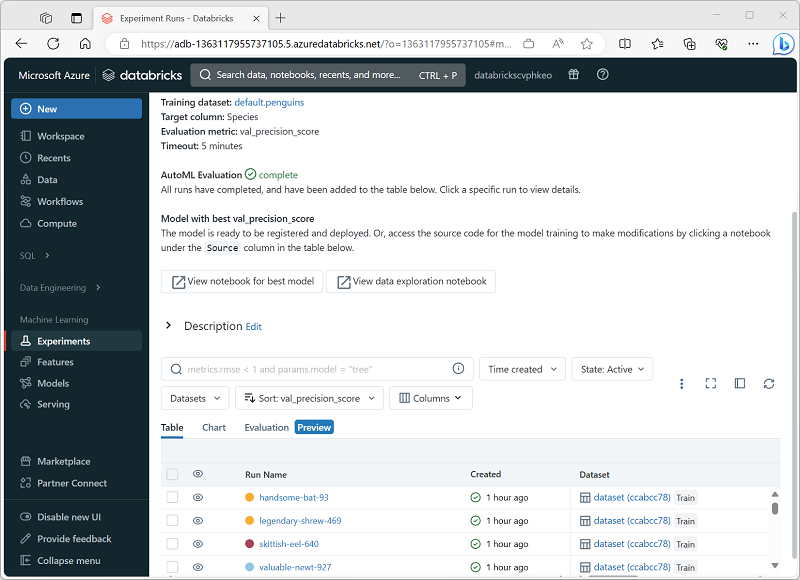
Możesz poczekać na zakończenie eksperymentu lub zapoznać się z modelami utworzonymi do tej pory i zatrzymać eksperyment, jeśli jest spełniony, że jeden z nich odpowiada Twoim potrzebom.
Możesz eksplorować poszczególne przebiegi, aby wyświetlić wygenerowany notes i metryki dla utworzonego modelu. Następnie możesz zarejestrować model i wdrożyć go na potrzeby wnioskowania.