Co to jest rozwiązanie AutoML?
AutoML to funkcja usługi Azure Databricks, która umożliwia automatyzowanie trenowania i oceny modelu uczenia maszynowego przy użyciu różnych kombinacji algorytmów i wartości hiperparametrów. Korzystając z rozwiązania AutoML, można zmniejszyć nakład pracy związany z procesem trenowania modelu iteracyjnego i szybciej utworzyć optymalny model dla danych.
Jak działa rozwiązanie AutoML?
Rozwiązanie AutoML działa przez generowanie wielu przebiegów eksperymentów, z których każdy trenuje model przy użyciu innego algorytmu i kombinacji hiperparametrów. W każdym przebiegu model jest trenowany i oceniany na podstawie danych i określonej metryki predykcyjnej. Usługa Azure Databricks śledzi przebiegi i modele, które tworzą przy użyciu platformy MLflow, umożliwiając identyfikowanie najlepszego modelu i wdrażanie go w środowisku produkcyjnym.
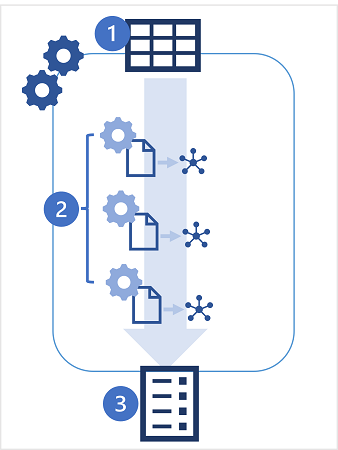
- Rozpoczniesz eksperyment rozwiązania AutoML, określając tabelę w obszarze roboczym usługi Azure Databricks jako źródło danych na potrzeby trenowania i metrykę wydajności, dla której chcesz zoptymalizować.
- Eksperyment automatycznego uczenia maszynowego generuje wiele przebiegów MLflow, z których każdy tworzy notes z kodem w celu wstępnego przetwarzania danych przed trenowaniem i walidacją modelu. Wytrenowane modele są zapisywane jako artefakty w uruchomieniu platformy MLflow lub plikach w magazynie systemu plików DBFS.
- Przebiegi eksperymentu są wymienione w kolejności wydajności, z najlepiej wydajnymi modelami wyświetlanymi jako pierwsze. Możesz eksplorować notesy, które zostały wygenerowane dla każdego przebiegu, wybrać model, którego chcesz użyć, a następnie zarejestrować i wdrożyć.
Napiwek
Aby uzyskać szczegółowe informacje na temat konkretnych przekształceń wstępnego przetwarzania i algorytmów trenowania używanych przez rozwiązanie AutoML, zobacz Jak działa rozwiązanie AutoML usługi Azure Databricks w dokumentacji usługi Azure Databricks.
Przygotowywanie danych do rozwiązania AutoML
Rozwiązanie AutoML wymaga źródła danych treningowych, które zawierają wartości cech i etykiet. Aby udostępnić te dane, utwórz tabelę w magazynie metadanych Hive w obszarze roboczym usługi Azure Databricks.
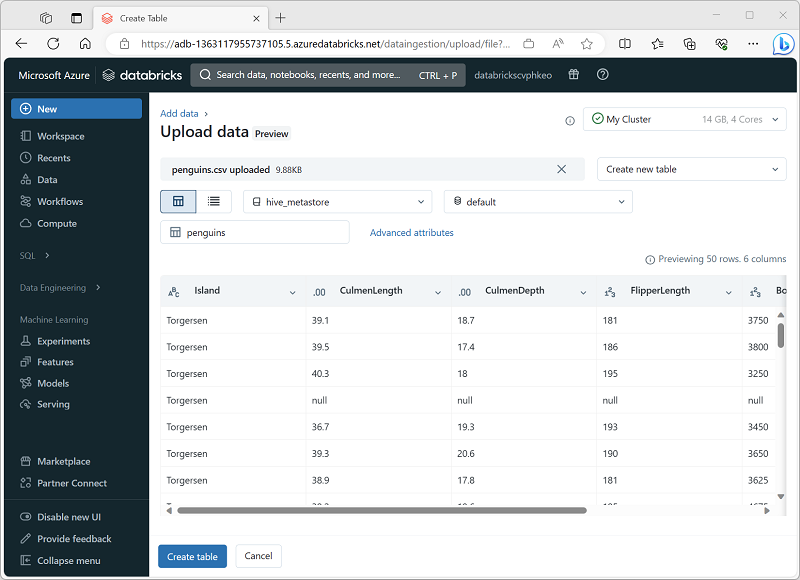
Prostym sposobem utworzenia tabeli danych szkoleniowych dla rozwiązania AutoML jest przekazanie pliku danych w portalu usługi Azure Databricks, jak pokazano tutaj.
Rozwiązanie AutoML generuje kod do obsługi typowych zadań przetwarzania wstępnego danych; takie jak kodowanie zmiennych kategorii, skalowanie zmiennych liczbowych, obsługa wartości null i radzenie sobie z niezrównoważonymi zestawami danych.