Omówienie analiza tekstu
Przed zapoznaniem się z możliwościami analizy tekstu w usłudze językowej Azure AI przyjrzyjmy się niektórym ogólnym zasadom i typowym technikom używanym do wykonywania analizy tekstu i innych zadań przetwarzania języka naturalnego (NLP).
Niektóre z najwcześniejszych technik używanych do analizowania tekstu przy użyciu komputerów obejmują analizę statystyczną treści tekstu ( korpusu) w celu wywnioskowania pewnego rodzaju znaczenia semantycznego. Mówiąc po prostu, jeśli możesz określić najczęściej używane słowa w danym dokumencie, często możesz uzyskać dobry pomysł na temat tego, co dotyczy dokumentu.
Tokenizacja
Pierwszym krokiem analizy korpusu jest podzielenie jej na tokeny. Ze względu na prostotę można traktować każde odrębne słowo w tekście treningowym jako token, choć w rzeczywistości tokeny mogą być generowane dla częściowych wyrazów lub kombinacji wyrazów i znaków interpunkcyjnych.
Rozważmy na przykład to wyrażenie ze słynnego przemówienia prezydenckiego w USA: "wybieramy, aby przejść na księżyc". Frazę można podzielić na następujące tokeny z identyfikatorami liczbowymi:
- my
- Wybierz
- na wartość
- go
- względem zasobu
- Księżyc
Zwróć uwagę, że "do" (numer tokenu 3) jest używany dwa razy w korpusie. Wyrażenie "wybieramy, aby przejść na księżyc" może być reprezentowane przez tokeny [1,2,3,4,3,5,6].
Uwaga
Użyliśmy prostego przykładu, w którym tokeny są identyfikowane dla każdego odrębnego słowa w tekście. Należy jednak wziąć pod uwagę następujące pojęcia, które mogą mieć zastosowanie do tokenizacji w zależności od konkretnego rodzaju problemu NLP, który próbujesz rozwiązać:
- Normalizacja tekstu: przed wygenerowaniem tokenów można wybrać normalizację tekstu przez usunięcie interpunkcji i zmianę wszystkich wyrazów na małe litery. W przypadku analizy, która opiera się wyłącznie na częstotliwości słów, to podejście zwiększa ogólną wydajność. Jednak niektóre semantycznie znaczenie może zostać utracone - na przykład rozważ zdanie "Pan Banks pracował w wielu bankach". Możesz chcieć, aby analiza rozróżniała osobę , w której pracował pan Banks i banki . Możesz również rozważyć "banki" jako oddzielny token dla "banków", ponieważ włączenie okresu zawiera informacje, że słowo pochodzi na końcu zdania
- Zatrzymaj usuwanie wyrazów. Słowa zatrzymane to wyrazy, które należy wykluczyć z analizy. Na przykład tekst "the", "a" lub "it" ułatwia użytkownikom odczytywanie tekstu, ale dodawanie niewielkiego znaczenia semantycznego. Wykluczając te słowa, rozwiązanie do analizy tekstu może być lepsze w stanie zidentyfikować ważne słowa.
- n-gramów są wieloterminowe frazy, takie jak "Mam" lub "chodził". Pojedyncza fraza wyrazu jest jednogramem, wyrażenie dwu wyrazowe to dwu gram, fraza trzy wyrazów jest trój gramem i tak dalej. Rozważając słowa jako grupy, model uczenia maszynowego może lepiej zrozumieć tekst.
- Stemming to technika, w której algorytmy są stosowane do konsolidowania wyrazów przed ich zliczeniem , tak aby słowa z tym samym elementem głównym, takie jak "moc", "zasilanie" i "potężne", były interpretowane jako ten sam token.
Analiza częstotliwości
Po tokenizowanie wyrazów można przeprowadzić analizę w celu zliczenia liczby wystąpień każdego tokenu. Najczęściej używane słowa (inne niż słowa zatrzymane, takie jak "a", "the" itd.) często mogą stanowić wskazówkę co do głównego tematu korpusu tekstu. Na przykład najbardziej typowe słowa w całym tekście mowy "przejdź na księżyc", które rozważaliśmy wcześniej, obejmują "new", "go", "space" i "moon". Jeśli mieliśmy tokenizować tekst jako dwugramów (pary słów), najczęstszym dwu gramem w mowie jest "księżyc". Z tych informacji można łatwo przypuszczać, że tekst jest przede wszystkim zaniepokojony podróżą kosmiczną i pójściem na Księżyc.
Napiwek
Prosta analiza częstotliwości, w której po prostu zliczasz liczbę wystąpień każdego tokenu, może być skutecznym sposobem analizowania pojedynczego dokumentu, ale gdy trzeba odróżnić wiele dokumentów w ramach tego samego korpusu, musisz określić, które tokeny są najbardziej istotne w każdym dokumencie. Częstotliwość terminów — częstotliwość odwrotności dokumentu (TF-IDF) to typowa technika, w której wynik jest obliczany na podstawie częstotliwości wyświetlania wyrazu lub terminu w jednym dokumencie w porównaniu z bardziej ogólną częstotliwością w całej kolekcji dokumentów. Przy użyciu tej techniki przyjmuje się wysoki stopień istotności słów, które pojawiają się często w konkretnym dokumencie, ale stosunkowo rzadko w szerokim zakresie innych dokumentów.
Uczenie maszynowe na potrzeby klasyfikacji tekstu
Inną przydatną techniką analizy tekstu jest użycie algorytmu klasyfikacji, takiego jak regresja logistyczna, w celu wytrenowania modelu uczenia maszynowego, który klasyfikuje tekst na podstawie znanego zestawu kategoryzacji. Typowym zastosowaniem tej techniki jest trenowanie modelu, który klasyfikuje tekst jako pozytywny lub negatywny w celu przeprowadzenia analizy tonacji lub wyszukiwania opinii.
Rozważmy na przykład następujące recenzje restauracji, które są już oznaczone jako 0 (ujemne) lub 1 (dodatnie):
- Jedzenie i obsługa były świetne: 1
- Naprawdę straszne doświadczenie: 0
- Mmm! smaczne jedzenie i zabawna atmosfera1.
- Powolna obsługa i żywność podrzędna: 0
Za pomocą wystarczającej liczby recenzji oznaczonych etykietami można wytrenować model klasyfikacji przy użyciu tokenizowanego tekstu jako funkcji i tonacji (0 lub 1) etykiety. Model będzie hermetyzować relację między tokenami i tonacją — na przykład recenzje z tokenami dla słów takich jak "great", "smaczne" lub "fun" są bardziej prawdopodobne, aby zwrócić tonację 1 (pozytywną), podczas gdy recenzje ze słowami takimi jak "straszne", "powolne" i "podstandard" są bardziej skłonne do zwrócenia 0 (ujemne).
Semantyczne modele językowe
Ponieważ stan sztuki nlp zaawansowane, możliwość trenowania modeli, które hermetyzują semantyczną relację między tokenami, doprowadziła do pojawienia się zaawansowanych modeli językowych. W centrum tych modeli jest kodowanie tokenów języka jako wektorów (tablic wielowartościowych liczb) znanych jako osadzanie.
Przydatne może być myślenie o elementach w wektorze osadzania tokenu jako współrzędnych w przestrzeni wielowymiarowej, dzięki czemu każdy token zajmuje określoną "lokalizację". Im bliżej tokeny są ze sobą powiązane, tym bardziej semantycznie powiązane są. Innymi słowy, powiązane słowa są grupowane bliżej siebie. W prostym przykładzie załóżmy, że osadzanie dla naszych tokenów składa się z wektorów z trzema elementami, na przykład:
- 4 ("pies"): [10.3.2]
- 5 ("kora"): [10,2,2]
- 8 ("cat"): [10,3,1]
- 9 ("meow"): [10,2,1]
- 10 ("deskorolka"): [3,3,1]
Możemy wykreślić lokalizację tokenów na podstawie tych wektorów w przestrzeni trójwymiarowej, w następujący sposób:
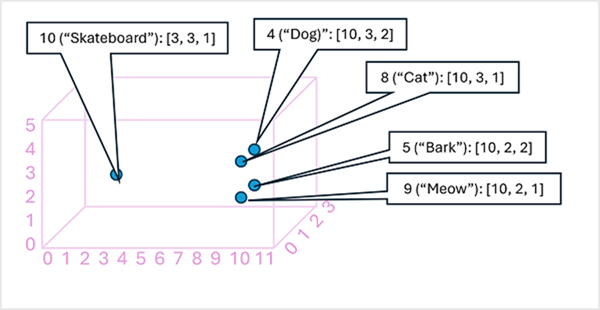
Lokalizacje tokenów w obszarze osadzania zawierają pewne informacje o tym, jak blisko tokeny są ze sobą powiązane. Na przykład token dla "psa" jest bliski "kot", a także "kora". Tokeny dla "kot" i "kora" są bliskie "meow". Token dla "deskorolki" jest dalej od innych tokenów.
Modele językowe używane w branży są oparte na tych zasadach, ale mają większą złożoność. Na przykład używane wektory zwykle mają o wiele więcej wymiarów. Istnieje również wiele sposobów obliczania odpowiednich osadzeń dla danego zestawu tokenów. Różne metody powodują różne przewidywania od modeli przetwarzania języka naturalnego.
Na poniższym diagramie przedstawiono uogólniony widok większości nowoczesnych rozwiązań przetwarzania języka naturalnego. Duży korpus nieprzetworzonego tekstu jest tokenizowany i używany do trenowania modeli językowych, które mogą obsługiwać wiele różnych typów zadań przetwarzania języka naturalnego.
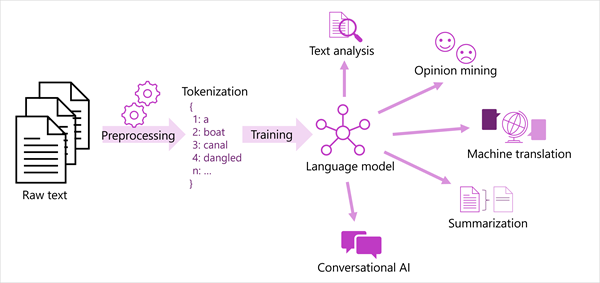
Typowe zadania NLP obsługiwane przez modele językowe obejmują:
- Analiza tekstu, taka jak wyodrębnianie kluczowych terminów lub identyfikowanie nazwanych jednostek w tekście.
- Analiza tonacji i wyszukiwanie opinii w celu kategoryzowania tekstu jako pozytywnego lub negatywnego.
- Tłumaczenie maszynowe, w którym tekst jest automatycznie tłumaczony z jednego języka na inny.
- Podsumowanie, w którym podsumowano główne elementy dużego tekstu.
- Konwersacyjne rozwiązania sztucznej inteligencji, takie jak boty lub asystenty cyfrowe, w których model językowy może interpretować dane wejściowe języka naturalnego i zwracać odpowiednią odpowiedź.
Te funkcje i inne funkcje są obsługiwane przez modele w usłudze językowej Azure AI, które omówimy w następnej kolejności.